Feeding Food
This is a draft (completed in October 2020) of a piece that was never published. I'm posting it here for anyone who might be interested. The food system is a massive and important topic, and here I've only scratched the surface of one small part of it. Researching and writing this shifted my thinking on many topics—I hope others will also get something from it.
Limit Break
Nowhere in the world do we see limitless growth. In agriculture, as in the broader natural world, there are nutritional limits that prevent plants and the life that depends on them from growing unbounded. Two limiting nutrients of special importance are nitrogen and phosphorus. Together these form a bottleneck for agricultural systems, with implications not only for food and other agricultural products but also for key features of a post-carbon world, such as bio-based alternatives to fossil fuels and their derivatives and afforestation.
Nitrogen is everywhere, making almost 80% of the air that surrounds us, which is why at first glance its role as a limiter might seem strange. Unlike carbon dioxide, the nitrogen in the air is inaccessible to plants. There are a variety of ways it can be made available to plants, such as through certain "nitrogen-fixing" bacteria or, much less commonly, lightning strikes, but something has to convert nitrogen into its inorganic form (e.g. ammonia) for plants to make use of it5354.
Phosphorus, more commonly a limiting factor in tropical areas55, is not as abundant as nitrogen, circulating through the gradual weathering of rocks.
Though many cultures found ways to better conserve soil nutrients and modestly supplement the nutritional content of soils through manures or legumes (which host nitrogen-fixing bacteria)56, it wasn't until the 19th century that a series of shifts occurred that effectively broke through these limits: the development of global fertilizer supply chains and the Haber-Bosch process for synthesizing nitrogen fertilizer at scale, named for Fritz Haber (sometimes called "the father of chemical warfare") who developed the process and Carl Bosch who later improved it. This process is still the basis for essentially all synthetic fertilizer production today. Nowadays the amount of reactive nitrogen and phosphorus circulating is more than double that of the pre-industrial world57585960.
These developments proliferated over the past century—use rates of nitrogen fertilizer increased over 40 times in the US over this period61—massively increasing global agricultural productivity, tripling agricultural value since 1970 to $2.6 trillion62. In the US synthetic fertilizer may be responsible for anywhere from 30 to 60% of yields, and even higher in the tropics6364. One of the most important consequences of the surpassing of these limits has been exponential population growth. Some 40% to half of the world population may owe their existence to the Haber-Bosch process54.
This massive nutritional increase comes at a substantial social and environmental cost and, at least in its current form, is unsustainable. The breaking of these nutrient limits is a major contributor to the breaking of planetary boundaries65: a recent paper estimated that almost 50% of global food production violates planetary boundaries, with almost of half to that (25% overall) due nitrogen fertilizer17.
Nitrogen fertilizers are typically applied in excess59; for cereal grain production only about a third of applied nitrogen is actually taken up the crop, amounting to \$90 billion of wasted nitrogen66, with some estimates ranging from half54 to 80%5767 being wasted across all crops. Similarly, estimates suggest only 15 to 30% of phosphorus is taken up686968. But a lot of this excess fertilizer leaches into water systems5465707172, causing eutrophication that has contributed to over 400 marine dead zones69. In the Gulf of Mexico such pollution from US agriculture costs the economy an estimated $1.4 billion annually by undermining fishing, recreation, and other marine activity7173. This overflow also contributes to the flourishing of pathogens like the West Nile virus74. Phosphorus fertilizers also contribute to heavy metal content in agriculture69, as much as 60% of cadmium in crops and soil757668, some of which also makes it to water sources76. In the US, agriculture is responsible for 70% of the total nitrogen and phosphorus pollution67.
This water pollution also has direct effects on human health, rendering drinking water toxic6961. Nitrate contamination is linked to many different diseases—blue baby syndrome, some cancers, and more. Violations of EPA limits of nitrate content in drinking water doubled from 650 in 1998 to 1,200 in 2008, while 2 million private wells are above the EPA-recommended standard74. This pollution is expensive to treat and the cost is usually borne by the public. The cost of a treatment facility can be hundreds of millions of dollars; the estimated cost for agriculture's share of the pollution is around \$1.7 billion annually74. The total cost of the environmental and health harm related to agricultural nitrogen in the US has been estimated at $157 billion per year74.
Nitrogen fertilizer overapplication also contributes to agricultural greenhouse gas emissions, especially N2O706654 which is now the main contributor to ozone depletion61. The amount of these emissions is estimated to increase exponentially with increased fertilizer usage77.
Other concerns regarding over-application—some also with any application of synthetic fertilizers—is their impact on soil health54, such as soil acidification2871 and net losses in soil nitrogen over time (meaning synthetic fertilizers' effectiveness decreases over time)6678. While disputed, some argue that synthetic fertilizer also inhibits soil's ability to sequester carbon64787980. What is more accepted is that more traditional techniques of maintaining soil fertility, which are often abandoned with the introduction of synthetic fertilizer28, improve carbon sequestration8182.
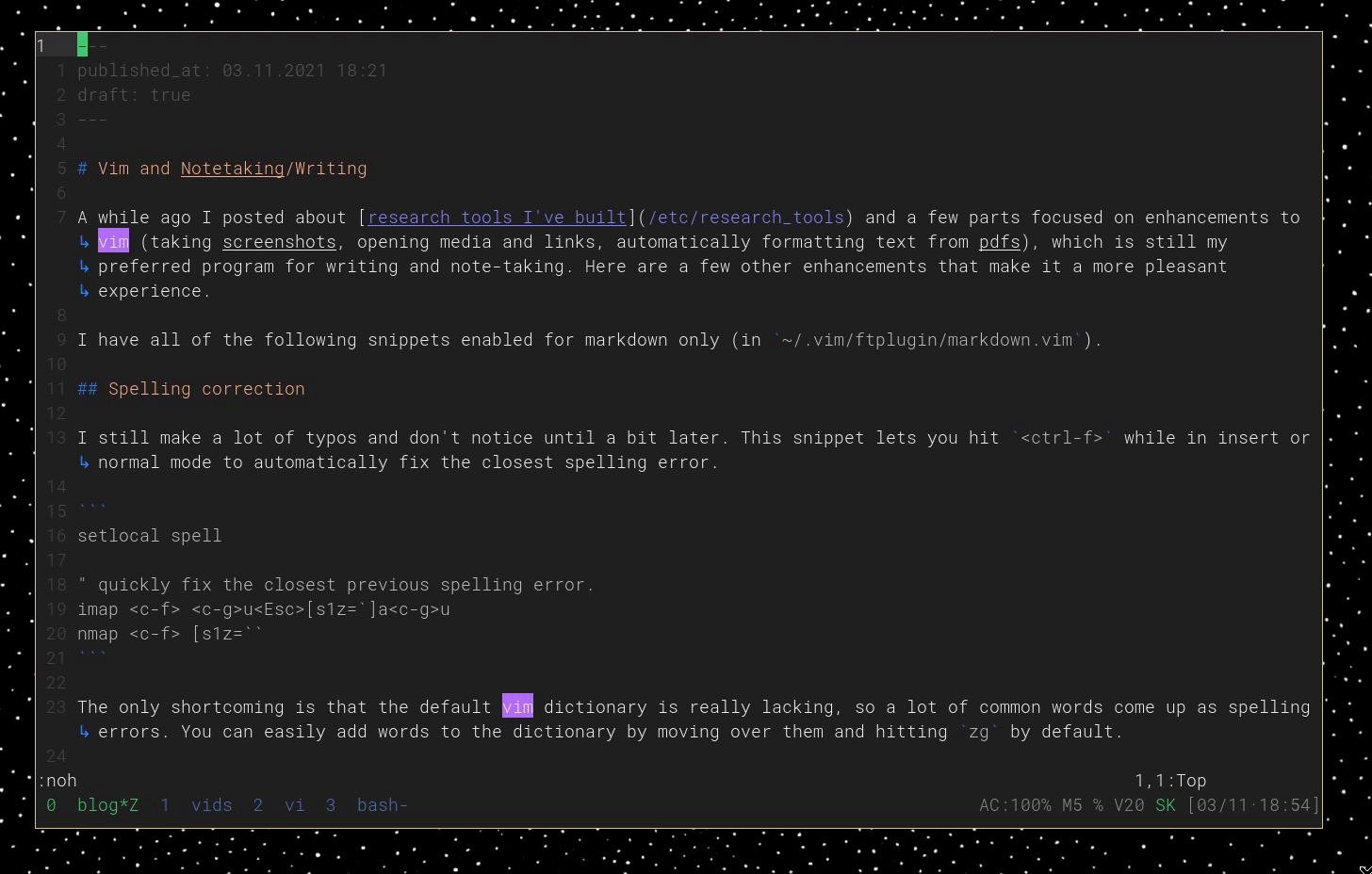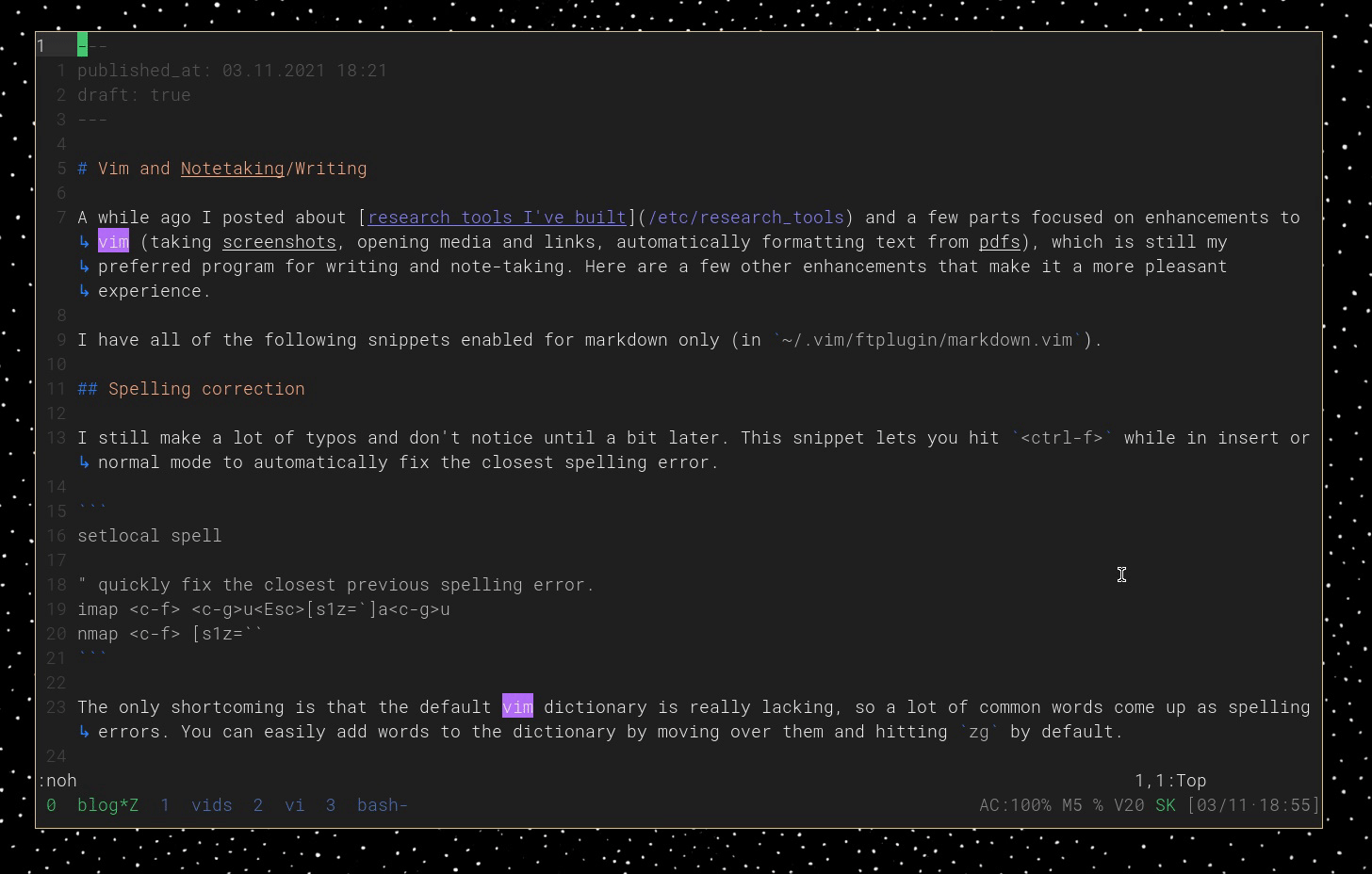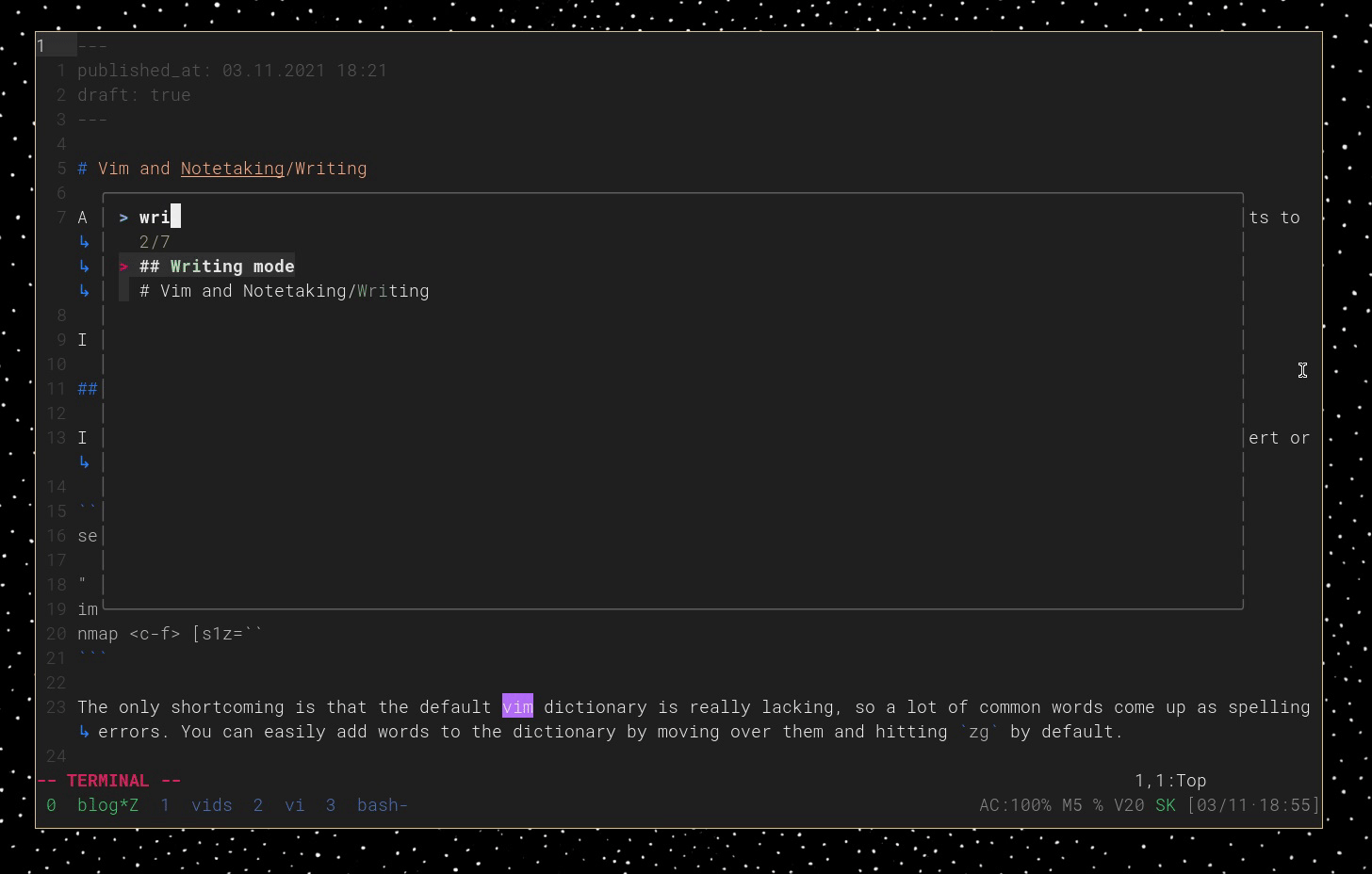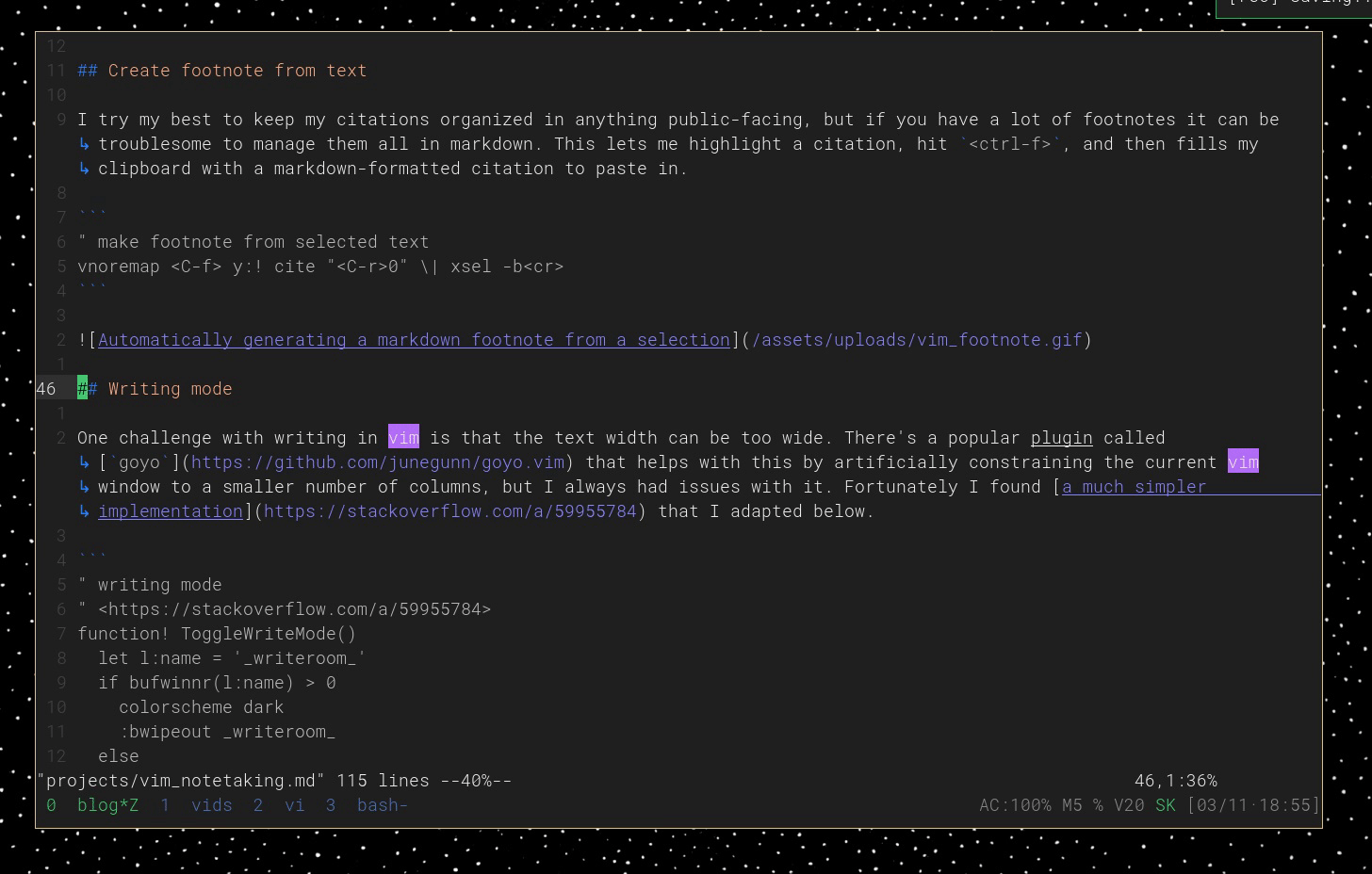
Of course, because the issue here is over-application—for example, China can use 30-50% less fertilizer and maintain the same yields and corn farmers in Minnesota reduced nitrogen use by 21% without a decrease in yield71—then the solution should be straightforward: use less of it. Recommendations to avoid fertilizer overapplication are generally about better management, more context-specific application (e.g. depending on what's already available in the soil and what the crop requires, carefully measuring out how much to apply)6028408371168485575474. This approach has been successful—in Denmark, for example, nitrogen fertilizer application decreased 52% since 1985 following the Nitrate Directive in 1987 which prescribes specific nitrogen management practices71. Similarly, a simple one fertilizer management program based on color charts successfully reduced fertilizer N use by about 25%57. The US has also seen improved nitrogen fertilizer efficiency through education initiatives59, but stronger regulation regarding synthetic fertilizer application is typically met with fierce resistance from farm lobbying groups61.
