Argos: Clustering

In it's current state, Argos is an orchestra of many parts:
argos- the core projectargos.cloud- the infrastructure deployment/configuration/management systemargos.corpora- a corpus builder for training and testingargos.cluster, nowgalaxy- the document clustering packageargos.iosandargos.android- the mobile apps
It's an expansive project so there are a lot of random rabbit holes I could go down. But for now I'm just going to focus on the process of developing the clustering system. This is the system which groups articles into events and events into stories, allowing for automatically-generated story timelines. At this point it's probably where most of the development time has been spent.
Getting it wrong: a lesson in trying a lot
When I first started working on Argos, I didn't have much experience in natural language processing (NLP) - I still don't! But I have gained enough to work through some of Argos's main challenges. That has probably been one of the most rewarding parts of the process - at the start some of the NLP papers I read were incomprehensible; now I have a decent grasp on their concepts and how to implement them.
The initial clustering approach was hierarchical agglomerative clustering (HAC) - "agglomerative" because each item starts in its own cluster and are merged sequentially by similarity (the two most similar clusters are merged, then the next two similar clusters are merged, etc), and "hierarchical" because the end result is a hierarchy as opposed to explicit clusters.
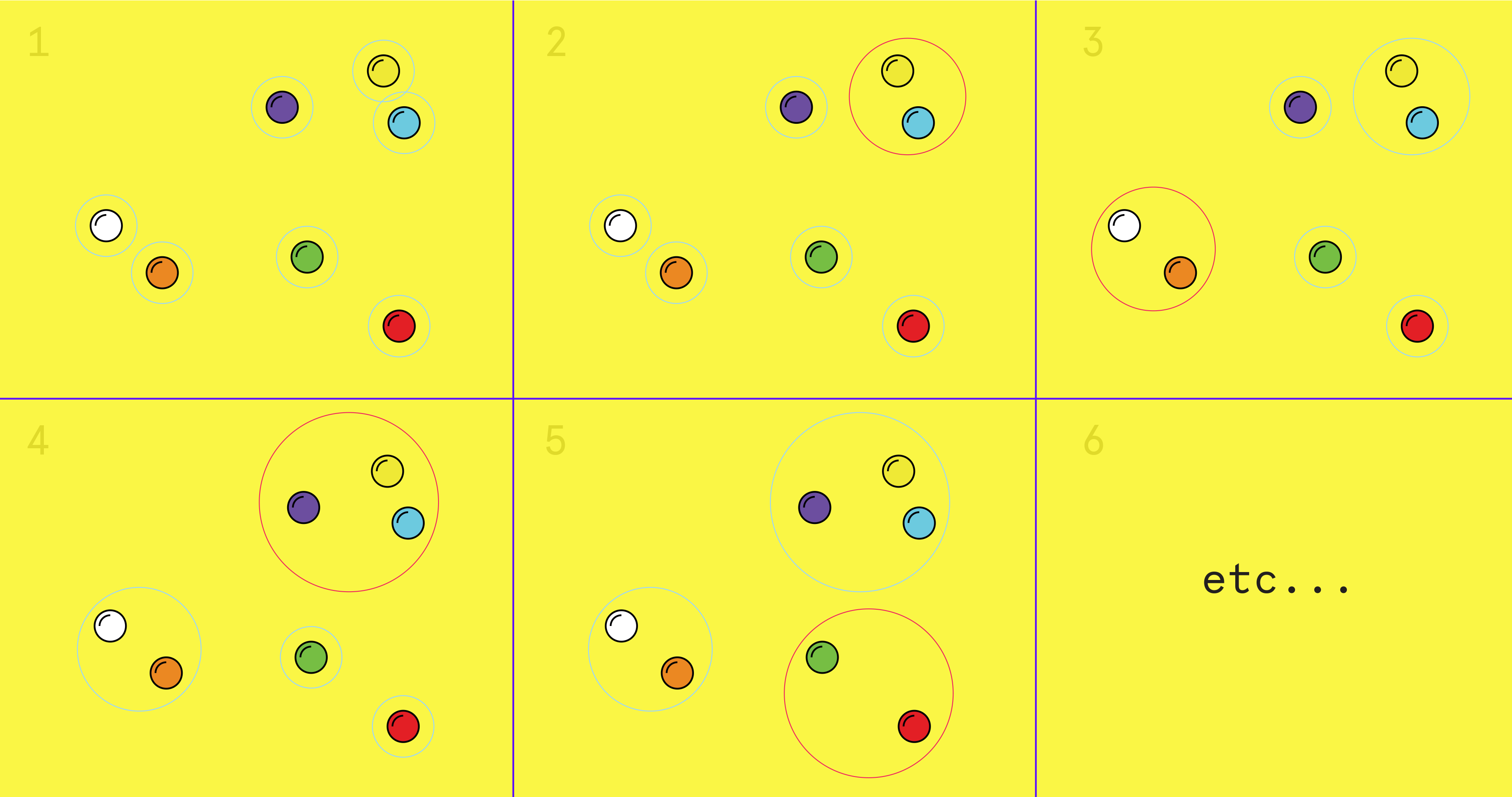
Intuitively it seemed like a good approach - HAC is agnostic to how similarity is calculated, which left a lot of flexibility in deciding what metric to use (euclidean, cosine, etc) and what features to use (bag-of-words, extracted entities, a combination of the two, etc). The construction of a hierarchy meant that clustering articles into events and clustering events into stories could be accomplished simultaneously - all articles would just be clustered once, and the hierarchy would be snipped at two different levels: once to generate the event, and again at a higher level to generate the stories.