Other recommendations look a bit more deeply into why farmers over-apply fertilizer to begin with, especially around risk and incentives. Crop insurance appears to have some effect on fertilizer application rates, though there isn't consensus around their types and strength. One position argues that crop insurance programs encourage the planting of more input-intensive crops because they are better covered by the insurance, thus increasing fertilizer application; another argues that fertilizer over-application is a risk mitigation strategy (better to over-apply than under-apply and have a small harvest) that becomes redundant with crop insurance347274837186. Another position argues that crop insurance encourages agricultural expansion onto lands that are otherwise ill-suited for it—with greater environmental consequences—because crop insurance mitigates the risk of poor yields41. Some empirical studies have found that enrollment in crop insurance programs does increase the use of fertilizer3487 and water88 and does influence land use and crop choice (e.g. towards more nutrient-demanding crops)9, but others have found no effect or the opposite effect on fertilizer use8872.
In the case of the USDA, applications for assistance require that the applicant demonstrate genuine attempts to increase yields, which generally means applying fertilizers and adopting other conventional agriculture techniques. Such requirements are implemented out of concerns of gaming the system89. Because crop insurance is subsidized in the US, taxpayers essentially finance the consequent environmental destruction, while also suffering the consequences of water pollution, depletion of fish stocks, and more7489.
There are, however, environmental concerns beyond over-application, especially around the production of both nitrogen and phosphorus fertilizers.
Nitrogen fertilizer production—i.e. the Haber-Bosch process—is a large source of agriculture's environmental footprint82. The process requires a hydrocarbon source, usually natural gas, which is combined with nitrogen from the air90919216 and is also used to provide the required heat and energy. The natural gas is supposed to be used up by the process, such that methane emissions are minimal—but the actual emissions have been found to be over 145 times higher than reported93.
The production process also emits significant amounts of CO293; in 2011, this accounted for 25 million tons of greenhouse gases in the US, some 14% of the emissions for the entire chemical industry92. A huge chunk of agricultural emissions are actually attributable to fertilizer production due to these CO2 emissions - by one estimate, 30-33%92.
There are other problems from fertilizer production, such as pollution contributing to an estimated 4,300 premature deaths per year61 and substantial energy demands, accounting for an estimated third of total energy used in crop production16.
Phosphorus fertilizers have their own problems. The extraction and processing of the phosphate rock from which the fertilizer is produced come with the typical environmental issues of mining: water and air pollution, land degradation, erosion, toxic and occasionally radioactive byproducts (e.g. phosphogypsum)94952332966968. However, compared to the nitrogen fertilizer production process, phosphorus fertilizer requires a relatively modest amount of energy (about five times less than nitrogen fertilizer)16. Like nitrogen fertilizer, however, the process is dependent on the fossil fuel industry for inputs, namely sulfuric acid supplied as a byproduct from the oil and gas industry58. Both nitrogen and phosphorus fertilizer productions keep agriculture tightly linked to the fossil fuel industries we need to move beyond.
With phosphorus fertilizers one impending issue is phosphate rock's finite availability. No equivalent to the Haber-Bosch process exists for phosphorus fertilizer42, so it will continue to rely mostly on mined phosphate rock—about 96% of mined phosphate rock goes to fertilizer7010 and this accounts for about 60% of phosphorus applied to agriculture (the rest is from recycled sources like manure)1068.
As with other non-renewable resources, there are concerns around "peak phosphorus"451068. This is an inevitability given that it is a finite resource, but of course when this will occur is difficult to predict as anticipating actual reserves of any mineral is hard and estimates change frequently and by large amounts and according to economic and technological circumstances97451058. Estimates range from within a couple decades to hundreds of years684510.
At present the US is a major producer of phosphate rock, primarily in Florida, but that supply is expected to be 60% depleted by 2030 and completely gone mid-century45. China, another major producer, is expected to deplete in the near future as well10.
The Metabolic Rift
All of these issues of the present pour out of a deeper history of fertilizer that represents a more fundamental shift in our relationship with nature. This "metabolic rift" is the sundering of agriculture from its local ecological context98, and has at its core exploitation, colonialism, and imperialism2399100. The siphoning of fertility from the global periphery into Europe and its colonial descendants was foundational to pushing agricultural productivity beyond the limits of what the land could sustain.
Fertilizer itself was a common practice to maintain soil fertility while keeping it in production99 but it took the form of night soil, ashes, bones, and other organic waste that were relatively local, often connecting rural and urban populations through substantial logistics systems275468. But such methods could only maintain continuous productivity for so long; nutrient recycling is not perfect8254, and indeed soil depletion became an issue in industrializing nations as populations grew58. Alternative methods such as leaving land fallow or crop rotation did not fit the need for maximizing near-term productivity.
To resolve this dilemma, in the 19th century industrializing nations began sourcing fertilizer from distant places—mainly Peru, but also Chile, Ecuador, and Bolivia, in the form of guano and later nitrates996827100. This "Guano Age" saw a tremendous transfer of wealth to British business interests that essentially controlled this trade10027 as well as many deaths through horrendous slave-like working conditions of laborers from China and throughout Latin America2710199 and through multiple wars, including one following Spain's seizures of guano-rich islands100, a proxy war funded by the British so they could essentially annex Bolivian and Peruvian nitrate and guano producing regions10027, and a civil war in Chile also funded by the British to prevent Chile's nationalization of its fertilizer resources100 (Gregory Cushman's Guano and the opening of the Pacific world: a global ecological history provides a detailed look into this history).
Many Pacific Islands also saw their share of dispossession and violence. The US sought to secure its own guano deposits, passing the Guano Islands Act in 1856 to unilaterally allow US entrepreneurs to claim new guano islands as US territories27. Under this act 66 islands were claimed as US territory99, with at least 8 still under claim or in dispute. Other colonial powers followed suit, compelling a flurry of claims throughout the Pacific99 that devastated the islands unfortunate enough to be endowed with rich deposits. Two such islands, Banaba and Nauru, were key locations for the mining of phosphate rock. The Banabans, after years of violence and occupation, were eventually resettled after about 90% of their home island's surface was left mined and the trees they relied on for food essentially gone2210210399. Nauru didn't fare much better, with 80% of the surface left looking like a 'moonscape'104102. While Nauru achieved independence in 1968, they are left in a state of economic despair103.
The picture looks very different for the beneficiaries of this extractivism. The vast majority of the nutrient wealth extracted from these regions went to European and descendant countries such as the US, Australia, and New Zealand. European-style agriculture was unviable in Australia and New Zealand until imports of fertilizer derived from the Pacific islands turned each into exporters of meat and wool99103 . The fertilizer that resulted allowed the agricultural expansion that supported the industrial development of these countries27. Peru, like Nauru and Banaba, saw little benefit. With guano supplies basically depleted, Peru's farmers became dependent on different nutrient supply chains: imported synthetic fertilizers99.
For nitrogen fertilizer the most egregious cases of this imperialist exploitation came to an end with the Haber-Bosch process27, which as discussed above is not without its own significant problems and is still, with its reliance on fossil fuels, fundamentally extractivist. For other nutrients, especially phosphorus, this is not the case. While there Nauru and Banaba's phosphate resources are basically depleted, North Africa is still a site of phosphate mining to this day. In particular, the case of Morocco and Western Sahara shows a clear through-line from fertilizer's broader colonial history to its continuation in the present.
Under French control the region supplied phosphate for France's agriculture101. Morocco continues to be the leading exporter of phosphate with the largest reserves105, with estimates of up to 75%-85% of the world total reserves106426997 . Yet some of these reserves that are counted as Morocco's are not in fact in Morocco. They are in Western Sahara, what is sometimes called the "world's last colony"10739. Morocco has occupied Western Saharan since 197542107, with about 80% of the country under Moroccan rule108 under what is best described as a police state, with violence against and killings of activists, politically-motivated imprisonment, and other human rights violations4210911011110810739, with hundreds of Sahrawi "disappeared" and tortured by the Moroccan government10839. Most Sahrawi fled to Algeria, where they still mostly live in refugee camps4210810739.
This occupation is at least in part motivated by Western Sahara's phosphate reserves, which is of uniquely high quality107105. Some 10% of Moroccan phosphate income comes from the Bou Craa mine in Western Sahara42 and makes up most of the income Morocco gets from the region75 (fishing is another big source11210839). As of 2015, Morocco has made an estimated profits of $4.27 billion from Western Saharan phosphate rock mines69.
The UN and the International Court of Justice both recognize Western Sahara's right to self-determination10839, and no country officially recognizes the Moroccan occupation as legitimate75107105. Extraction of resources from an occupied territory is clear violation of international law107, which determines that the Sahrawi people should have "permanent sovereignty over [their] resources"39. Yet, over fifty years since this promise of self-determination, as countries continue to import Western Saharan exports10575, has not materialized in any meaningful way.
This is probably because several countries have a vested interest in Morocco. Morocco an important ally to US and the recipient of the most US foreign assistance in the region108107, including financial support and training for the Moroccan military and its operations against the Polisario Front108105, the Sahrawi nationalist movement. The US also helped plan the initial Moroccan invasion of Western Sahara; Kissinger feared communist activity in the area108105. Morocco has suggested using its phosphate production as a lever for protecting its claim to Western Sahara—to pressure Russia, for example75. In 1985, India recognized the independent Sahrawi state, the Sahrawi Arab Democratic Republic (SADR), but withdrew recognition in 2000 when they established a joint venture with the Morocco phosphate industry107.
Fertilizer production elsewhere also depends on phosphate exported from the area. 50% of the Bou Craa mine's output supplies fertilizer producers in North America, though in 2018 Canada-based Nutrien, the major North American importer, stopped accepting imports from the Bou Craa mine75. Other major importing countries are India, New Zealand, and China75. There have been some recent victories, however. In 2017, the Sahrawi Arab Democratic Republic successfully asserted a claim to a cargo of Bou Craa phosphate rock which was sold to New Zealand-based Ballance Agri-Nutrients75.
As phosphate rock supplies dwindle elsewhere, production from places like Morocco become even more important. Some projections say that Morocco's market share could increase to 80-90% by 20306910, effectively giving Morocco monopoly over the global phosphate market and a greater investment in maintaining control of Western Saharan deposits.
From all this it's clear that the current use of synthetic and non-renewable fertilizers is unsustainable. Yet at the start of the millennium Vaclav Smil concluded that we are fated, at least for the next century, to depend on Haber-Bosch54, and presumably the system of agriculture that is built on it. Have things changed in the intervening decades? Do we have better options now?
There are not many options for substituting phosphate rock (for phosphorus fertilizers the main approaches are using less or exploiting excess accumulated "legacy" phosphorus113), so the focus here will be on nitrogen fertilizers. The main options can be roughly grouped into two categories. There are those which move away from synthetic inputs towards more "natural" approaches, such as organic farming systems, and those which more or less stick to the industrial-chemical model but substitute Haber-Bosch for different processes. Both of these feature into utopian visions of future food systems.
Fertilizers By Other Names
Natural Factories? Organic Systems
As alluded to above, the major differentiator of agricultural systems' impacts is nutrient management and the nutrient bottleneck6511482115116549955. Organic systems forgo synthetic fertilizers and other synthetic chemical inputs (though there are circumstances where some may be allowed). Beyond that there can be quite a lot of variety among specific organic systems. More traditional techniques such as intercropping can be used, but aren't required for the organic label to apply114.
In lieu of synthetic fertilizers, other fertilizers like manure are used. These can be less consistent than synthetic fertilizers, as they can have a lot of variety in nutritional composition14 and also require additional microbial action before the nutrients are available to the plants (in synthetic fertilizers they're immediately available, for better or worse)16115. But, in addition to the lower environmental footprint, they have other advantages over synthetic fertilizers. Whereas synthetic fertilizers can lower the pest resistance of plants—thus requiring pesticides117118—organic fertilizers tend not to have this problem119120. They may also better contribute to soil carbon sequestration8165 and improve soil quality in other ways121.
The benefits of organic fertilizers are somewhat tempered when taking into account the impacts of collection and transportation. A farm using organic fertilizer produced on-site is going to require less energy than one that ships organic fertilizer from some distant elsewhere. The reduced nutritional density of organic fertilizers also means that transport energy expenditure on a nutritional basis can be higher as well. But in general because no energy-intensive production process is required, the energy requirements are still substantially less than synthetic fertilizers16.
The debate around the viability of wholesale replacement of conventional agriculture with organic systems inevitably ends up on the problem of the "yield gap"—that is, the difficulty organic systems have of matching the productivity of conventional systems.
Comparing organic and conventional agriculture systems is complicated. There are so many other context-specific factors that influence their relative performance, such as the particular crop, the growing environment, water availability, labor costs, and so on, and these factors may be related in zero-sum ways that by now are familiar: yield increases as N fertilizer use increases, but at cost of water pollution12212355. Comparisons may use a variety of crop specifically bred to maximize productivity under conventional systems, at the expense of traits which make them more productive under organic systems11482. Comparisons can be further complicated by histories of colonialism and displacement, where the highest-quality land is captured by large-scale operations that also happen to utilize industrial agriculture techniques, thus further contributing to higher yields. Larger gaps are found when cereal crops are compared, but this might be because Green Revolution technologies have focused on improving cereal yields in particular114. This is part of a larger trend: agricultural research largely focuses on techniques and technologies applicable in conventional systems, whereas organic and sustainable techniques are relatively underfunded58. The yield gap could be closed further with more research and funding.
One meta-analysis over several hundred agricultural systems—biased towards Western agricultural systems, including the most industrialized systems—concluded that organic systems fall short against conventional systems when compared on a yield basis; i.e. organic systems require more land, result in more eutrophication, and have similar greenhouse gas emissions per unit of food produced6582124. The yield gap ranged from a concerning 50% to a more modest ~90% of conventional output82114. Use of well-known techniques like cover cropping and intercropping can further close the gap6511414, but the gap could also widen under the effects of climate change124.
When this yield gap is taken into account, many of the environmental benefits of organic agriculture are severely reduced to the point where conventional agriculture looks more environmentally friendly. The difference is usually attributed to the fact that organic methods require much more land to achieve the same output124. Thus, for example, benefits in soil carbon sequestration are offset by the increase in deforestation from expansion of agricultural lands12565123. These comparisons, however, use life-cycle assessments (LCA) that are often biased towards the conventional conception of agriculture—that is, focused on agricultural outputs as products—failing to account for the very different conception from organic and other alternative forms that prioritize ecosystem health and have longer-term outlooks. For example, the effects of pesticides, though a key difference between organic and intensive systems, is often not considered126. Land degradation is also generally not included in these assessments126. On a long enough time scale the land degradation resulting from conventional agriculture undermines agricultural productivity (thus lowering these efficiency benefits from the LCA perspective)79. We might also consider that, though perhaps industrial agriculture theoretically has lower land use requirements, the political economy of industrial agriculture is such that it will expand regardless of this land-use efficiency. Organic agriculture, as co-opted by existing agribusiness, is not itself necessarily immune to this.
Such results by no means indicate that conventional agriculture is "sustainable" (especially considering its dependency on finite resources such as phosphate rock) or that it's "low-impact" (still requiring more energy than organic and with human health consequences from pesticides, water pollution, and so on)65. In any case, the prospect that industrial agriculture, which drives all the issues described above, is somehow better for the environment is a troubling if counterintuitive finding. Are there other newer approaches that resolve this dilemma? Ones that are both high-yielding and less harmful?
Take It Inside: Indoor Systems
One common proposal for improving agriculture—in terms of both yields and impacts—is to challenge its relationship to land. This set of agricultural systems fit neatly into narratives of high-tech progress, including hydroponics, aeroponics, aquaponics, and vertical farming. Hydroponics and aeroponics are two prevailing soil-less growing techniques, in which plants are grown out of water (in hydroponics and aquaponics) or nothing at all (aeroponics), and vertical farming can operate on either. These roughly all fall under the umbrella of indoor farming techniques (they don't need to be indoor, but they almost always are), which also encompasses more "traditional" greenhouse approaches, but has a more potent contemporary imaginary in the form of extremely high yield per acre operations on otherwise non-arable land, with tightly-controlled environments and factory-like efficiency (some of these methods are grouped under PFALs: "plant factories with artificial lighting"127 or just "plant factories" as artificial lighting is usually a given).
Within the -ponic techniques is substantial variety: the exact method can vary (hydroponic, for example, includes "deep water culture" and "nutrient film technique" among others), as can specifics of the configuration (though these techniques are usually associated with artificial lighting, they can also use sunlight), and growing environment (higher energy requirements, for example, in a colder climate)12865, and the specific crop grown, so generalizations can be a little tricky. But there is enough in common across these approaches that some comparisons are possible.
In terms of yields, hydroponic systems can have higher yields than conventional open-field systems367. In the context of urban agriculture, a substantial amount of a city's food demand can be met with local rooftop farms: for example an estimated 77% of Bologna's food demand is met in this way129. A recent study on urban horticulture in the UK (Sheffield) suggests that the expansion of rooftop farms could help meet a substantial amount of the city's fruit and vegetable needs130.
With respect to fertilizer's environmental impacts, these configurations feature closed water systems, meaning that water is used more effectively and recycled. This reduces both water usage and nutrient runoff and improves nutrient efficiency compared to conventional systems31311326713313425127. However, there is still potential for mismanagement and downstream pollution, as salt accumulation in the circulating nutrient solution still results in wastewater that must be properly disposed of128129.
A closed system can be more self-sustaining in other ways, such as using biomass waste to generate biogas to heat the greenhouse or using anaerobic digestion to produce fertilizer on-site128. Aquaponics generally avoids the use of synthetic fertilizers because fish waste provides nutrients13313567, though this does not necessarily mean a complete independence from synthetic fertilizers: fish feed is still an external input, and some setups may require nutritional supplements67.
Advocates of these systems claim they don't require pesticides, but indoor livestock farming was pitched on similar promises that haven't panned out136. Avoiding pesticide use is even more crucial when these farms are in cities129, so this claim warrants even more scrutiny than in other contexts.
These systems can have lower emissions1323, with most emissions coming from the facility structure (steel and concrete)132127, other fixed infrastructure (e.g. pipes)1343129132, and energy use25137, though this varies with energy mix. One way to reduce emissions and other impacts from the facility structure is to re-use existing buildings, though this comes with penalties as the buildings are not tailored specifically for indoor agriculture12925.
Perhaps one of the most lauded benefits is versatility in location—indoor methods don't require arable land137. Indeed, they can require substantially less land even when considering the land use for energy sources. One paper estimates 1:3 ratio of greenhouse area to solar panel area and assumes "a conversion efficiency of 14% and an average daily solar radiation value of 6.5 kWh per square meter per year"5. Using sunlight rather than artificial lighting is even better—one could imagine reclaiming the top floors of abandoned buildings to augment local food production.
From a financial perspective, these indoor systems tend to have high capital costs1371381331395. This includes not only equipment costs, but also the land itself, which in urban centers are expensive compared to rural land, and operating costs139—you pay for what is otherwise provided for free, e.g. sunlight. They tend to grow only leafy green and herbs for business model viability138136, especially because conventional agriculture can still produce the same food for much more cheaply.
Even though the arability of the farm site itself is less important, other geographical aspects still are. For example, where water is particularly expensive (e.g. in Egypt where deep wells must be dug and maintained133), the cost of starting an aquaponics farm is still quite expensive133. Of course, there are situations where the high cost may make sense if it's not possible to grow anything otherwise and other land uses don't make sense1395.
The climate of the site is another important factor. Hydroponics systems can have tremendously more energy requirements compared to conventional agriculture, varying a lot by climate (cooler climates require more heating, for example), which can be disproportionate to yield increases56514013412867. Lighting is the other big energy factor, but climate control is the cause for most of the variation between hydroponic systems25512913767. If the system is such that it has exposure to natural light (e.g. rooftop gardens), then the energy demand is of course further reduced.
In urban environments, these systems can have several additional benefits, depending on how tightly they're integrated with existing urban processes13712825127. The proximity to consumers can reduce impacts from packaging and transport129127, as well as minimizing food loss as well129137. Integration with rainwater harvesting systems can reduce draw on city water supplies12967, and wastewater systems can potentially be developed as nutrient solutions, rather than relying on synthetic fertilizers128. This could reduce the energy used in wastewater treatment, as the nutrients currently processed out to avoid eutrophication can be used to feed plants instead141.
But the fact that indoor methods don't require arable land is a little deceiving. Like conventional agriculture, arability still must be "imported" via inputs like synthetic fertilizers, so in some respects environmental impacts are merely dislocated from the site of production rather than altogether eliminated. Indoor methods are generally not designed to use organic fertilizers, as organic fertilizers are less consistent, less nutritionally dense, and often require some kind of microbial action to make the nutrients available to the plant (the exception here is aquaponics, which is designed around fish waste as fertilizer). For indoor systems, fertilizer production is still the major contributor to eutrophication1293132137. Even though less of this occurs at the site of use, plenty still occurs along the production and distribution chain.
So while these indoor approaches appear to have many benefits and may have a role to play in food production for a limited set of contexts140 (where energy costs are favorable, renewable energy sources are used, the high capital requirements are manageable, and to supplement the diets of land-scarce urban centers), but we shouldn't expect them to replace agriculture wholesale. And they do not necessarily lend themselves to socially-desirable models of production. One could imagine a near future in which insolvent smallholder farms on already marginal lands are displaced for investors to build towering vertical farms in their place.
With regards to fertilizer, they're still held back by many of the problems with synthetic fertilizers—especially their production. Are we stuck with the Haber-Bosch process? Is there a cleaner way of producing them?
Other Routes to Nitrogen
Though the Haber-Bosch process is the dominant way of producing nitrogen fertilizer, there are a variety of potential alternatives14230. These alternatives usually focus on Haber-Bosch's use of fossil feedstock and high energy requirements, stemming from its need for very high temperatures (300-500C) and pressures (200-300atm)37—"the single most energy-guzzling element of farming"143. These intense demands contrast to the microbes that fix nitrogen under far less extreme temperatures and pressures due to nitrogenase enzymes37.
Naturally, the promise of these nitrogenase enzymes has attracted research interest. One direction is focused on producing nitrogen fertilizer with solar power, at room temperature and normal pressure using these enzymes 143144, though at present the process is slower than the Haber-Bosch process24. There is also more recent research into methods using primarily water (for the hydrogen, that is normally supplied by fossil fuels in the Haber-Bosch process5837), air, and electricity ("primarily" because the process may require expensive metals like palladium as a catalyst145) to create small fertilizer synthesizing devices. Other "solar" fertilizers are similarly produced from water and air but use solar energy directly, rather than through electricity. These also tend to produce more dilute fertilizers that can help avoid overapplication146. This could take the form of relatively small, low-maintenance devices—"artificial leaves"147—that are amendable to decentralized production146 37. A decentralized model has several advantages, such as reducing transportation needs, which can make up a significant portion of fertilizer costs, especially for areas with poor infrastructure146. It may also offer an alternative to the existing capital-intensive, highly-concentrated world of fertilizer production, with its deeply entrenched interests and commitment to the Haber-Bosch status quo.
The American Farm Bureau Federation (AFBF), an agriculture industry lobbying group, is deeply committed to the fossil fuel-based method. The AFBF has a long history of working closely with the fossil fuel industry, supporting oil and gas domestic extraction (e.g. fracking), and even coal (which can be used as an input into fertilizer production91, and common in Chinese ammonia production92). This support has sometimes taken the form of outright climate change denial43. The Fertilizer Institute, a lobbying group for the fertilizer industry, is also closely connected to the fossil fuel industry, supporting expanded natural gas production, framing it explicitly as necessary for national food security and threatened by climate change policy148. This allegiance is likely only to grow stronger as pressure grows against the fossil fuel industry.
Questions of industry power aside, there is a lot of uncertainty about the viability of these alternative technologies2437145. A handful of companies cropped up a few years ago trying to produce net-zero emissions fertilizer by replacing Haber-Bosch fossil feedstocks with biomass and switching to renewable energy149, but none of the plants ever went through and the companies all went bankrupt150151. The available information seems to indicate mismanagement as a big contributor to these failures but it seems reasonable that the recent decline in natural gas prices—which has led to conventional nitrogen fertilizer production in the US to expand9293—is likely a large factor as well. The economics continue to favor fossil feedstocks.
Finally, changing the production process doesn't necessarily help address many of the other downstream effects of nitrogen fertilizer. What room is there then for innovating on fertilizer? Is there something with the productivity of synthetic fertilizer but with less of the harm?
"A Sewer is a Mistake"
A handful of social reformers lamented this partition, begging their fellow citizens to bridge the expanding chasm between city and farm. In his 1862 novel Les Misérables, Victor Hugo wrote, "There is no guano comparable in fertility with the detritus of a capital. A great city is the most mighty of dung-makers. Certain success would attend the experiment of employing the city to manure the plain. If our gold is manure, our manure, on the other hand, is gold."27
One option is to return to the older way of thinking: nutrients not as something to be produced but as something to be reused. The use of animal manure is a common example. If animal wastes can be used as fertilizer, then why not human waste too? 75 to 90% of nitrogen intake is excreted as urine54, which is also responsible for more than half of both the phosphorus and potassium in domestic wastewater (an estimated 16% of all mined phosphorus passes through the wastewater system) while constituting less than 1% of its volume152. In fact, recycling of human waste into fertilizer was once a key part of the agricultural nutrient cycle, until demand outpaced the recycled nutrients, more powerful fertilizers were introduced, and waste became seen as less of a resource and more of a problem (e.g. because of diseases) to be managed153154. Subsequent sanitation innovations responding to this conception of waste-as-problem such as flush toilets and more sophisticated sewage systems with the purpose of moving waste away from people also contributed to the disruption of these older "circular economies"68.
That such a system worked in the past means that we could try to restore it, and there is a renewed interest in recycling human waste into fertilizer155. Phosphorus can be recovered from wastewater through a variety of means, such as using sewage sludge, which has been used to generate high yields14. Or the nutrient-rich wastewater can be used directly as a medium to grow microalgae to treat the wastewater and harvest nitrogen and phosphorus to produce fertilizers156. We excrete almost all of the phosphorus we ingest68, and it can be recovered from wastewater69157. One study finds that some 40% of Australian phosphorus use can be fulfilled with a sewage recovery system96. The value of waste takes other forms too. Biochar is another soil amendment that can be produced from sewage sludge, which does not work well as a nitrogen fertilizer but can have other benefits such as increasing soil carbon sequestration and preventing nutrient leaching1581464158.
Unfortunately the valorization of wastewater for fertilizer is not without problems. The removal of nitrogen and phosphorus are both energy-intensive152 and the scalability of these systems are still uncertain68.
One key complication is waste contamination. Even in the past nightsoil required treatment to be safe54, and now we face a substantially more diverse set of chemicals, including pathogens, pharmaceuticals, cosmetics, and heavy metals from automotive and industrial runoff159115152. This is true even of animal wastes. Manure from concentrated animal feeding operations (CAFOs, i.e. "factory farms"), which, though massive in volume and thus an ample supply of nutrients, suffers from these problems of contamination160. This question of contamination has meant that these human waste-derived fertilizers aren't yet permitted for organic farms82. However, processes like vermicomposting, which uses earthworms to digest waste into more nutritious—potentially increasing some mineral concentration (phosphorus, for example) by up to 120% percent156, can reduce the content of some of these contaminants15914. However, the economics are again unfavorable: mining phosphate rock is cheaper than recovered phosphorus.
Reusing excreted nutrients rather than dumping them into the environment is a clear improvement to our current system, but the biggest limitation is that no nutrient recycling process will be able to recover all of the incoming nutrients. We couldn't rely on it alone: even a high-efficiency waste nutrient recycling system will still need to be supplemented.
Little Helpers: Biofertilizers
There is a class of fertilizers called "smart fertilizers" which usually refer to some slow-release mechanism so that nutrients are released more synchronously with plant uptake (i.e. released as plants need, instead of all at once). The mismatch of nutrient availability and plant need is a large factor in why fertilizer runoff and N2O emissions are as bad as they are; if plants used more of the nutrients then less would make it to waterways6447. This category encompasses a number of different methods, including organic wastes64, using slow-release casing, and biofertilizers.
Biofertilizers are fertilizers based on microbes; for example, nitrogen biofertilizers take advantage of existing nitrogen-fixing microorganisms such as cyanobacteria161162163164165. Like other fertilizers, they increase yields163164159166, and like the naturally-occurring instances of these microbes, biofertilizers may provide additional benefits such as pest protection161167163164168165, reduced soil erosion6165, additional growth beyond just that from the increased nutrient supply164159168165, and additional carbon sequestration165. The production process can involve fermentation (e.g. with yeast164168) or vermicomposting (i.e. the use of worms) from agricultural waste or wastewater16415914. These processes are accessible even in conditions of low capital (they are substantially cheaper than synthetic fertilizers169168) or without additional energy sources.
The use of such "plant probiotics"163 is not itself new163614170—for example, use of manures also introduces these microbes1646 and some are already commercialized on a small scale163. Environmental concerns around the Haber-Bosch process and other extractive fertilizer production processes, along with advances in biotechnology164, are drawing a renewed interest in commercializing the technology on a larger scale. There are however issues with scaling this to an industrial model: for example, transport and storage of living organisms is more complicated than relatively inert chemical fertilizers16116414.
However, again these biofertilizers are being developed within the context of the prevailing agrochemical industrial regime; companies like Bayer (who purchased Monsanto in 2018) and Nutrien (a $34-billion fertilizer company and second-largest producer of nitrogen fertilizer in the world171) are partnering with startups developing this biofertilizer technology, which is also focusing more on developing novel microbes rather than adapting existing ones167172.
The homemade biofertilizer Super Magro is one example of the more promising route biofertilizers could take. It consists of a simple, low-cost fermentation process and was released as an open source recipe for other farmers to use freely and augment169173.
What do we do?
Comparisons of these options are usually stated in terms of crop yield. Though some are still in development, these alternatives generally have yields that are worse than or only comparable to the prevailing synthetic fertilizer regime. There are cases where lower yields might be acceptable, such as with hydroponic urban agriculture where no food would be grown otherwise136. But in general, when viewed through crop yields, many analyses find these alternatives to be more environmentally damaging because of their lower yields.
Generally the emissions of agriculture are tied to yield17440; systems that are more intensive and produce higher yields end up having lower emissions per output. For example, organic systems have lower yield per hectare so they require more land to produce the same amount of food that an industrial farm would, which then leads to more deforestation and greater carbon emissions40. The worrying trade off between feeding people and reducing environmental impact seems to dissipate: industrial agriculture surprisingly gives us the best of both worlds. But this doesn't make any sense—we know that approach to agriculture has substantial harms.
This apparent paradox becomes resolvable by examining its key assumption: that feeding everyone necessarily requires absolutely maximizing agricultural productivity, which at present means widespread synthetic fertilizer use. This is the mainstream framing of the problem, advocated by organizations like the Bill and Melinda Gates Foundation175. That is, the core cause of inadequate nutrition and starvation is taken to be that we aren't growing enough food. Therefore we need powerful synthetic fertilizers to help us grow enough.
But are we really not growing enough food?
Food Waste
If we focus on food production we end up overlooking another important aspect: food waste. Consensus on exactly how much food is wasted is difficult because of lack of comprehensive data; estimates usually rely on surveys, looking through trash, or inferring through some other model. What is defined as food waste also varies. It can be simply the food that could have been eaten but is not (some definitions require that the food be eaten by a person, e.g. not a pet). or include food eaten in excess of nutritional requirements33176, or include that can no longer be sold, even if it still edible154, or still further be complicated by cultural differences, where food in one culinary tradition is considered waste in another154.
What is consistent across these definitions and data is that there is a lot of food wastage. Estimates of food waste range from 20% to 50%33177 (the wide variation is due to the differing definitions of food waste and outdated or lack of comprehensive data176), and appears to be growing19, even as agricultural output also grows178. In North America and Europe alone, where most of the waste occurs (twice as much as in Sub-Saharan Africa and South and Southeast Asia), this waste could "feed the world's hungry three times over"33.
Accounting for food waste dramatically increases the impact of each calorie of food consumed. Food waste accounts for as much as 38% of energy in the food system178; in the US this amounts to at least 2% of overall annual energy consumption179. This translates to a large amount of carbon emissions: in the UK, some 17 million tonnes CO2 emissions are attributable to food waste180; globally this figures to about 8 to 10% of GHG emissions (25-30% of food production's emissions)35. These impacts include not only the emissions from production, but also that food waste that ends up in landfill emits CO2 and methane19. For the UK, an estimated half of waste emissions comes from food waste33. Clearly if our concern is the environmental impact of food production, then food waste represents wasted harm. Reducing food waste not only reduces the impact per calorie from our existing food system, but makes a transition to a less harmful system more feasible in general because less overall output is required124.
Food waste is, on one end, usually framed as a technical problem for developing countries, and on the other, a behavioral one for developed countries. In developing countries, most food waste is attributed to lack of adequate technology and infrastructure. This might include poor transportation infrastructure that leads to food lost in transit, lack of well-sealed or cold storage leading to increased spoilage or infestation, crude harvesting equipment that leaves edible material behind33181154. In wealthier countries, more food waste occurs closer to the consumer18018117633, in part because improved production, storage, and distribution infrastructure reduces the share of waste at earlier points in the chain but also because higher incomes entail more wasteful habits182, such as an avoidance of "ugly" produce181183176182, excessive portion sizes181, and poor meal planning181176. Confusing, inconsistent, or outright arbitrary best-by/best-before/expiration date language is also an issue181184183, as are promotions encouraging larger purchases. There may also be legal obstacles preventing the distribution of excess food. The spatial organization of the global food system also drives waste: the more sprawled out a food system is, the farther food has to travel, which means more opportunities for food to be lost or spoiled along the way176.
With this understanding the policy recommendations are usually straightforward. For developing countries solutions focus on technology and infrastructure, which can be as simple as sealed storage drums176. Developed countries food waste policies focus around consumer education and behavior change18033181154 and removing hurdles to distributing surplus food35. For example, in France there is legislation from 2016 that fines groceries from throwing away food that's still good, which has resulted in more food donations and less food waste185. There are also community-based solidarity groups such as Food Not Bombs that try to ensure that food is being used to feed people.
But this analysis and its consequent policy solutions overlook how endemic these problems are to the political economy of food production—not just technical or behavioral problems—and how developing and developed food waste is deeply interconnected, where food waste is in fact structurally rational.
For example, consider the avoidance of "ugly" produce. It is not only consumer preference at point of purchase that leaves "ugly" produce behind but the decisions of retailers as well. For example, Walmart sets standards about carrot straightness and color, causing one supplier to discard as much as 30% of its carrots that do not meet these standards178. The EU used to have regulations specifying standards around the curvature of bananas154 among many other standards regarding other produce183. The cost of such standards are borne by smaller farmers, especially those in the Global South who have no influence over such decisions183 and often can't afford the more sophisticated harvesting technologies that reduce bruising176. In these cases the absence of demand leaves food to spoil154.
Yet, despite the narrative that producer waste is less of an issue in wealthier countries, similar dynamics are found. In California, for example, on average 24% of perfectly good food is left on fields unharvested4. Crop varieties, labor costs, and environmental factors all play a role, but so too do consumer preferences (leaving blemished food behind) and market prices—when prices are low, more may be left unharvested.4
Questions around food production really obscure two issues at play here: one is the question of whether or not we produce enough food to meet everyone's dietary needs, and another is whether or not that produced food is accessible to everyone. Looking more closely, our food production system blows past the first issue, and the problems of hunger and malnutrition have much less to do with sheer agricultural productivity and more to do with how food is production is governed and how food is distributed11412455186187. The need for the environmentally-damaging acceleration of agricultural output becomes murkier.
The Contradiction of Cheap Food
You could argue that productivity and access are actually closely linked. According to the laws of supply and demand, increasing productivity increases access because it will drive the prices of food down. The massive productivity increases in agriculture over the past century has seen an equally massive decrease in food prices, with many food commodities at 67-87% of their 1900 price182. It's hard to dispute that food prices are an important factor in food security; rising prices of food are not ever really thought of as a good sign precisely because it points to a decreased access to food.
With the hopes of avoiding high food prices and creating caloric abundance countries then would have an interest in developing agricultural productivity as much as possible, if not the farmers themselves. Yet then a crisis of overproduction occurs, in which a massive surplus of food does indeed drive prices down, but to the point where farmers are unable to recoup the costs of production.