Except I completely botched the HAC implementation and didn't realize it for waaay too long. The cluster results sucked and I just thought the approach was inappropriate for this domain. To top it off, I hadn't realized that I could just cluster once, snip twice (as explained above), and I was separately clustering articles into events and events into stories. This slowed things down a ton, but it was already super slow and memory-intensive to begin with.
Meanwhile I focused on developing some of the other functionality, and there was plenty of that to do. I postponed working on the clustering algorithm and told myself I'd just hire an NLP expert to consult on a good approach (i.e. I may never get around to it).
A few months later I finally got around to revisiting the clustering module. I re-read the paper describing HAC and then it became stunningly obvious that my implementation was way off base. I had some time off with my brother and together we wrote a much faster and much simpler implementation in less than an hour.
But even with that small triumph, I realized that HAC had, in this form, a fatal flaw. It generates the hierarchy in one pass and has no way of updating that hierarchy. If a new article came along, I had no choice but to reconstruct the hierarchy from scratch. Imagine if you had a brick building and the only way you could add another brick was by blowing the whole thing up and relaying each brick again. Clustering would become intolerably slow.

I spent awhile researching incremental or online clustering approaches - those which were well-suited to incorporating new data as it became available. In retrospect I should have immediately begun researching this kind of algorithm, but 6 months prior I didn't know enough to consider it.
After some time I had collected a few approaches which seemed promising - including one which is HAC adapted for an incremental setting (IHAC). I ended up hiring a contractor (I'll call him Sol) who had been studying NLP algorithms to help with their implementation (I didn't want to risk another botch-implementation). Sol was fantastic and together we were able to try out most of the approaches.
IHAC was the most promising and is the one I ended up going with. It's basically HAC with a modifiable hierarchy. The hierarchy can take a new piece of data and minimally restructure itself to incorporate it.
I rewrote Sol's implementation (mainly to familiarize myself with it) and started evaluating it on a test data, trying to narrow down a set of parameters well-suited for news articles. It was pretty slow so I tried to parallelize it, but just a second process was enough to run into memory issues. After some profiling and rewriting of key memory bottlenecks, memory usage was reduced 75-95%! So now certain parts could be parallelized. But it still was quite slow, mainly because it was built using higher-level Python objects and methods.
I ended up rewriting the implementation again, this time moving as much as I could to numpy and scipy, very fast scientific computing Python libraries where a lot of the heavy lifting is done in C. Again, I saw huge improvements - the clustering went something like 12 to 20 times faster!
Of course, there were still some speedbumps along the way - bugs here and there, which in the numpy implementation were a bit harder to fix. But now I have a solid implementation which is fast, memory-efficient, persistent (using pytables), and takes full advantage of the algorithm's hierarchical properties (getting events and stories in just two snips).
For the past few days Argos has been in a trial period, humming on a server collecting and clustering articles, and so far it has been doing surprisingly well. The difference between the original implementation and this new one is night and day.
At first Argos was only running on world and politics news, but today I added in some science, tech, and business news sources to see how it will handle those.
It was a long and exhausting journey, but more than anything I'm happy to see that the clustering is working well and quickly!