A great deal of US agricultural policy over the past century is precisely about managing this overproduction. In the US, during downward prices and overproduction in the lead up to the Great Depression, the US had "breadlines knee-deep in wheat"49. The US government paid farmers leave land idle during the Great Depression to avoid overproduction and consequent price drops. Controversy around the policy in 1949—framed as paying farmers to not work—led to a different system establishing price floors, guaranteeing farmers a minimum price for their product, thus encouraging them to maximize use of their land188. This also meant that these downstream industries paid the farmers' incomes—and included conservation incentives which discouraged intensified exploitation of more and more land189. Some farmers support a return to these policies190191189, with a recognition that the drastically low prices contemporary subsidies enable also undermine the livelihoods of farmers in other countries—because cheap US exports set the price for other countries' agricultural products and enable a dependency on imports to the detriment of self-sufficient agriculture, which then allows agribusiness to buy up unused land to produce cash crops for export1192.
One of the consequences of overproduction is a squeeze where farmers can't recoup their costs of production. In the US, the 1970 price of corn was about $8 a bushel in today's dollars. Today it's about $4 a bushel. At the same time, the price of fertilizers have doubled193. Trends like this mean that, for many crops, prices have been below production costs for decades191. The subsidies which are meant to compensate for the lost income from these lower prices do not adequately fill the gap, with farm incomes—with subsidies included—seeing large declines191. US farm income has been decreasing8, down to 50% of 2013 income in 2018194. In Canada, farmer market net income—income after subtracting government payments, has been negative at least as of 2010195.
Debt has long played a big role in agriculture, helping to smooth out the staggered nature of farm expenditure and income—many expenses are upfront, but income isn't realized until after the harvest196. This difference is especially large in input-intensive agriculture, with the amount of chemicals used. A bad harvest can disrupt this cycle, leading to falling behind on loans and jeopardizing future access to capital196.
Against the backdrop of this price-cost squeeze, this debt can only accumulate. In the US, farm debt has been increasing since 2013194. At the same time the business of farm loans is expanding—the fertilizer company Nutrien expanded its farm loan program threefold to $6 billion197, further profiting off of a problem their expensive input regime created in the first place. Because incomes have been declining, farm loan delinquencies have hit a 9 year high198.
At the same time, these low prices, which are encouraged by subsidies and crop insurance guarantee an income to farmers, are to the benefit of downstream industries, such as livestock and snack/beverage/food processing companies, lowering the costs of their inputs. Effectively, taxpayers provide discounts for these businesses191, saving them some $3.9 billion per year199200190. With these low prices, the corn for a box of Kellog's Corn Flakes—which makes up 88% of the product—represents only 2.4% of the retail price51. These downstream companies—as well as the input companies, i.e. those that provide fertilizer, chemicals, seeds, machinery, etc—have seen record profits201 and provided massive payouts to shareholders:
As revealed in a recent report conducted by TUC and the High Pay Center on the behaviors of FTSE100 companies in the last 5 years, listed retailers paid over £2bn to shareholders in 2018, despite none of them being Living Wage Foundation accredited, while listed Food & drinks companies paid almost £14bn – more than they made in net profit (£12.7bn). To put that into perspective, just a tenth of this shareholder pay-out is enough to raise the wages of 1.9 million agriculture workers around the world to a living wage, for example those who produce food at the origin of the food chains that they coordinate as lead firms.20
In addition to cheaper inputs, overproduction gives these downstream companies more discretion over what they will and won't accept. For example, companies adopt stricter quality standards183 and retailers can return whatever they don't want or fails to sell in time, at no cost176, making farming even riskier than before.
For the farmer in this trap, there appear to only be a handful of options. One standard practice is to suppress the wages of farm workers, who are already among the most precarious group of workers. In the US, the H-2A visa system is used to keep wages low for migrant labor, to the point where a quarter to almost a third of such families are below the federal poverty line18202 and lowers wages for domestic farm labor as well203.
Another option is to expand markets for food. The problem with food is that it is relatively inelastic in demand; but one argument sees food waste against a backdrop of increasing food consumption in the US, with marketing that tries to enlarge the American appetite to offload an oversupply of cheap food19178. Farmers themselves do not typically have a role in this expansion; and most marketed food is in the form of snacks and processed foods of that nature; i.e. products of companies downstream from farming.
The other is to increase production. The low prices mean that productivity and volume is all the more important to make a living, which encourages environmentally harmful but output maximizing processes and the expansion of agricultural land18949. This only makes the problem worse—as farmers attempt to stay afloat by accelerating production, the markets for their crops end up flooded, further driving prices down.
The other is to overproduce to hedge against small harvests but withhold excess to keep prices high183. This is why we see for example perfectly good food left unharvested to rot. This behavior seems unreasonable—it is in many ways—but is rational, considering the farmer's position. When dealing with large retailers, the situation is such that if they fail to supply the agreed amount, they are dropped as a supplier176183, so the rational move is to overproduce just in case.
All of this is made easier to endure or even profit from with scale. The high costs of inputs and low prices of output are especially felt by smaller farms. We see this in US farming: almost 80% of small family farms' operating profit margin are in the "high risk level". In contrast, large-scale farms tend to be at a "low risk level"889. Larger farms gain better access to loans and better prices204. The current subsidy system exacerbates this, disproportionately benefiting larger farms who aren't struggling in the price-cost squeeze891887427205 and also tend to be more environmentally destructive79, even when accounting for the larger cropland8. Numbers range from 75-85% of farm subsidies going to only 10-15% of farms20686, and the 2018 Farm Bill has not really altered this dynamic207. The advantages of highly-capitalized, larger farms contributed to the consolidation of farming into fewer bigger farms204. In the US some 3 million farms went out of business in the postwar period208.
Even though dealing with agricultural overproduction has been a chronic problem of US agriculture, it came to have its usefulness in achieving US geopolitical goals. Harriet Friedmann192 and Philip McMichael187 outline a succession of "food regimes" where agricultural power is applied to capitalist expansion. Following World War II, the US instrumentalized its agricultural surplus by directing it towards contributing to European reconstruction and using food aid to slow the spread of communism78192187. Later, finding outlets for this surplus itself became a geopolitical goal. For example, developing markets for agricultural products through World Bank and IMF structural adjustment programs and WTO free-trade agreements in the Global South20978187210 . The development of such markets is itself partly accomplished by the surplus of US agricultural overproduction, which undermines local agriculture with low prices and disrupting food security. Rather than developing food self-sufficiency, the focus is on economic development to increase the affordability of imported food211192. In a strangely circular way, agriculture is no longer for growing food, but for growing commodities with which to buy food.
Part of these economic development programs is the consolidation of productive land and its re-orientation towards cash crops, further undermining food security212. This is the case in Zimbabwe, where the areas with the highest agricultural productivity also have the worst chronic malnutrition213. At the same time, the use of non-tariff barriers, such as sanitary and phytosanitary measures, effectively allow exporting nations to protect their own markets and make it so that only highly-capitalized operations can absorb the costs these additional measures require214.
Figures like Thomas Sankara saw how food aid was exploitative and that self-sufficiency the route that preserved autonomy:

However, major organizations like the UN's FAO, World Bank, and the IMF and foundations like the Gates Foundation continue to press that low productivity is the main problem with food security and thus synthetic fertilizer, high-yielding varieties, and other Green Revolution technologies need greater levels of adoption in developing countries 215216.
Fanning the Flames
Mexico
The Green Revolution was first coordinated as a development strategy in Mexico. David Barkin describes how these programs saw an increase in dependency on food imports21778, even though Mexico has all it needs for food self-sufficiency218. Even worse, the expansion of the agricultural industry is in parallel with decreasing food consumption. These programs of productivity increases are driven with a focus on increasing export-oriented crops, crops for markets, rather than for improving self-sufficiency218205. Achieving the maximum productivity of a land isn't possible without the capital required for the purchase of synthetic fertilizer, pesticides, high-yielding variety seeds, and so on. Poorer farmers are displaced by those with that necessary capital, instead needing to find off-farm work to buy the imported food27218204219205.
This process of undermining self-sufficiency has the consequence of creating new markets for countries to sell their food surpluses to, and facilitates the process of proletarianization, creating a pool of cheap labor218215. It also serves other geopolitical goals as well. Barkin quotes one American diplomat commenting on Micronesia, who plainly put it:
If we examine our effects on the island culture, we see they have a real case. Before the U. S. arrived, the natives were self-sufficient, they picked their food off the trees or fished. Now, since we have them hooked on consumer goods, they'd starve without a can opener. Some of the radical independence leaders want to reverse this and develop the old self-sufficiency. We can't blame them. However, we can't leave. We need our military bases there. We have no choice. As some of my friends in Washington say, you've got to grab them by the balls, their minds and hearts will follow 218
Viewed this way, the Green Revolution in Mexico has a continuity with the colonization of Latin America, in which colonists monopolized the most fertile land, away from their function of sustaining the local population and instead towards producing profitable crops for export. Those who used to farm those lands are marginalized—if they weren't outright killed—towards less productive lands with greater water scarcity215.
Sub-Saharan Africa
Sub-Saharan Africa (SSA) is constant target for Green Revolution development220. Food imports in SSA have increased for decades219, and part of this is blamed on low productivity due to low fertilizer usage22160 and high levels of soil degradation and erosion222. Fertilizer is especially expensive in SSA, in large part due to high transportation costs221 (some of this might be addressed by recent development of domestic production capacity223) ; farmers there can pay as much as five times as a farmer in Europe6968. Because of the overapplication of fertilizers elsewhere, and the accompanying environmental harm, some call for increasing fertilizer use in SSA with a corresponding or larger decrease elsewhere (for example, 588kg nitrogen fertilizer/ha/year in northern China vs 7kg in Kenya)224.
The soil degradation which supposedly necessitates synthetic fertilizer in SSA is often attributed to poor management, a form of development rhetoric that frames peasants as ignorant about how best to work their land215205212222216. More recent degradation looks to have more to do with climatic and biophysical factors222, but the farming of soil eroded lands has more to do with a process of marginalization—the original farmers had developed their methods of effective soil conservation222213—where larger landholders, European colonists, and transnational corporations monopolize the highest quality land and displace other farmers to smaller and smaller holdings, where the land has to be worked harder to meet the same needs205204213. In some cases, it is these transnational companies that overwork the soil, moving on to other fertile land once it's been exhausted205.
The increased adoption of synthetic fertilizers might only accelerate this soil degradation. One study looked at Zambia's input subsidy program and found that the introduction of fertilizer subsidy programs does in fact increase fertilizer usage, which subsequently leads to a reduction in traditional low- or no-input fertility-management methods such as fallowing and intercropping and an increase in continuous cropping—that is, a shift towards more intensive agriculture that disrupts natural cycles of soil restoration38225226. This shift in turn contributes to reduced levels of soil organic matter, which is important for maintaining soil health, which decreases the soil quality. Though there was a short-term boost in productivity, the resulting soil degradation could lead to a net decline in the long run which can only be delayed by further increasing the usage of expensive fertilizer225.
A review of eighty studies on fertilizer subsidies in Africa found that these subsidies are more likely to go to households with larger landholdings, greater wealth, and/or connections to the government, even if programs are ostensibly deliberately designed to avoid such outcomes224227. Fertilizer use stops once subsidies are withdrawn, so farmers are left with degraded soil and unable to afford the now necessary inputs to stabilize yields. Ultimately, productivity increases peter out after a few years, and there are only negligible effects on improving self-sufficiency, reducing import dependency, and alleviating poverty227.
These subsidies are expensive: African governments devote a large part of their budgets to these input subsidies, some $1 billion a year225220. For Zambia, as much as 35% of the country's agricultural budget was going towards fertilizer subsidies224. At one point, 9% of the Malawi's entire budget went to these subsidies212. This is more or less a transfer of public funds to fertilizer producers like Bayer/Monsanto212220.
As high as these subsidies are, they can't compete with those in wealthier countries. OECD countries provide subsidies to their own farmers of about $1 billion per day228, and such financial support encompassed 30% of all farm receipts from 2003-2005178.
This is compounded by the fact that Green Revolution technologies often come as a package. Specific varieties of crops are necessary to achieve the full yield improvements of synthetic fertilizer use (this varieties are usually intellectual property), and increased sensitivity to pests from fertilizer user necessitates the use of pesticides38119229. Higher productivity can also require more water, beyond what the water cycle normally provides, so irrigation also increases27.
In the case of Malawi, the suggested alternative to fertilizer subsidies is addressing underlying issues:
policies aimed at relieving the key constraints that our model tries to capture—such as land, credit and labor availability—might go further towards addressing the bottlenecks to on-farm intensification that smallholders in Malawi encounter, and could lead to the adoption of better on-farm practices that reverse soil degradation and improve the long-term viability of small-holder agriculture.226
Interestingly, many countries in SSA are agricultural exporters while being net food importers. That is, SSA's dependency on food imports is in part due to agricultural land and resources being directed for export-oriented production (in a form reminiscent of their colonial histories230) rather than supplying the country's food needs—"even a small substitution in their agricultural export products into food would eliminate their deficits"210.
This push towards agricultural production for export is in part driven by this need for income to purchase food imports and in part to manage national debts. The 1990s, Malawi, under the advisement of USAID and the tobacco industry, re-oriented production from food crops to tobacco crops with the goal of paying off its debt, with part of the rationale being that revenue from tobacco exports would be plenty to purchase the food needed to account for reduced production. The consequence, however, was that the ability for Malawian farmers to feed themselves was no longer dependent on their own agricultural ability, but rather on market prices for tobacco—which fell by 37% in 2009, and made it difficult for farmers to feed themselves212.
Sometimes this shift to export-oriented cash crops is further frustrated by the surpluses of major producers. Where some countries had advantages in producing things like sugar, the rise of processed foods meant fewer people were consuming sugar directly, instead mediated by processed foods—and as such, that opened up the possibility of sugar substitutes, i.e. HFCS, which then undermined countries with the comparative advantage for sugar production, as corn was overproduced and very cheap. Thus these countries were in a double-bind: food import dependency plus declining revenues from crop exports192.
These dynamics appear elsewhere too. In Nepal, though fertilizer subsidies do tend to increase crop yields, environmental problems are exacerbated231, and the subsidies may disproportionately benefit farmers who are more connected to the state and/or wealthier to begin with231221. In India, initial bumper crops from subsidized fertilizer application then gave way to crop failures and soil depletion38232, saw a move away from traditional techniques like crop rotation towards continuous cultivation of export-oriented crops38, and increased stratification between farmers who could afford the Green Revolution technologies and those who could not afford to stay on their land38205. Vandana Shiva describes deeper social shifts these technologies fomented:
The shift from internal to externally purchased inputs did not merely change ecological processes of agriculture. It also changed the structure of social and political relationships, from those based on mutual (though asymmetric) obligations—within the village to relations of each cultivator directly with banks, seed and fertilizer agencies, food procurement agencies, and electricity and irrigation organisations.38
Hand to Mouth
Content warning: There is some mention of suicide in this section.
This high-input and market-dependent form of agriculture puts farmers into a double-bind: they are both exposed to the impacts of fertilizer prices on their own production costs but also on the costs of their food1569. One study finds that increasing fertilizer prices would decrease crop yields by up to 13%7, reducing income.
In addition to the typical weather and climatic risks of agriculture, they are now exposed to the volatility of export restrictions, financial speculation, as well as the weather and climactic risks of wherever they import food from2334815! Risk has magnified, rather than diffused, through this system23415233212.
Arrangements such as contract farming integrate smaller farmers into global agricultural industrial supply chains through arrangements that ensure buyers (with substantially more market power, who do not need contribute to the costs of production, also ways around labor laws) bear little of this risk78212, much like the increasing use of contract workers throughout other industries.
Scalability becomes absolutely vital to generate enough revenue to remain solvent. Farmers with lower yields—i.e. subsistence farmers and those with less access to the capital necessary for scaling up—are the ones at the greatest risk19882235. Agricultural finance recognizes this, compounding the effect by giving larger farms cheaper loans, along with other advantages such as more opportunities to exploit cheap labor204. The trap is intensified due to the declining effectiveness of inputs, which have the effect of degrading the soil232. The general necessity of absolutely maximizing output for a piece of land encourages the extractivist model of agriculture, in which the soil is "mined", with nutrients pulled out faster than they can be naturally replaced78; sometimes even faster than they can be "unnaturally" replaced. In India, farmers require three times the fertilizer to achieve the same yields as they used to, while the prices for those crops remain the same or decline232. Insolvency is basically inevitable.
When farmers try to re-integrate traditional practices or develop systems parallel to conventional inputs, they are shut down. In Zimbabwe, farmers could not sell their own seeds as alternatives to the engineered hybrids—the practice was made illegal213.
What are the consequences of this precarity and lack of control over one's life? One may be an increase in farmer suicides21—farming is the profession most at-risk for suicide236. The farmers most likely to commit suicide are those who have marginal landholdings, focus on cash crops, and are indebted, which are exacerbated by all of the dynamics described above213821652.
Another consequence of this precarity is the increasing concentration of agricultural land and production.
Land Grabbing
Farmers, now unable to support themselves on the land, have no choice but to sell it. Agricultural land concentrates into fewer and fewer hands, contiguous with the dispossessions that occurred with colonization. Here, however, these dispossessions result from a mix of economic factors, driven by overproduction, and legal means, with post-colonial states, under the direction of development organizations like the US's Millennium Challenge Corporation, often facilitating the process by unilaterally replacing traditional land right systems with ones more amenable to foreign investment and ownership212218237.
More recently foreign acquisition of agricultural land, called "land grabs", have attracted a lot of attention. These acquisitions may be about food, water, and energy security238239240, just about expanding agribusiness amidst rising demand for biofuels and other cash crops239, and for financial speculation212241, faciliated by technologies that make their agricultural development easier to manage remotely as financial assets242. The countries where these land grabs are most common in recent years are Sub-Saharan Africa and South Asia243. In Ethiopia, some 10% of the country's agricultural land has been handed to foreign investors for commodity crops for export212. The World Bank and FAO has framed these as "win-win" opportunities for economic development13244 . In Sudan this export-oriented appropriation of land saw higher food prices, monopolized water usage, and resistance from the local population that was met with violence237.
Sometimes farmers aren't displaced but are actively involved in the investment process, seeking capital to stay afloat242. Otherwise farmers are displaced204237: for example, a British firm acquired 9,000 ha of land in Tanzania, potentially displacing over 11,000 people for biodiesel production245. The newly managed farms may be highly automated so that there isn't even much promise of any employment240, so these displaced people constitute a "surplus" population often relegated to slums204. Foreign workers are brought in to work the land with relatively little interaction with the local population243; the land is meant to operate, it seems, as a virtual extension of the country that owns it.
This is also occurring throughout the global North, where agricultural productivity tends to be higher and property rights are less risky for investors242, though the Food Security is National Security Act was introduced in 2017 to prevent foreign control of US agricultural land246. In the EU, millions of farms were lost over the past decades212. In the US, there is the original and ongoing dispossession of indigenous lands and subsequent and ongoing dispossession of black farmers' land24724189. US agriculture is already highly concentrated: some 3% of farms in the US are responsible for 50% of the value of all agricultural production5089.
Often this land remains idle. For example, biofuel production slowed when oil became cheap again, and it wasn't worth developing the land2.
Back to Biomass
Agricultural products encompass much more than just food; they are also produced as fuel, pharmaceuticals, bioplastics, and so on. Even within the category of "food" there are agricultural products for direct human consumption, those that are used as animal feed, and that used for food processing (e.g. snacks, beverages, oils). These categories are not clear cut either: corn may be grown for any of these, but corn itself is a heterogeneous crop and individual corn varieties are not necessarily fungible. Corn grown for animal feed, for instance, will be starchier than that grown for direct human consumption. Cane or beet sugar, though something we use in cooking directly, is more commonly an input into the snack and beverage industry (where it hasn't been out competed by corn-derived high fructose corn syrup). The same is true for other such "flex crops", which have a variety of possible end-uses.
The sustainability of food production and its ability to actually feed people then is deeply connected to these alternative uses of agricultural capacity. For example, expanded demand for biofuels may cause food prices to rise (30% of grain price increases during the 2007-2008 global price food spike is attributed to biofuel demand248) and encourage deforestation from agricultural expansion 24925015. Here food's market value dictates whether or not it's grown instead of potentially more profitable alternatives. But there are many things we can do to reduce the necessity of fuels; we cannot reduce our need for food to live.
Agroecology and Technology
What alternative is there to all of this? The commodification of food—seeing it as something to be produced and sold like factory goods—drives a lot of the dynamics described above. Agroecology that sees food not as something to be manufactured and agriculture not as a factory-like process but as a scaffolding for relationships and a source of autonomy.
Agroecology has some overlap with practices like organic and regenerative agriculture, at least in terms of focusing on environmentally-friendlier techniques, but where it differs is its commitment to social and economic issues outside of the specific production process (sometimes contrasted with a "input substitution" approach to agriculture208). An organic or a regenerative farm's efforts at sustainable or remediative production might be hampered by market demands, for example251. That's sort of reflective of organic agriculture's trajectory. As Julie Gutman describes in Agrarian Dreams: The Paradox of Organic Farming in California, organic agriculture originally encompassed more radical notions of food system change but was over time shaped to be focused on very specific aspects of the production process and integrated into the existing agribusiness industry252. Agroecology is not itself immune to this kind of co-optation, as a recent report on "junk agroecology" describes253.
Peter Rosset and Miguel Altieri outline agroecological production principles:
The production system must (1) reduce energy and resource use and regulate the overall energy input so that the output:input ratio is high; (2) reduce nutrient losses by effectively containing leaching, runoff, and erosion, and improve nutrient recycling through the use of legumes, organic manure and compost, and other effective recycling mechanisms; (3) encourage local production of food items adapted to the natural and socioeconomic setting; (4) sustain desired net output by preserving natural resources (by minimizing soil degradation); and (5) reduce costs and increase the efficiency and economic viability of small and medium-sized farms, thereby promoting a diverse, potentially resilient agricultural system.208
Actual techniques can encompass many things, such as re-integrating rural-urban nutrient cycles254, using natural fertilizers and nitrogen-fixing cover crops like legumes, soil-conserving and soil-building practices, ecologically-rooted pest management practices, and so on208. These have both environmental and economic benefits. For example: a system integrating perennial native prairie plants can reduce fertilizer use and runoff, saving more than $850 million per year in costs and damage74, and can increase yields by improving soil health, such as with the use of "fertilizer trees" as in parts of Africa (a practice called "evergreen agriculture")255256. These techniques can be used while considering their social and political effects. George Washington Carver, for example, advocated the use of legumes (such as peanuts) both as a way of maintaining soil health but also as part of a program for economic and political autonomy257. Agroecological soil management practices can improve fertility without needing to resort to subsidized inputs258, helping break the debt cycle. In general, these approaches have been found to improve crop yields while reducing inputs258.
The acroecology movement is led by peasants and peasant organizations like the Landless Workers Movement (MST), the Zapatista Army for National Liberation (ELZN), and La Via Campesina, with networks encompassing thousands and thousands of small producers across continents78259260. Peasants are a powerful force; despite centuries of dispossession, over half of the world's arable land is still under their ownership78, and, despite industrial agriculture's dominance in our food system, are major producers of food.
Smallholders (farmers with <2ha of land) produce about a third of the world food supply (measured as calories) on about a quarter of the agricultural area (close to half of the food supply if farms <5ha of land are included)261. What this implies is that smallholders already have productivity that out pace larger-scale operations, even on land that may be marginal. Further research and development of agroecological, low-input methods have the possibility to increase this number even more. However, funding tends to disappear for researchers developing these techniques228262. One example is that, following a $1.7 million donation to Iowa State University by the Koch Foundation (the Koch brothers own Koch Fertilizer), the university's Aldo Leopold Center for Sustainable Agriculture had its funding pulled after 30 years263. Despite this, agroecological innovation happens outside of formal research settings through peer-to-peer knowledge exchange and development. Unlike the agricultural input industry, which is top-down and where products are pushed onto farmers who have essentially no input in their design, agroecological techniques are often co-created by peasants and refined to their own specific contexts78.
Agroecology is sometimes characterized as a romanticization of labor-intensive subsistence farming264. A lot of labor-saving technologies basically work by substituting human labor with fossil fuels. If we look at the energy efficiency of these technologies, we see a different picture: about five times energy (fossil fuels, mostly) go into one kg of cereal in industrialized countries vs farmers in Africa, with more drastic differences on a crop-by-crop comparison, such as 33 times energy in the US to produce one kilo of maize as a traditional farmer in Mexico212. There are similar estimates for industrial food production more generally, 3kcal fossil fuel for 1kcal food19, with estimates as high as 7kcal for 1kcal178 or 10kcal229265. That the industrial-style of agriculture (input-heavy) is a net negative in terms of energy has been demonstrated since at least 1960s; which is characterized in terms of crops that are bred to maximize productivity in terms of the valuable parts of the crop (e.g. what is edible) at the expense of other functions, such as pest resistance, which are instead externalized to, for example, pesticides266.
Similarly, agroecological methods have been characterized as equivalent to traditional subsistence practices or the movement as anti-technology267. It may be more appropriate to say that it has a different understanding of technology, measuring it not only by how useful it is in the field, but by what impacts it has on relationships. Does it create a dependency on finite resources and empower large companies? Does it involve buying into a system of debt262? "Technology" is also often conflated with industrial, large-scale, and energy-intensive processes, but traditional labor-saving practices like coppicing268or the ongoing development of perennial grains269 can also be considered technologies of sorts. The previously mentioned fertilizer tree system is itself an outcome of research starting in the 1980's on nitrogen fertilization alternatives, conducted with the participation of farmers256, offering an example of productive agroecological research. The Out of the Woods collective also describe "cyborg ecology", where technology adoption should not be out of some binary commitment to a constructed purity around traditional techniques or modern technologies but out of evaluating what works without sacrificing ecological and social priorities259. The distributed production of solar fertilizers mentioned much earlier might fit this criteria.
Cuba is sometimes pointed to as an example of what agroecological practices could make possible on a larger scale. Cuban agriculture was once more akin to industrial, Green Revolution agriculture found elsewhere, supported by trade deals with the Soviet Union which supplied the necessary inputs: fossil fuels, fertilizers, machinery, etc.170260 When the Soviet Union collapsed, these inputs were suddenly unavailable, resulting in GDP and calorie consumption each plummeting by one-third27027123544186. Ongoing US blockades prevented dumping of cheap food into the Cuban market, further forcing Cuba to develop its own self-sufficiency in the absence of these inputs235.
Through this "Special Period", land reform redistributed over 1 million hectares of state-owned land to a variety of cooperatives and individuals27027117026044 (under usufruct terms, so most of the land is still state-owned186). Cuba went on to achieve the highest per capita food growth rates in Latin America260, facilitated by the land reform and the adoption and peer-to-peer transmission of agroecological techniques via peasant movements such as Campesino-a-Campesino26023517078—the latter of which was ongoing, but provided an opportunity to expand after the forced withdrawal of the industrial regime186. Over 65% of the country's food is produced by peasant family farms on 35% of the total arable land.186Cuban urban gardens, organopónicos, also a legacy of the post-Soviet "Special Period", produce as much as 70% of the fresh vegetables consumed in cities270271 and 50% of the produce for the entire country186. Lower levels of dissolved nitrogen in the island's rivers, compared to the US's Mississippi River Basin, is speculated to be a consequence of this shift in farming practices272.
This is not to say Cuban agriculture is fully agroecological—there are still conventional farms (usually state-run) and varying adoption of agroecological techniques186. There is still some dependency on oil for agriculture, though those who have adopted agroecology are more resilient to its absence, such as from US sanctions this past year273.
Cuba's food system still has other issues, such as with food waste, which is comparable to rates elsewhere, and generally attributed to infrastructural inadequacies rather than the overproduction and market-driven causes in the global north186. Yet this still results in inadequate food for many.
Pressure from agribusiness entering into Cuba274, especially with opening Cuba-US relations (for example: a Cargill-associated "US Agriculture Coalition for Cuba" seeks to "to lift the embargo in order to liberalize trade and investment and reestablish Cuba as a market for US products"186), and tensions within the country with some leaders advocating for higher-input/more conventional systems271. Changing relationships with the US may be the largest determinant of how Cuban agriculture changes in the future, with fears that it may become more focused on export for organic food markets and less on supplying domestic needs186.
Cuba's dependency on expensive food imports has also increased170 which has made expanded self-sufficiency a priority. Laws were passed in 2008 and 2012 to enact a further distribution of 1.7 million hectares of land to over 200,000 farmers, with roughly an additional 900,00 hectares up for distribution in 2017186. The impacts so far are unclear — the overall amount of food imports is contested, with one figure placing it at 40%186. Hurricanes increase Cuba's dependency on food imports, though the agroecological farms tend to recover more quickly than monoculture farms271186. Though Cuba's food system is not perfect, it shows that an agroecological system is worthwhile and achievable.
Conclusion: Healing the Rift
The focus here has been on food, but these issues will become more pressing as the economy—if we are to adequately address climate change—shifts back to one with greater dependence on biomass for materials. Consider that a tremendous amount of materials are petroleum-derived or otherwise produced from non-renewable resources254—including those that industrial agriculture rely on78. Switching to bioplastics, for instance, can have greater environmental impacts and greenhouse gas emissions than petroleum-based plastics due to land use change275.
Climate change will lead to an aggregate decrease in agricultural productivity27621262, increasing the number and scale of droughts and heatwaves29 and eroding and submerging productive land277. Food prices would rise and possibly encourage an influx of investors and speculation. We could see climate change and its effects on food production used to increase pressure of technocratic development authorities to act with a stronger mandate to implement Green Revolution-style programs and strengthen the narrative of peasants using land unproductively and as justification for land grabs. Climate change is already having an effect on displacing farmers239.
The key cause for these issues with conventional agriculture stem from the fact that it is not designed to fulfill a need—i.e. sustenance and nutrition, though it is often spoken as such in policy and popular discourse—but rather, it is designed to produce and sell commodities. There is a huge dissonance between the refrain of FAO population projections and the need to increase food production to feed them, when the current system of tremendous output fails to feed even the people we have now.
A report from Nature notes that, "[p]roducing enough food for the world's population in 2050 will be easy."228. The report goes on to note, the more urgent challenges are sustainable productivity and, more importantly, poverty—poverty that is itself produced by this productivist agricultural regime. As the authors note:
The 2008 food crisis, which pushed around 100 million people into hunger, was not so much a result of a food shortage as of a market volatility — with causes going far beyond supply and demand — that sent prices through the roof and sparked riots in several countries.228
A recent paper similarly suggests that almost 11 billion people can be adequately fed within planetary boundaries, but it requires a radical restructuring of global agriculture17.
One way to support this restructuring is to return wealth that has been extracted from these post-colonial nations and invest it in agricultural infrastructure that support greater food autonomy. It can mean increasing public research for agroecological methods and land reform, such as redistributing land back to those who have stewarded it for generations215. It requires moving on from the concept of food security—market access to food—to food sovereignty: producing food for need, prioritizing agroecological methods, local production and control212278178, and restoring more context-appropriate traditional crops where they have been displaced by commodity crops213.
The problems of fertilizer are inseparable from the broader political and economic problems of food production. Throughout history people have recognized how a community's control over their own means of living is a prerequisite for flourishing and self-determination. As Vann R. Newkirk II notes in his "The Great Land Robbery":
There’s a reason the fabled promise that spread among freedmen after the Civil War was not a check, a job, or a refundable tax credit, but 40 acres of farmland to call home.
-
A Report on the United Farmers and Rancher Congress. September 11, 1996. ↩
-
After Geoengineering: Climate Tragedy, Repair, and Restoration. Holly Jean Buck. ↩
-
Anton, A., Montero, J. I., Munoz, P., & Castells, F. (2005). LCA and tomato production in Mediterranean greenhouses. International Journal of Agricultural Resources, Governance and Ecology, 4(2), 102-112. ↩↩↩↩↩
-
Baker, G. A., Gray, L. C., Harwood, M. J., Osland, T. J., & Tooley, J. B. C. (2019). On-farm food loss in northern and central California: Results of field survey measurements. Resources, Conservation and Recycling, 149, 541-549. ↩↩
-
Barbosa, G., Gadelha, F., Kublik, N., Proctor, A., Reichelm, L., Weissinger, E., ... & Halden, R. (2015). Comparison of land, water, and energy requirements of lettuce grown using hydroponic vs. conventional agricultural methods. International journal of environmental research and public health, 12(6), 6879-6891. ↩↩↩↩↩
-
Biofertilizer. The Azolla Foundation. http://theazollafoundation.org/azollas-uses/as-a-biofertilizer/ ↩↩↩
-
Brunelle, T., Dumas, P., Souty, F., Dorin, B., & Nadaud, F. (2015). Evaluating the impact of rising fertilizer prices on crop yields. Agricultural economics, 46(5), 653-666. ↩
-
Burns, C., & MacDonald, J. M. (2018). America’s Diverse Family Farms: 2018 Edition. EIB-203, USDA-Economic Research Service. ↩↩↩↩
-
Claassen, R., Langpap, C., & Wu, J. (2016). Impacts of federal crop insurance on land use and environmental quality. American Journal of Agricultural Economics, 99(3), 592-613. ↩
-
Cooper, J., Lombardi, R., Boardman, D., & Carliell-Marquet, C. (2011). The future distribution and production of global phosphate rock reserves. Resources, Conservation and Recycling, 57, 78-86. ↩↩↩↩↩↩↩
-
Don't End Agricultural Subsidies, Fix Them. Mark Bittman. March 1, 2011. Retrieved from https://opinionator.blogs.nytimes.com/2011/03/01/dont-end-agricultural-subsidies-fix-them/ ↩
-
Fan, M. S., Zhao, F. J., Fairweather-Tait, S. J., Poulton, P. R., Dunham, S. J., & McGrath, S. P. (2008). Evidence of decreasing mineral density in wheat grain over the last 160 years. Journal of Trace Elements in Medicine and Biology, 22(4), 315-324. ↩
-
FAO Economic and Social Development Department, 2009. "From Land Grab to Win-Win - Seizing the Opportunities of International Investments in Agriculture," FAO - Economic and Social Perspectives 4EN, Economic and Social Development Department of the Food and Agriculture Organization of the United Nations (FAO). ↩
-
Flores-Félix, J. D., Menéndez, E., Rivas, R., & de la Encarnación Velázquez, M. (2019). Future Perspective in Organic Farming Fertilization: Management and Product. In Organic Farming (pp. 269-315). Woodhead Publishing. ↩↩↩↩↩↩↩↩
-
Food Price Volatility and Insecurity. Toni Johnson. January 16, 2013. Retrieved from https://www.cfr.org/backgrounder/food-price-volatility-and-insecurity ↩↩↩↩
-
Gellings, C. W., & Parmenter, K. E. (2016). Energy efficiency in fertilizer production and use. Efficient Use and Conservation of Energy; Gellings, CW, Ed.; Encyclopedia of Life Support Systems, 123-136. ↩↩↩↩↩↩
-
Gerten, D., Heck, V., Jägermeyr, J., Bodirsky, B. L., Fetzer, I., Jalava, M., ... & Schellnhuber, H. J. (2020). Feeding ten billion people is possible within four terrestrial planetary boundaries. Nature Sustainability, 1-9. ↩↩
-
Growers Sue to Roll Back Farm Workers’ Wages. David Bacon. January 25, 2019. Retrieved from https://prospect.org/labor/growers-sue-roll-back-farm-workers-wages/ ↩
-
Hall, K. D., Guo, J., Dore, M., & Chow, C. C. (2009). The progressive increase of food waste in America and its environmental impact. PloS one, 4(11), e7940. ↩↩↩↩
-
How Finance Structures Global Value Chains. Tomaso Ferrando. January 6, 2020. Retrieved from https://lpeblog.org/2020/01/06/how-finance-structures-global-value-chains/#more-3156 ↩
-
Kennedy, J., & King, L. (2014). The political economy of farmers’ suicides in India: indebted cash-crop farmers with marginal landholdings explain state-level variation in suicide rates. Globalization and health, 10(1), 16. ↩↩↩
-
King, S., & Sigrah, K. R. (2004, November). Legacy of a miner's daughter and assessment of the social changes of the Banabans after phosphate mining on Banaba. In Changing Islands–Changing Worlds. Islands of the World VIII International Conference. Taiwan. ↩
-
Langa, S. G. (2014). Potash extraction and historical environmental conflict in the Bages region (Spain). Investigaciones Geográficas (Esp), (61), 5-16. ↩↩
-
Light sparks conversion of dinitrogen to ammonia. Stu Borman. April 22, 2016. https://cen.acs.org/articles/94/i17/Light-sparks-conversion-dinitrogen-ammonia.html ↩↩
-
Martin, M., & Molin, E. (2019). Environmental Assessment of an Urban Vertical Hydroponic Farming System in Sweden. Sustainability, 11(15), 4124. ↩↩↩↩↩
-
Mason, N. M., Jayne, T. S., & Van De Walle, N. (2017). The political economy of fertilizer subsidy programs in Africa: Evidence from Zambia. American Journal of Agricultural Economics, 99(3), 705-731. ↩
-
Melillo, E. D. (2012). The first green revolution: debt peonage and the making of the nitrogen fertilizer trade, 1840–1930. The American Historical Review, 117(4), 1028-1060. ↩↩↩↩↩↩↩↩↩↩↩↩
-
Miao, Y., Stewart, B. A., & Zhang, F. (2011). Long-term experiments for sustainable nutrient management in China. A review. Agronomy for Sustainable Development, 31(2), 397-414. ↩↩↩
-
Newly Identified Jet-Stream Pattern Could Imperil Global Food Supplies. Jeff Masters. December 9, 2019. Retrieved from https://blogs.scientificamerican.com/eye-of-the-storm/newly-identified-jet-stream-pattern-could-imperil-global-food-supplies/ ↩
-
Nitrogen Production Technologies. Retrieved from https://wcroc.cfans.umn.edu/research-programs/renewable-energy/energy-crops/nitrogen-production ↩
-
On Farming YouTube, Emu Eggs and Hay Bales Find Loyal Fans. Louise Matsakis. December 18, 2019. Retrieved from https://www.wired.com/story/farming-youtube-emu-eggs-hay-bales-find-fans/ ↩
-
Othman, I., & Al-Masri, M. S. (2007). Impact of phosphate industry on the environment: a case study. Applied Radiation and Isotopes, 65(1), 131-141. ↩
-
Papargyropoulou, E., Lozano, R., Steinberger, J. K., Wright, N., & bin Ujang, Z. (2014). The food waste hierarchy as a framework for the management of food surplus and food waste. Journal of Cleaner Production, 76, 106-115. ↩↩↩↩↩↩↩
-
Regmi, M., Briggeman, B., & Featherstone, A. (2019). Estimating Effects of Crop Insurance Enrollment on Farm Input Use. ↩↩
-
Rosenzweig, C., Mbow, C., Barioni, L. G., Benton, T. G., Herrero, M., Krishnapillai, M., ... & Tubiello, F. N. (2020). Climate change responses benefit from a global food system approach. Nature Food, 1(2), 94-97. ↩↩
-
Rougoor, C. W., Van Zeijts, H., Hofreither, M. F., & Bäckman, S. (2001). Experiences with fertilizer taxes in Europe. Journal of Environmental Planning and Management, 44(6), 877-887. ↩
-
Shipman, M. A., & Symes, M. D. (2017). Recent progress towards the electrosynthesis of ammonia from sustainable resources. Catalysis Today, 286, 57-68. ↩↩↩↩↩
-
Shiva, V. (1991). The violence of the green revolution: Third World agriculture, ecology and politics. ↩↩↩↩↩↩↩
-
Smith, L. E. (2005). The struggle for Western Sahara: What future for Africa's last colony?. The Journal of North African Studies, 10(3-4), 545-563. ↩↩↩↩↩↩↩
-
Snyder, C. S., Bruulsema, T. W., Jensen, T. L., & Fixen, P. E. (2009). Review of greenhouse gas emissions from crop production systems and fertilizer management effects. Agriculture, Ecosystems & Environment, 133(3-4), 247-266. ↩↩↩
-
Sumner, D. A., & Zulauf, C. R. (2012). Economic and environmental effects of agricultural insurance programs (No. 643-2016-44463). ↩
-
The Desert Rock That Feeds the World. Alex Kasprak. November 29, 2016. https://www.theatlantic.com/science/archive/2016/11/the-desert-rock-that-feeds-the-world/508853/ ↩↩↩↩↩↩
-
The Farm Bureau: Big Oil’s Unnoticed Ally Fighting Climate Science and Policy. Neela Banerjee, Georgina Gustin, John H. Cushman Jr. December 21, 2018. Retrieved from https://insideclimatenews.org/news/20122018/american-farm-bureau-fossil-fuel-nexus-climate-change-denial-science-agriculture-carbon-policy-opposition. ↩
-
Uriarte, M. (2002). Cuba, social policy at a crossroads: Maintaining priorities, transforming practice. ↩↩
-
Van Kauwenbergh, S. J. (2010). World phosphate rock reserves and resources (p. 48). Muscle Shoals: IFDC. ↩↩↩↩
-
Vietnam’s Low-tech Food System Takes Advantage of Decay. Aaron Vansintjan. February 23, 2017. https://www.resilience.org/stories/2017-02-23/vietnams-low-tech-food-system-takes-advantage-of-decay/ ↩
-
Vishwakarma, K., Upadhyay, N., Kumar, N., Tripathi, D. K., Chauhan, D. K., Sharma, S., & Sahi, S. (2018). Potential Applications and Avenues of Nanotechnology in Sustainable Agriculture. In Nanomaterials in Plants, Algae, and Microorganisms (pp. 473-500). Academic Press. ↩
-
von Braun, J., & Tadesse, G. (2012). Global food price volatility and spikes: an overview of costs, causes, and solutions. ZEF-Discussion Papers on Development Policy, (161). ↩
-
What is parity? (And why you should care). Eric Holt-Giménez, Heidi Kleiner. May 20, 2019. Retrieved from https://foodfirst.org/what-is-parity-and-why-you-should-care/ ↩↩
-
Large-scale family farms represent 2.8% of farms, but encompass 39.0% of the value of production. Large-scale family farms are defined as those with $1 million or more in gross cash farm income (GCFI) ("a measure of the farm's revenue that includes sales of crops and livestock, government payments, and other farm-related income, including fees from production contracts"). This includes farms with with a GCFI of $5 million or more (0.3% of all US farms). 2% of farms (and 13% of production) are "nonfamily farms" which include "partnerships of unrelated partners, closely held nonfamily corporations, farms with a hired operator unrelated to the owners, and (relatively few) publicly held corporations.". 15% of these nonfamily farms (0.3% of all farms) have a GCFI of $1 million or more and account for 89% of the nonfamily farm production (so 11.6% of total production). So altogether, farms with a GCFI of $1 million or more account for 11.6+39=50.6% of the value of all production while representing only 2.8+0.3=3.1% of all farms.8 ↩
-
At the time of writing (November 28, 2019), the price of corn is about $3.63/bushel, and an 18oz box of corn flakes is $3.28 at Walmart. In the ingredients list for corn flakes, milled corn is listed as the first ingredient, followed by sugar; there are 4g of added sugar per serving size and 12 servings in an 18oz box, so 48g (1.7oz) added sugar total, so we can assume the corn contents are closer to
18 - 1.7 = 16.3oz. One bushel of corn is 56lbs or 896oz.16.3/896 * 3.63means a 18oz box of corn flakes has about 6.6c of corn in it. The price of sugar is today is $0.13/lb, so 1.7oz of sugar costs 1.4c. The main ingredients then cost 8 cents, representing 2.4% of the retail price (there is intermediary processing, i.e. corn milling, but safe to say this does not introduce enough of a price increase to explain the remaining retail price). ↩ -
There is some dispute over the relationship between farmer suicides and the dynamics described here, but these tend to ignore that many farmers, when struggling with income, take on other work and thus may not be categorized as farmers in data21. Similarly, that the most common stated reasons for suicide are not economic, but personal or family related, neglects that economic problems may manifest as these other types of problems236. It fails to examine the relational aspects that might be driving suicides—if someone is dependent on someone who farms for the primary income, but may do other work (this might be true for the "housewives" category, who fall under the "non-working population" definition by the Census of India), their suicide may relate to agriculture work even if they themselves do not fall under that category. Even for those instances where agrarian suicide is not directly attributed to financial reasons (e.g. alcoholism), that still may be the indirect cause. ↩
-
The Mysteries of Fertilizer. Michael Tortorello. April 14, 2009. https://topics.blogs.nytimes.com/2009/04/14/the-mysteries-of-fertilizer/ ↩
-
Smil, V. (2004). Enriching the earth: Fritz Haber, Carl Bosch, and the transformation of world food production. MIT press. ↩↩↩↩↩↩↩↩↩↩↩↩↩
-
Badgley, C., Moghtader, J., Quintero, E., Zakem, E., Chappell, M. J., Aviles-Vazquez, K., ... & Perfecto, I. (2007). Organic agriculture and the global food supply. Renewable agriculture and food systems, 22(2), 86-108. ↩↩↩↩
-
Allen, R. C. (2008). The nitrogen hypothesis and the English agricultural revolution: A biological analysis. The Journal of Economic History, 68(1), 182-210. ↩
-
Ladha, J. K., Pathak, H., Krupnik, T. J., Six, J., & van Kessel, C. (2005). Efficiency of fertilizer nitrogen in cereal production: retrospects and prospects. Advances in agronomy, 87, 85-156. ↩↩↩↩
-
Dawson, C. J., & Hilton, J. (2011). Fertiliser availability in a resource-limited world: Production and recycling of nitrogen and phosphorus. Food Policy, 36, S14-S22. ↩↩↩↩↩↩
-
Tilman, D., Cassman, K. G., Matson, P. A., Naylor, R., & Polasky, S. (2002). Agricultural sustainability and intensive production practices. Nature, 418(6898), 671. ↩↩↩
-
Lu, C. C., & Tian, H. (2017). Global nitrogen and phosphorus fertilizer use for agriculture production in the past half century: shifted hot spots and nutrient imbalance. Earth System Science Data, 9, 181. ↩↩↩
-
Farming’s growing problem. Joe Wertz. January 22, 2020. Retrieved from https://publicintegrity.org/environment/unintended-consequences-farming-fertilizer-climate-health-water-nitrogen/ ↩↩↩↩↩
-
Díaz, S., Settele, J., Brondízio, E., Ngo, H., Guèze, M., Agard, J., ... & Chan, K. (2019). Summary for policymakers of the global assessment report on biodiversity and ecosystem services of the Intergovernmental Science-Policy Platform on Biodiversity and Ecosystem Services. ↩↩
-
Stewart, W. M., Dibb, D. W., Johnston, A. E., & Smyth, T. J. (2005). The contribution of commercial fertilizer nutrients to food production. Agronomy Journal, 97(1), 1-6. ↩
-
Calabi-Floody, M., Medina, J., Rumpel, C., Condron, L. M., Hernandez, M., Dumont, M., & de la Luz Mora, M. (2018). Smart fertilizers as a strategy for sustainable agriculture. In Advances in Agronomy (Vol. 147, pp. 119-157). Academic Press. ↩↩↩↩↩
-
Clark, M., & Tilman, D. (2017). Comparative analysis of environmental impacts of agricultural production systems, agricultural input efficiency, and food choice. Environmental Research Letters, 12(6), 064016. ↩↩↩↩↩↩↩↩↩↩
-
Mulvaney, R. L., Khan, S. A., & Ellsworth, T. R. (2009). Synthetic nitrogen fertilizers deplete soil nitrogen: a global dilemma for sustainable cereal production. Journal of environmental quality, 38(6), 2295-2314. ↩↩↩
-
Van Ginkel, S. W., Igou, T., & Chen, Y. (2017). Energy, water and nutrient impacts of California-grown vegetables compared to controlled environmental agriculture systems in Atlanta, GA. Resources, Conservation and Recycling, 122, 319-325. ↩↩↩↩↩↩↩↩↩
-
Cordell, D., Drangert, J. O., & White, S. (2009). The story of phosphorus: global food security and food for thought. Global environmental change, 19(2), 292-305. ↩↩↩↩↩↩↩↩↩↩↩↩↩
-
Cordell, D., Turner, A., & Chong, J. (2015). The hidden cost of phosphate fertilizers: mapping multi-stakeholder supply chain risks and impacts from mine to fork. Global Change, Peace & Security, 27(3), 323-343. ↩↩↩↩↩↩↩↩↩↩↩
-
Campbell, B. M., Beare, D. J., Bennett, E. M., Hall-Spencer, J. M., Ingram, J. S., Jaramillo, F., ... & Shindell, D. (2017). Agriculture production as a major driver of the Earth system exceeding planetary boundaries. Ecology and Society, 22(4). ↩↩↩
-
Good, A. G., & Beatty, P. H. (2011). Fertilizing nature: a tragedy of excess in the commons. PLoS biology, 9(8), e1001124. ↩↩↩↩↩↩↩
-
Ifft, J., & Jodlowski, M. (2018). Federal crop insurance participation and adoption of sustainable production practices by US corn farms (No. 2133-2018-5427). ↩↩↩
-
The Danger Downstream. Spike Johnson. January 28, 2020. Retrieved from https://grist.org/food/gulf-shrimpers-fight-for-their-livelihoods-in-a-fertilizer-fueled-dead-zone/ ↩
-
Subsidizing Waste: How Inefficient US Farm Policy Costs Taxpayers, Businesses, and Farmers Billions. Union of Concerned Scientists. August 2016. ↩↩↩↩↩↩↩↩↩
-
P For Plunder: Morocco’s exports of phosphates from occupied Western Sahara. Western Sahara Resource Watch. April 2019. https://www.wsrw.org/files/dated/2019-04-08/pforplunder2019_web.pdf ↩↩↩↩↩↩↩↩
-
Mehmood, T., Chaudhry, M. M., Tufail, M., & Irfan, N. (2009). Heavy metal pollution from phosphate rock used for the production of fertilizer in Pakistan. Microchemical Journal, 91(1), 94-99. ↩↩
-
Shcherbak, I., Millar, N., & Robertson, G. P. (2014). Global metaanalysis of the nonlinear response of soil nitrous oxide (N2O) emissions to fertilizer nitrogen. Proceedings of the National Academy of Sciences, 111(25), 9199-9204. ↩
-
Giraldo, O. F. (2019). Political ecology of agriculture: agroecology and post-development. Springer. ↩↩↩↩↩↩↩↩↩↩↩↩
-
How U.S. Agricultural Subsidies Degrade Land and Soil. July 2019. https://foodtank.com/news/2019/07/opinion-how-us-agricultural-subsidies-degrade-land-and-soil/ ↩↩↩
-
Reay, D. S., Dentener, F., Smith, P., Grace, J., & Feely, R. A. (2008). Global nitrogen deposition and carbon sinks. Nature Geoscience, 1(7), 430. ↩
-
Gattinger, A., Muller, A., Haeni, M., Skinner, C., Fliessbach, A., Buchmann, N., ... & Niggli, U. (2012). Enhanced top soil carbon stocks under organic farming. Proceedings of the National Academy of Sciences, 109(44), 18226-18231. ↩↩
-
Röös, E., Mie, A., Wivstad, M., Salomon, E., Johansson, B., Gunnarsson, S., ... & Watson, C. A. (2018). Risks and opportunities of increasing yields in organic farming. A review. Agronomy for sustainable development, 38(2), 14. ↩↩↩↩↩↩↩↩↩
-
Sheriff, G. (2005). Efficient waste? Why farmers over-apply nutrients and the implications for policy design. Review of Agricultural Economics, 27(4), 542-557. ↩↩
-
Syers, J. K., Johnston, A. E., & Curtin, D. (2008). Efficiency of soil and fertilizer phosphorus use. FAO Fertilizer and plant nutrition bulletin, 18(108). ↩
-
Policy Brief: Fertilizer Recommendations and In-kind Subsidies Increase Uptake and Yields among Maize Farmers in Mexico. Aprajit Mahajan, Xavier Gine, Carolina Corral, Enrique Seira. https://basis.ucdavis.edu/publication/policy-brief-fertilizer-recommendations-and-kind-subsidies-increase-uptake-and-yields ↩
-
USDA Squeezes the Food Industry with Outdated Subsidies. Mark A Perelman. May 14, 2018. Retrieved from https://cbey.yale.edu/our-stories/usda-squeezes-the-food-industry-with-outdated-subsidies ↩↩
-
Weber, J. G., Key, N., & O’Donoghue, E. (2016). Does federal crop insurance make environmental externalities from agriculture worse?. Journal of the Association of Environmental and Resource Economists, 3(3), 707-742. ↩
-
Crop insurance is good for farmers, but not always for the environment. Don Fullerton, Julian Reif, Megan Konar, Tatyana Deryugina. June 29, 2018. https://theconversation.com/crop-insurance-is-good-for-farmers-but-not-always-for-the-environment-96841 ↩↩
-
How Does the Farm Bill Affect Everyday Americans? Elliott Negin, Ricardo Salvador. March 1, 2018. https://blog.ucsusa.org/elliott-negin/farm-bill-and-everyday-americans ↩↩↩↩↩↩
-
https://www.yara.com/crop-nutrition/why-fertilizer/production-of-fertillizer/ ↩
-
Fertilizer Plants Spring Up to Take Advantage of U.S.’s Cheap Natural Gas. Celeste LeCompte. April 25, 2013. https://www.scientificamerican.com/article/fertilizer-plants-grow-thanks-to-cheap-natural-gas/ ↩↩↩↩↩
-
Zhou, X., Passow, F. H., Rudek, J., von Fisher, J. C., Hamburg, S. P., & Albertson, J. D. (2019). Estimation of methane emissions from the US ammonia fertilizer industry using a mobile sensing approach. Elem Sci Anth, 7(1). ↩↩↩
-
International Fertilizer Industry Association. (2001). Environmental aspects of phosphate and potash mining. UNEP. ↩
-
Cañedo-Argüelles, M., Brucet, S., Carrasco, S., Flor-Arnau, N., Ordeix, M., Ponsá, S., & Coring, E. (2017). Effects of potash mining on river ecosystems: An experimental study. Environmental pollution, 224, 759-770. ↩
-
Amann, A., Zoboli, O., Krampe, J., Rechberger, H., Zessner, M., & Egle, L. (2018). Environmental impacts of phosphorus recovery from municipal wastewater. Resources, Conservation and Recycling, 130, 127-139. ↩↩
-
World Phosphate Rock Reserves and Resources. S. Van Kauwenbergh. IFDC. November 2010. http://www.firt.org/sites/default/files/SteveVanKauwenbergh_World_Phosphate_Rock_Reserve.pdf ↩↩
-
Foster, J. B. (1999). Marx's theory of metabolic rift: Classical foundations for environmental sociology. American journal of sociology, 105(2), 366-405. ↩
-
Cushman, G. T. (2013). Guano and the opening of the Pacific world: a global ecological history. Cambridge University Press. ↩↩↩↩↩↩↩↩↩↩
-
Clark, B., & Foster, J. B. (2009). Ecological imperialism and the global metabolic rift: Unequal exchange and the guano/nitrates trade. International Journal of Comparative Sociology, 50(3-4), 311-334. ↩↩↩↩↩↩
-
Jackson, S. (2016). The phosphate archipelago: Imperial mining and global agriculture in French North Africa. Jahrbuch für Wirtschaftsgeschichte/Economic History Yearbook, 57(1), 187-214. ↩↩
-
Edwards, J. B. (2014). Phosphate mining and the relocation of the Banabans to northern Fiji in 1945: Lessons for climate change-forced displacement. Journal de la Société des Océanistes, (138-139), 121-136. ↩↩
-
Teaiwa, K. (2015). Ruining Pacific islands: Australia's phosphate imperialism. Australian Historical Studies, 46(3), 374-391. ↩↩↩
-
Connell, J. (2006). Nauru: The first failed Pacific state?. The Round Table, 95(383), 47-63. ↩
-
Camprubí, L. (2015). Resource geopolitics: Cold war technologies, global fertilizers, and the fate of Western Sahara. Technology and Culture, 56(3), 676-703. ↩↩↩↩↩↩
-
Mineral Resource of the Month: Phosphate Rock, Stephen M. Jasinski (December 2, 2013) https://www.earthmagazine.org/article/mineral-resource-month-phosphate-rock ↩
-
White, N. (2015). Conflict stalemate in Morocco and Western Sahara: Natural resources, legitimacy and political recognition. British Journal of Middle Eastern Studies, 42(3), 339-357. ↩↩↩↩↩↩↩↩↩
-
Jensen, G. (2013). War and insurgency in the Western Sahara. Current Politics and Economics of Africa, 6(4), 339. ↩↩↩↩↩↩↩↩↩
-
UN must monitor human rights in Western Sahara and Sahrawi refugee camps. Amnesty International. April 26, 2016. https://www.amnesty.org/en/latest/news/2016/04/un-must-monitor-human-rights-in-western-sahara-and-sahrawi-refugee-camps/ ↩
-
UN must monitor human rights in Western Sahara and Sahrawi refugee camps. Amnesty International. April 26, 2019. https://www.amnesty.org/download/Documents/MDE2902662019ENGLISH.pdf ↩
-
Morocco/Western Sahara: Investigate brutal crackdown on Sahrawi protesters. Amnesty International. August 1, 2019. https://www.amnesty.org/en/latest/news/2019/08/morocco-western-sahara-investigate-brutal-crackdown-on-sahrawi-protesters/ ↩
-
Has another cargo of fishmeal from Western Sahara arrived in Germany? Western Sahara Resource Watch. May 2, 2019. Retrieved from https://www.wsrw.org/a105x4505. ↩
-
Rowe, H., Withers, P. J., Baas, P., Chan, N. I., Doody, D., Holiman, J., ... & Sharpley, A. N. (2016). Integrating legacy soil phosphorus into sustainable nutrient management strategies for future food, bioenergy and water security. Nutrient Cycling in Agroecosystems, 104(3), 393-412. ↩
-
Ponisio, L. C., M'Gonigle, L. K., Mace, K. C., Palomino, J., de Valpine, P., & Kremen, C. (2015). Diversification practices reduce organic to conventional yield gap. Proceedings of the Royal Society B: Biological Sciences, 282(1799), 20141396. ↩↩↩↩↩↩↩
-
Saeid, A., & Chojnacka, K. (2019). Fertlizers: Need for new strategies. In Organic Farming (pp. 91-116). Woodhead Publishing. ↩↩↩
-
Frink, C. R., Waggoner, P. E., & Ausubel, J. H. (1999). Nitrogen fertilizer: retrospect and prospect. Proceedings of the National Academy of Sciences, 96(4), 1175-1180. ↩
-
Olesen, J. E., Jørgensen, L. N., Petersen, J., & Mortensen, J. V. (2003). Effects of rate and timing of nitrogen fertilizer on disease control by fungicides in winter wheat. 1. Grain yield and foliar disease control. The Journal of Agricultural Science, 140(1), 1-13. ↩
-
Lu, Z. X., Yu, X. P., Heong, K. L., & Cui, H. U. (2007). Effect of nitrogen fertilizer on herbivores and its stimulation to major insect pests in rice. Rice Science, 14(1), 56-66. ↩
-
Altieri, M. A., & Nicholls, C. I. (2003). Soil fertility management and insect pests: harmonizing soil and plant health in agroecosystems. Soil and Tillage Research, 72(2), 203-211. ↩↩
-
Chau, L. M., & Heong, K. L. (2005). Effects of organic fertilizers on insect pest and diseases of rice. Omonrice, 13, 26-33. ↩
-
Do industrial agricultural methods actually yield more food per acre than organic ones? Nathanael Johnson. October 14, 2015. https://grist.org/food/do-industrial-agricultural-methods-actually-yield-more-food-per-acre-than-organic-ones/ ↩
-
Seufert, V., & Ramankutty, N. (2017). Many shades of gray—The context-dependent performance of organic agriculture. Science advances, 3(3), e1602638. ↩
-
Is organic really better for the environment than conventional agriculture? Hannah Ritchie. October 19, 2017. https://ourworldindata.org/is-organic-agriculture-better-for-the-environment ↩↩
-
Muller, A., Schader, C., Scialabba, N. E. H., Brüggemann, J., Isensee, A., Erb, K. H., ... & Niggli, U. (2017). Strategies for feeding the world more sustainably with organic agriculture. Nature communications, 8(1), 1290. ↩↩↩↩↩
-
Smith, Laurence G.; Kirk, Guy J. D.; Jones, Philip J.; Williams, Adrian G. (2019): The greenhouse gas impacts of converting food production in England and Wales to organic methods. In Nat Commun 10 (1), pp. 1–10. DOI: 10.1038/s41467-019-12622-7. ↩
-
van der Werf, H. M., Knudsen, M. T., & Cederberg, C. (2020). Towards better representation of organic agriculture in life cycle assessment. Nature Sustainability, 1-7. ↩↩
-
Kozai, T., & Niu, G. (2016). Conclusions: Resource-Saving and Resource-Consuming Characteristics of PFALs. In Plant Factory (pp. 395-399). Academic Press. ↩↩↩↩↩
-
Mohareb, E., Heller, M., Novak, P., Goldstein, B., Fonoll, X., & Raskin, L. (2017). Considerations for reducing food system energy demand while scaling up urban agriculture. Environmental Research Letters, 12(12), 125004. ↩↩↩↩↩↩
-
Sanjuan-Delmás, D., Llorach-Massana, P., Nadal, A., Ercilla-Montserrat, M., Muñoz, P., Montero, J. I., ... & Rieradevall, J. (2018). Environmental assessment of an integrated rooftop greenhouse for food production in cities. Journal of cleaner production, 177, 326-337. ↩↩↩↩↩↩↩↩↩↩
-
Edmondson, J. L., Cunningham, H., Tingley, D. O. D., Dobson, M. C., Grafius, D. R., Leake, J. R., ... & Stovin, V. (2020). The hidden potential of urban horticulture. Nature Food, 1(3), 155-159. ↩
-
BENIS, K., GOMES, R., VICENTE, R., FERRAO, P., & FERNANDEZ, J. (2015). Rooftop greenhouses: LCA and energy simulation. In Proceedings of International Conference CISBAT 2015 Future Buildings and Districts Sustainability from Nano to Urban Scale (No. CONF, pp. 95-100). LESO-PB, EPFL. ↩
-
Muñoz, P., Antón, A., Nuñez, M., Paranjpe, A., Ariño, J., Castells, X., ... & Rieradevall, J. (2007, October). Comparing the environmental impacts of greenhouse versus open-field tomato production in the Mediterranean region. In International Symposium on High Technology for Greenhouse System Management: Greensys2007 801 (pp. 1591-1596). ↩↩↩↩↩
-
El-Essawy, H., Nasr, P., & Sewilam, H. (2019). Aquaponics: a sustainable alternative to conventional agriculture in Egypt–a pilot scale investigation. Environmental Science and Pollution Research, 26(16), 15872-15883. ↩↩↩↩↩
-
Russo, G., & Scarascia Mugnozza, G. (2004, September). LCA methodology applied to various typology of greenhouses. In International Conference on Sustainable Greenhouse Systems-Greensys2004 691 (pp. 837-844). ↩↩↩
-
The How-To of Organic Hydroponics. Lynette Morgan. January 30, 2014. https://www.maximumyield.com/the-how-to-of-organic-hydroponics/2/1299 ↩
-
Vertical farming and hydroponics on the spectrum of sustainability. Alicia Miller. April 5, 2018. Retrieved from https://sustainablefoodtrust.org/articles/vertical-farming-and-hydroponics-on-the-spectrum-of-sustainability/ ↩↩↩
-
Romeo, D., Vea, E. B., & Thomsen, M. (2018). Environmental impacts of urban hydroponics in Europe: a case study in Lyon. Procedia CIRP, 69, 540-545. ↩↩↩↩↩↩↩
-
Benke, K., & Tomkins, B. (2017). Future food-production systems: vertical farming and controlled-environment agriculture. Sustainability: Science, Practice and Policy, 13(1), 13-26. ↩↩
-
Banerjee, C., & Adenaeuer, L. (2014). Up, up and away! The economics of vertical farming. Journal of Agricultural Studies, 2(1), 40-60. ↩↩↩
-
Graamans, L., Baeza, E., Van Den Dobbelsteen, A., Tsafaras, I., & Stanghellini, C. (2018). Plant factories versus greenhouses: Comparison of resource use efficiency. Agricultural Systems, 160, 31-43. ↩↩
-
Schrammel, E. (2015). A cost-benefit analysis of hydroponic wastewater treatment in Sweden. ↩
-
Razon, L. F. (2015). Is nitrogen fixation (once again) “vital to the progress of civilized humanity”?. Clean Technologies and Environmental Policy, 17(2), 301-307. ↩
-
The way we make fertilizer sucks, but we haven’t had a good alternative … until now. Nathanael Johnson. April 29, 2016. https://grist.org/article/the-way-we-make-fertilizer-sucks-but-we-havent-had-a-good-alternative-until-now/ ↩↩
-
Brown, K. A., Harris, D. F., Wilker, M. B., Rasmussen, A., Khadka, N., Hamby, H., ... & King, P. W. (2016). Light-driven dinitrogen reduction catalyzed by a CdS: nitrogenase MoFe protein biohybrid. Science, 352(6284), 448-450. ↩
-
A sustainable, energy-saving way to make the key ingredient in fertilizers. Xiaofeng Feng. May 23, 2018. https://theconversation.com/a-sustainable-energy-saving-way-to-make-the-key-ingredient-in-fertilizers-96693 ↩↩
-
Comer, B. M., Fuentes, P., Dimkpa, C. O., Liu, Y. H., Fernandez, C. A., Arora, P., ... & Medford, A. J. (2019). Prospects and challenges for solar fertilizers. Joule, 3(7), 1578-1605. ↩↩↩
-
Martín, A. J., & Pérez-Ramírez, J. (2019). Heading to distributed electrocatalytic conversion of small abundant molecules into fuels, chemicals, and fertilizers. Joule, 3(11), 2602-2621. ↩
-
The U.S. Fertilizer Industry and Climate Change Policy. The Fertilizer Institute. https://kochfertilizer.com/pdf/TFI2009ClimateChange.pdf ↩
-
Renewable Ammonia from Biomass: SynGest, BioNitrogen, Agrebon. Trevor Brown. April 24, 2013. Retrieved from https://nh3fuelassociation.org/2013/04/24/ammonia-from-biomass/ ↩
-
BioNitrogen in bankruptcy. Trevor Brown. November 6, 2015. Retrieved from https://ammoniaindustry.com/bionitrogen-in-bankruptcy/ ↩
-
Casselton, ND — Agrebon. Trevor Brown. November 1, 2013. Retrieved from https://ammoniaindustry.com/casselton-nd-agrebon/ ↩
-
Randall, D. G., & Naidoo, V. (2018). Urine: The liquid gold of wastewater. Journal of Environmental Chemical Engineering, 6(2), 2627-2635. ↩↩↩
-
Gone Tomorrow: The Hidden Life of Garbage. Heather Rogers. 2005. ↩
-
Alexander, C., Gregson, N., & Gille, Z. (2013). Food waste. The handbook of food research, 1, 471-483. ↩↩↩↩↩↩↩
-
Transforming Food Waste into Plant-Based Technologies: Re-Nuble. September 3, 2019. Retrieved from https://www.nycfoodpolicy.org/transforming-food-waste-into-plant-based-technologies-re-nuble/ ↩
-
Tarayre, C., De Clercq, L., Charlier, R., Michels, E., Meers, E., Camargo-Valero, M., & Delvigne, F. (2016). New perspectives for the design of sustainable bioprocesses for phosphorus recovery from waste. Bioresource Technology, 206, 264-274. ↩↩
-
Mehta, C. M., Hunter, M. N., Leong, G., & Batstone, D. J. (2018). The value of wastewater derived struvite as a source of phosphorus fertilizer. CLEAN–Soil, Air, Water, 46(7), 1700027. ↩
-
Chan, K. Y., & Xu, Z. (2012). Biochar: nutrient properties and their enhancement. In Biochar for environmental management (pp. 99-116). Routledge. ↩↩
-
Rorat, A., & Vandenbulcke, F. (2019). Earthworms converting domestic and food industry wastes into biofertilizer. In Industrial and Municipal Sludge (pp. 83-106). Butterworth-Heinemann. ↩↩↩↩↩
-
Hribar, C. (2010). Understanding concentrated animal feeding operations and their impact on communities. ↩
-
Mohammadi, K., & Sohrabi, Y. (2012). Bacterial biofertilizers for sustainable crop production: a review. J Agric Biol Sci, 7, 307-316. ↩↩↩
-
Death by fertilizer. Nathanael Johnson. October 2, 2018. https://grist.org/article/billionaires-and-bacteria-are-racing-to-save-us-from-death-by-fertilizer/ ↩
-
Backer, R., Rokem, J. S., Ilangumaran, G., Lamont, J., Praslickova, D., Ricci, E., ... & Smith, D. L. (2018). Plant growth-promoting rhizobacteria: context, mechanisms of action, and roadmap to commercialization of biostimulants for sustainable agriculture. Frontiers in plant science, 9. ↩↩↩↩↩↩
-
Suthar, H., Hingurao, K., Vaghashiya, J., & Parmar, J. (2017). Fermentation: A Process for Biofertilizer Production. In Microorganisms for Green Revolution (pp. 229-252). Springer, Singapore. ↩↩↩↩↩↩↩↩↩
-
Kumar, J., Singh, D., Tyagi, M. B., & Kumar, A. (2019). Cyanobacteria: Applications in Biotechnology. In Cyanobacteria (pp. 327-346). Academic Press. ↩↩↩↩↩
-
Replacing fertilizer with plant probiotics could slash greenhouse gases. October 2, 2018. https://www.technologyreview.com/f/612223/forget-fertilizer-this-startup-aims-to-slash-greenhouse-gases-with-plant/ ↩
-
Bayer and Ginkgo Bioworks Unveil Joint Venture, Joyn Bio, and Establish Operations in Boston and West Sacramento. March 20, 2018. https://www.prnewswire.com/news-releases/bayer-and-ginkgo-bioworks-unveil-joint-venture-joyn-bio-and-establish-operations-in-boston-and-west-sacramento-300616544.html ↩↩
-
Singh, V. K., Singh, M., Singh, S. K., Kumar, C., & Kumar, A. (2019). Sustainable Agricultural Practices Using Beneficial Fungi Under Changing Climate Scenario. In Climate Change and Agricultural Ecosystems (pp. 25-42). Woodhead Publishing. ↩↩↩↩
-
Recipe for Success: Brew Your Own Biofertilizer. Anna Birn. January 30, 2019. https://smallfarms.cornell.edu/2019/01/recipe-for-success-brew-your-own-biofertilizer/ ↩↩
-
Palma, I. P., Toral, J. N., Vázquez, M. R. P., Fuentes, N. F., & Hernández, F. G. (2015). Historical changes in the process of agricultural development in Cuba. Journal of Cleaner Production, 96, 77-84. ↩↩↩↩↩
-
Nutrien. November 25, 2019. Retrieved from https://en.wikipedia.org/wiki/Nutrien ↩
-
Nutrien Is Quietly Positioning Itself for the Future of Agriculture. Maxx Chatsko. April 14, 2019. https://www.fool.com/investing/2019/04/14/nutrien-is-quietly-positioning-itself-for-the-futu.aspx ↩
-
Producción de biol SUPERMAGRO. Nelly Aliaga. http://www.agrolalibertad.gob.pe/sites/default/files/Manual_de__Bioles_rina.pdf ↩
-
Canter, C. E., Qin, Z., Cai, H., Dunn, J. B., Wang, M., & Scott, D. A. (2017). Fossil energy consumption and greenhouse gas emissions, including soil carbon effects, of producing agriculture and forestry feedstocks. In: Efroymson, RA; Langholtz, MH; Johnson, KE; Stokes, BJ, eds. 2016 billion-ton report: Advancing domestic resources for a thriving bioeconomy. Volume 2: Environmental sustainability effects of select scenarios from volume 1. ORNL/TM-2016/727. Oak Ridge, TN: Oak Ridge National Laboratory: 85-137., 2017, 85-137. ↩
-
Shaw, A., & Wilson, K. (2020). The Bill and Melinda Gates Foundation and the necro-populationism of ‘climate-smart’ agriculture. Gender, Place & Culture, 27(3), 370-393. ↩
-
Food waste within food supply chains: quantification and potential for change ↩↩↩↩↩↩↩↩↩↩
-
Stenmarck, Â., Jensen, C., Quested, T., Moates, G., Buksti, M., Cseh, B., ... & Scherhaufer, S. (2016). Estimates of European food waste levels. IVL Swedish Environmental Research Institute. ↩
-
Cloke, J. (2013). Empires of waste and the food security meme. Geography Compass, 7(9), 622-636. ↩↩↩↩↩↩↩
-
Cuéllar, A. D., & Webber, M. E. (2010). Wasted food, wasted energy: the embedded energy in food waste in the United States. Environmental science & technology, 44(16), 6464-6469. ↩
-
Quested, T. E., Marsh, E., Stunell, D., & Parry, A. D. (2013). Spaghetti soup: The complex world of food waste behaviours. Resources, Conservation and Recycling, 79, 43-51. ↩↩↩
-
Gustavsson, J., Cederberg, C., Sonesson, U., Van Otterdijk, R., & Meybeck, A. (2011). Global food losses and food waste (pp. 1-38). Rome: FAO. ↩↩↩↩↩↩↩
-
Bovay, J., & Zhang, W. (2019). A Century of Profligacy? The Measurement and Evolution of Food Waste. Agricultural and Resource Economics Review, 1-35. ↩↩↩
-
Gille, Z. (2012). From risk to waste: global food waste regimes. The Sociological Review, 60, 27-46. ↩↩↩↩↩↩↩
-
Williams, H., Wikström, F., Otterbring, T., Löfgren, M., & Gustafsson, A. (2012). Reasons for household food waste with special attention to packaging. Journal of cleaner production, 24, 141-148. ↩
-
French Food Waste Law Changing How Grocery Stores Approach Excess Food. Eleanor Beardsley. February 24, 2018. https://www.npr.org/sections/thesalt/2018/02/24/586579455/french-food-waste-law-changing-how-grocery-stores-approach-excess-food ↩
-
Fernandez, M., Williams, J., Figueroa, G., Lovelace, G. G., Machado, M., Vasquez, L., ... & Aguilar, F. F. (2018). New opportunities, new challenges: Harnessing Cuba’s advances in agroecology and sustainable agriculture in the context of changing relations with the United States. Elem Sci Anth, 6(1). ↩↩↩↩↩↩↩↩↩↩↩↩↩
-
McMichael, P. (2016). Commentary: Food regime for thought. The Journal of Peasant Studies, 43(3), 648-670. ↩↩↩↩
-
Mazzarino, T. (2012). Policy Alternatives for Federal Agricultural Subsidies: Fertilization Protocols and Their Effects on Crop Yields, Sustainability, and Food Justice. ↩↩
-
A Farmer Living Wage. National Family Farm Coalition. Retrieved from https://nffc.net/what-we-do/farmer-living-wage/ ↩↩↩
-
George Monbiot Misinterprets Farm Subsidies 1. Brad Wilson. February 23, 2016. Retrieved from https://zcomm.org/zblogs/george-monbiot-misinterprets-farm-subsidies-1/ ↩↩
-
Fair Prices for Farmers. National Family Farm Coalition. Retrieved from https://nffc.net/what-we-do/fair-prices-for-farmers/ ↩↩↩↩
-
Friedmann, H. (1993). The political economy of food: a global crisis. New left review, (197), 29-57. ↩↩↩↩↩
-
The Key to Saving Family Farms Is in the Soil. David R. Montgomery. October 19, 2019. https://www.ecowatch.com/family-farms-regenerative-farming-practices-2641025788.html ↩
-
Large Loans Drive Further Increases in Farm Lending. Nathan Kauffman, Ty Kreitman. July 18, 2019. https://www.kansascityfed.org/research/indicatorsdata/agfinancedatabook/articles/2019/7-18-19/ag-finance-dbk-7-18-2019 ↩↩
-
Ag. Canada Tells Ontario Farmers to Expect The Worst Year Ever. May 06, 2010. Retrieved from https://www.farms.com/news/ag-canada-tells-ontario-farmers-to-expect-the-worst-year-ever-30219.aspx ↩
-
Miller, C., & Jones, L. (2010). Agricultural value chain finance: Tools and lessons. Food and Agriculture Organization of the United Nations and Practical Action Pub.. ↩↩
-
Fertilizer dealer Nutrien aims to triple U.S. farm loans, guided by ex-Walmart executive. Rod Nickel. May 31, 2019. https://www.reuters.com/article/us-nutrien-farming-loans-exclusive/exclsuive-fertilizer-dealer-nutrien-aims-to-triple-u-s-farm-loans-guided-by-ex-walmart-executive-idUSKCN1T12AL ↩
-
Farm loan delinquencies highest in 9 years as prices slump. Roxana Hegeman. February 28, 2019. https://www.apnews.com/7881b72df9aa41c28900acba09558e5e ↩↩
-
No Quick Subsidies Fix for Food System. Wenonah Hauter. March 31, 2011. https://civileats.com/2011/03/31/no-quick-subsidies-fix-for-food-system/ ↩
-
Starmer, E., & Wise, T. A. (2007). Feeding at the Trough: Industrial Livestock Firms Saved $35 Billion from Low Feed Prices. GDAE Policy Brief, (07-03). ↩
-
National Farmers Union (Canada). (2005). The farm crisis & corporate profits: A report. Saskatoon, Sask.: National Farmers Union. ↩
-
Farmworkers’ Low Wage Rates Have Risen Modestly; Now Congress May Pass a Law to Lower Them. Madeline Ramey. September 19, 2018. Retrieved from https://www.farmworkerjustice.org/fj-blog/2018/09/farmworkers-low-wage-rates-have-risen-modestly-now-congress-may-pass-law-lower-them ↩
-
Justice, F. (2011). No way to treat a guest: why the H-2A agricultural visa program fails US and foreign workers. Washington, DC: Farmworker Justice, 1-44. ↩
-
Magdoff, F. (2013). Twenty-first-century land grabs: Accumulation by agricultural dispossession. Monthly Review, 65(6), 1. ↩↩↩↩↩↩↩
-
Blaikie, P. (1985). The political economy of soil erosion in developing countries. Routledge. ↩↩↩↩↩↩↩
-
Our crazy farm subsidies, explained. Amelia Urry. April 20, 2015. Retrieved from https://grist.org/food/our-crazy-farm-subsidies-explained/ ↩
-
2018 Farm Bill Drilldown: Commodity Programs and Crop Insurance. National Sustainable Agriculture Coalition. December 14, 2018. https://sustainableagriculture.net/blog/2018-farm-bill-commodity-subsidies-crop-insurance/ ↩
-
Rosset, P. M., & Altieri, M. A. (1997). Agroecology versus input substitution: a fundamental contradiction of sustainable agriculture. Society & Natural Resources, 10(3), 283-295. ↩↩↩↩
-
Holt-Giménez, E., & Altieri, M. A. (2013). Agroecology, food sovereignty, and the new green revolution. Agroecology and sustainable Food systems, 37(1), 90-102. ↩
-
Ng, F., & Aksoy, M. A. (2008). Who are the net food importing countries?. The World Bank. ↩↩
-
Shaw, D. J. (2007). World food security: A History since 1945. ↩
-
Genetic Resources Action International, & GRAIN. (2012). The great food robbery: how corporations control food, grab land and destroy the climate. Fahamu/Pambazuka. ↩↩↩↩↩↩↩↩↩↩↩↩↩↩
-
Zimbabwe’s food security in crisis—but not for reasons you might think. Anna Brazier. December 17, 2019. Retrieved from https://africasacountry.com/2019/12/zimbabwes-food-security-in-crisis-but-not-for-reasons-you-might-think/ ↩↩↩↩↩
-
Kallummal, M., Mendiratta, D., & Sangita, S. (2018). US Import Refusals of Agricultural Products and Their Impact on the Participation of Indian Firms. Agrarian South: Journal of Political Economy, 7(1), 78-104. ↩
-
Barkin, D. (2005). Wealth, poverty and sustainable development (No. 0506003). University Library of Munich, Germany. ↩↩↩↩↩
-
The fight for the future of food. Joeva Rock. December 18, 2019. Retrieved from https://africasacountry.com/2019/12/the-fight-for-the-future-of-food ↩↩↩
-
Barkin, D. (2002). The reconstruction of a modern Mexican peasantry. The Journal of Peasant Studies, 30(1), 73-90. ↩
-
Barkin, D. (1987). The end to food self-sufficiency in Mexico. Latin American Perspectives, 14(3), 271-297. ↩↩↩↩↩↩
-
de Graaff, J., Kessler, A., & Nibbering, J. W. (2011). Agriculture and food security in selected countries in Sub-Saharan Africa: diversity in trends and opportunities. Food Security, 3(2), 195-213. ↩↩
-
How Farm Policy and Big Ag Impact Farmers in the U.S. and Abroad. Eva Perroni, Timothy Wise. March 7, 2019. https://civileats.com/2019/03/07/how-farm-policy-and-big-ag-impact-farmers-in-the-u-s-and-abroad/ ↩↩↩
-
Crawford, E. W., Jayne, T. S., & Kelly, V. A. (2005). Alternative approaches for promoting fertilizer use in africa, with emphasis on the role of subsidies (No. 1095-2016-88224). ↩↩↩
-
Kiage, L. M. (2013). Perspectives on the assumed causes of land degradation in the rangelands of Sub-Saharan Africa. Progress in Physical Geography, 37(5), 664-684. ↩↩↩↩
-
Small farmers feel left out amid a boom in African fertilizer production. Rupa Shenoy. January 22, 2020. Retrieved from https://grist.org/food/small-farmers-feel-left-out-amid-a-boom-in-african-fertilizer-production/ ↩
-
Subsidized Fertilizer: The Answer to Africa's Food Crisis? Brendan Borrell. June 18, 2009. https://www.scientificamerican.com/article/subsidized-fertilizer-africa/ ↩↩↩
-
Morgan, S. N., Mason, N. M., Levine, N. K., & Zulu-Mbata, O. (2019). Dis-incentivizing sustainable intensification? The case of Zambia’s maize-fertilizer subsidy program. World Development, 122, 54-69. ↩↩↩
-
Malawi’s fertilizer subsidies are not a panacea for farmer households. Adam Komarek, Siwa Msangi. May 12, 2017. http://www.ifpri.org/blog/malawis-fertilizer-subsidies-are-not-panacea-farmer-households ↩↩
-
Jayne, T. S., Mason, N. M., Burke, W. J., & Ariga, J. (2018). Taking stock of Africa’s second-generation agricultural input subsidy programs. Food Policy, 75, 1-14. ↩↩
-
Gilbert, N., Gewin, V., Tollefson, J., Sachs, J., & Potrykus, I. (2010). How to feed a hungry world. Nature, 466, 531-532. ↩↩↩↩
-
Biel, R. A. (2016). Sustainable Food Systems (pp. 74-89). UCL press. ↩↩
-
Wolford, W. (2019). The colonial roots of agricultural modernization in Mozambique: the role of research from Portugal to ProSavana. The Journal of Peasant Studies, 1-20. ↩
-
Paudel, J., & Crago, C. L. (2017). Fertilizer Subsidy and Agricultural Productivity: Empirical Evidence from Nepal. ↩↩
-
'Green Revolution' Trapping India's Farmers In Debt. Daniel Zwerdling. April 19, 2009. https://www.npr.org/2009/04/14/102944731/green-revolution-trapping-indias-farmers-in-debt ↩↩↩
-
Kalkuhl, M., Von Braun, J., & Torero, M. (Eds.). (2016). Food price volatility and its implications for food security and policy: Volatile and Extreme Food Prices, Food Security, and Policy: An Overview. Springer Open. ↩↩
-
Climate Change and Rising Food Prices Heightened Arab Spring. Ines Perez. March 4, 2013. Retrieved from https://www.scientificamerican.com/article/climate-change-and-rising-food-prices-heightened-arab-spring/ ↩
-
Simon Reardon, J. A., & Pérez, R. A. (2010). Agroecology and the development of indicators of food sovereignty in Cuban food systems. Journal of Sustainable Agriculture, 34(8), 907-922. ↩↩↩↩
-
Nair, S. R. Agrarian Suicides in India: Myth and Reality. Development Policy Review. ↩↩
-
One of Africa’s Most Fertile Lands Is Struggling to Feed Its Own People. Peter Schwartzstein. April 2, 2019. Retrieved from https://www.bloomberg.com/features/2019-sudan-nile-land-farming/ ↩↩↩
-
Mann, H., & Smaller, C. (2010). Foreign land purchases for agriculture: What impact on sustainable development. Sustainable development innovation briefs, 8, 1-8. ↩
-
The global farmland grab in 2016: how big, how bad? GRAIN. June 14, 2016. Retrieved from https://www.grain.org/article/entries/5492-the-global-farmland-grab-in-2016-how-big-how-bad ↩↩↩
-
Henderson, C. (2020). Land grabs reexamined: Gulf Arab agro-commodity chains and spaces of extraction. Environment and Planning A: Economy and Space, 0308518X20956657. ↩↩
-
The Great Land Robbery. Vann R. Newkirk II. September 2019. Retrieved from https://www.theatlantic.com/magazine/archive/2019/09/this-land-was-our-land/594742/ ↩↩
-
Ouma, S. (2016). From financialization to operations of capital: Historicizing and disentangling the finance–farmland-nexus. Geoforum, 72, 82-93. ↩↩↩
-
Puel, J. M. (2012). Are Sovereign Wealth Funds’ Investments in Agriculture Political?. Études rurales, (2), 161-176. ↩↩
-
From Public Good to Private Profit: The Shifting Discourse on Land Grabbing. Sarika Mathur. September 6, 2011. Retrieved from https://www.globalpolicy.org/world-hunger/land-ownership-and-hunger/50685-from-public-good-to-private-profit-the-shifting-discourse-on-land-grabbing.html?itemid=id#1292 ↩
-
Cotula, L., Dyer, N., & Vermeulen, S. (2008). Bioenergy and land tenure: The implications of Biofuels for land tenure and land policy. International Institute for Environment and Development, London. ↩
-
Foreign investment in U.S. farmland on the rise. Johnathan Hettinger, Robert Holly, Jelter Meers. June 22, 2017. https://investigatemidwest.org/2017/06/22/foreign-investment-into-u-s-farmland-on-the-rise/ ↩
-
Losing ground. Reveal. July 1, 2017. Retrieved from https://www.revealnews.org/episodes/losing-ground/ ↩
-
Rosegrant, M. W. (2008). Biofuels and grain prices: impacts and policy responses (pp. 1-4). Washington, DC: International Food Policy Research Institute. ↩
-
Koizumi, T. (2015). Biofuels and food security. Renewable and Sustainable Energy Reviews, 52, 829-841. ↩
-
Tomei, J., & Helliwell, R. (2016). Food versus fuel? Going beyond biofuels. Land use policy, 56, 320-326. ↩
-
Big Food is Betting on Regenerative Agriculture to Thwart Climate Change. Gosia Wozniacka. October 29, 2019. Retrieved from https://civileats.com/2019/10/29/big-food-is-betting-on-regenerative-agriculture-to-thwart-climate-change/ ↩
-
Agrarian Dreams: The Paradox of Organic Farming in California. Julie Guthman. 2004. ↩
-
'Junk Agroecology': The corporate capture of agroecology for a partial ecological transition without social justice. April 2020. Transnational Institute, Friends of the Earth International, Crocevia. ↩
-
Ajl, M. (2014). The hypertrophic city versus the planet of fields. Implosions/Explosions: towards a study of planetary urbanization, 533-550. ↩↩
-
Glover, J. D., Reganold, J. P., & Cox, C. M. (2012). Plant perennials to save Africa's soils. Nature, 489(7416), 359-361. ↩
-
Ajayi, O. C., Place, F., Akinnifesi, F. K., & Sileshi, G. W. (2011). Agricultural success from Africa: the case of fertilizer tree systems in southern Africa (Malawi, Tanzania, Mozambique, Zambia and Zimbabwe). International journal of agricultural sustainability, 9(1), 129-136. ↩↩
-
George Washington Carver: Touching Infinity. Devyn Springer. February 21, 2020. Retrieved from https://wearyourvoicemag.com/identities/george-washington-carver-touching-infinity ↩
-
De Schutter, O. (2010). Report Submitted by the Special Rapporteur on the Right to Food: Human Rigths Council Sixteenth Session: Agenda Item 3: Promotion and Protection of All Human Rights, Civil, Political, Economic, Social and Cultural Rights, Including the Right to Develop. United Nations (UN). ↩↩
-
Contemporary agriculture: climate, capital, and cyborg ecology. Out of the Woods. Retrieved from https://libcom.org/blog/contemporary-agriculture-climate-capital-cyborg-ecology-17072015 ↩↩
-
Rosset, P. M., Machín Sosa, B., Roque Jaime, A. M., & Ávila Lozano, D. R. (2011). The Campesino-to-Campesino agroecology movement of ANAP in Cuba: social process methodology in the construction of sustainable peasant agriculture and food sovereignty. The Journal of peasant studies, 38(1), 161-191. ↩↩↩↩↩
-
Ricciardi, V., Ramankutty, N., Mehrabi, Z., Jarvis, L., & Chookolingo, B. (2018). How much of the world's food do smallholders produce?. Global food security, 17, 64-72. ↩
-
In Defense of Agroecology. Ellinor Isgren, Thaddeo Kahigwa Tibasiima. July 15, 2019. Retrieved from https://thebreakthrough.org/journal/no-11-summer-2019/in-defense-of-agroecology ↩↩
-
US academics feel the invisible hand of politicians and big agriculture. Kate Cox, Claire Brown. January 31, 2019. https://www.theguardian.com/environment/2019/jan/31/us-academics-feel-the-invisible-hand-of-politicians-and-big-agriculture ↩
-
Mugwanya, N. (2019). Why agroecology is a dead end for Africa. Outlook on Agriculture, 48(2), 113-116. ↩
-
The Oil We Eat: Following the Food Chain back to Iraq. Richard Manning. May 23, 2004. https://www.resilience.org/stories/2004-05-23/oil-we-eat-following-food-chain-back-iraq/ ↩
-
Madison, M. G. (1997). 'Potatoes Made of Oil': Eugene and Howard Odum and the Origins and Limits of American Agroecology. Environment and History, 3(2), 209-238. ↩
-
After Agroecology. Nassib Mugwanya. February 4, 2019. Retrieved from https://thebreakthrough.org/journal/no-10-winter-2019/after-agroecology ↩
-
How to Make Biomass Energy Sustainable Again. Kris De Decker. https://www.lowtechmagazine.com/2020/09/how-to-make-biomass-energy-sustainable-again.html ↩
-
Perennial Crops: New Hardware for Agriculture. The Land Institute. https://landinstitute.org/our-work/perennial-crops/ ↩
-
Eat Local: Cuba's Urban Gardens Raise Food on Zero Emissions. Max Ajl. January 27, 2009. https://insideclimatenews.org/news/20090127/eat-local-cubas-urban-gardens-raise-food-zero-emissions ↩↩↩
-
Altieri, M. A., & Funes-Monzote, F. R. (2012). The paradox of Cuban agriculture. Monthly Review, 63(8), 23-33. ↩↩↩↩↩
-
Cuba’s rivers run clean after decades of sustainable farming. February 4, 2020. Retrieved from https://www.nature.com/articles/d41586-020-00263-6 ↩
-
Cuba faces squeeze on food production as US oil sanctions bite. Ed Augustin. March 18, 2020. Retrieved from https://www.theguardian.com/world/2020/mar/18/cuba-food-production-us-oil-sanctions ↩
-
The Environmental Situation in Cuba. People in Need. December 2015. ↩
-
Piemonte, V., & Gironi, F. (2012). Bioplastics and GHGs saving: the land use change (LUC) emissions issue. Energy Sources, Part A: Recovery, Utilization, and Environmental Effects, 34(21), 1995-2003. ↩
-
Climate Change and Land: Summary for Policymakers. IPCC. 2019. ↩
-
Pachauri, R. K., Allen, M. R., Barros, V. R., Broome, J., Cramer, W., Christ, R., ... & Dubash, N. K. (2014). Climate change 2014: synthesis report. Contribution of Working Groups I, II and III to the fifth assessment report of the Intergovernmental Panel on Climate Change (p. 151). IPCC. ↩
-
Cochrane, L. (2011). Food security or food sovereignty: The case of land grabs. The Journal of Humanitarian Assistance, 5. ↩
-
A new way to curb nitrogen pollution: Regulate fertilizer producers, not just farmers. David Kanter. January 20, 2019. https://www.salon.com/2019/01/20/a-new-way-to-curb-nitrogen-pollution-regulate-fertilizer-producers-not-just-farmers_partner/ ↩
-
Belavina, E. (2020). Grocery store density and food waste. Manufacturing & Service Operations Management. ↩
-
Facilitate the Growth of Organic by Ending Subsidies for Chemical Inputs. Joelle Katto Andrighetto. October 10, 2018. ↩
-
Hamouchene, H. Extractivism and resistance in North Africa. November 2019. ↩
-
Hong, C., Mueller, N. D., Burney, J. A., Zhang, Y., AghaKouchak, A., Moore, F. C., ... & Davis, S. J. (2020). Impacts of ozone and climate change on yields of perennial crops in California. Nature Food, 1(3), 166-172. ↩
-
Johnson, T. (2016). Nitrogen nation: The legacy of World War I and the politics of chemical agriculture in the United States, 1916–1933. Agricultural History, 90(2), 209-229. ↩
-
Khan, S. A., Mulvaney, R. L., Ellsworth, T. R., & Boast, C. W. (2007). The myth of nitrogen fertilization for soil carbon sequestration. Journal of Environmental Quality, 36(6), 1821-1832. ↩
-
Kumar, R. R., & Cho, J. Y. (2014). Reuse of hydroponic waste solution. Environmental Science and Pollution Research, 21(16), 9569-9577. ↩
-
Prakash, S., & Verma, J. P. (2016). Global perspective of potash for fertilizer production. In Potassium solubilizing microorganisms for sustainable agriculture (pp. 327-331). Springer, New Delhi. ↩
-
Rulli, M. C., Saviori, A., & D’Odorico, P. (2013). Global land and water grabbing. Proceedings of the National Academy of Sciences, 110(3), 892-897. ↩
-
Schaffartzik, A., Mayer, A., Gingrich, S., Eisenmenger, N., Loy, C., & Krausmann, F. (2014). The global metabolic transition: Regional patterns and trends of global material flows, 1950–2010. Global Environmental Change, 26, 87-97. ↩
-
Schechinger, A. W., & Cox, C. Feeding the world: Think US agriculture will end world hunger? Think again. EWG; 2016. ↩
-
Strong Demand From Farmers For Crop-Boosting Potash Triggers A Mining Rush. Tim Treadgold. March 20, 2019. https://www.forbes.com/sites/timtreadgold/2019/03/20/strong-demand-from-farmers-for-crop-boosting-potash-triggers-a-mining-rush/#39d26f54436a ↩
-
Warnock, J. W. (2011). Exploiting Saskatchewan's Potash: Who Benefits?. CCPA-Saskatchewan Office. ↩
-
Why Rising Lithium Production Could Crush Fertilizer Stocks. Maxx Chatsko. August 9, 2017. https://www.fool.com/investing/2017/08/09/why-rising-lithium-production-could-crush-fertiliz.aspx ↩
-
Why Soil Matters. Renee Cho. April 12, 2012. https://blogs.ei.columbia.edu/2012/04/12/why-soil-matters/ ↩
-
World Food Situation: FAO Food Price Index. October 22, 2020. Retrieved from http://www.fao.org/worldfoodsituation/foodpricesindex/en/ ↩