Conspiracy Generator
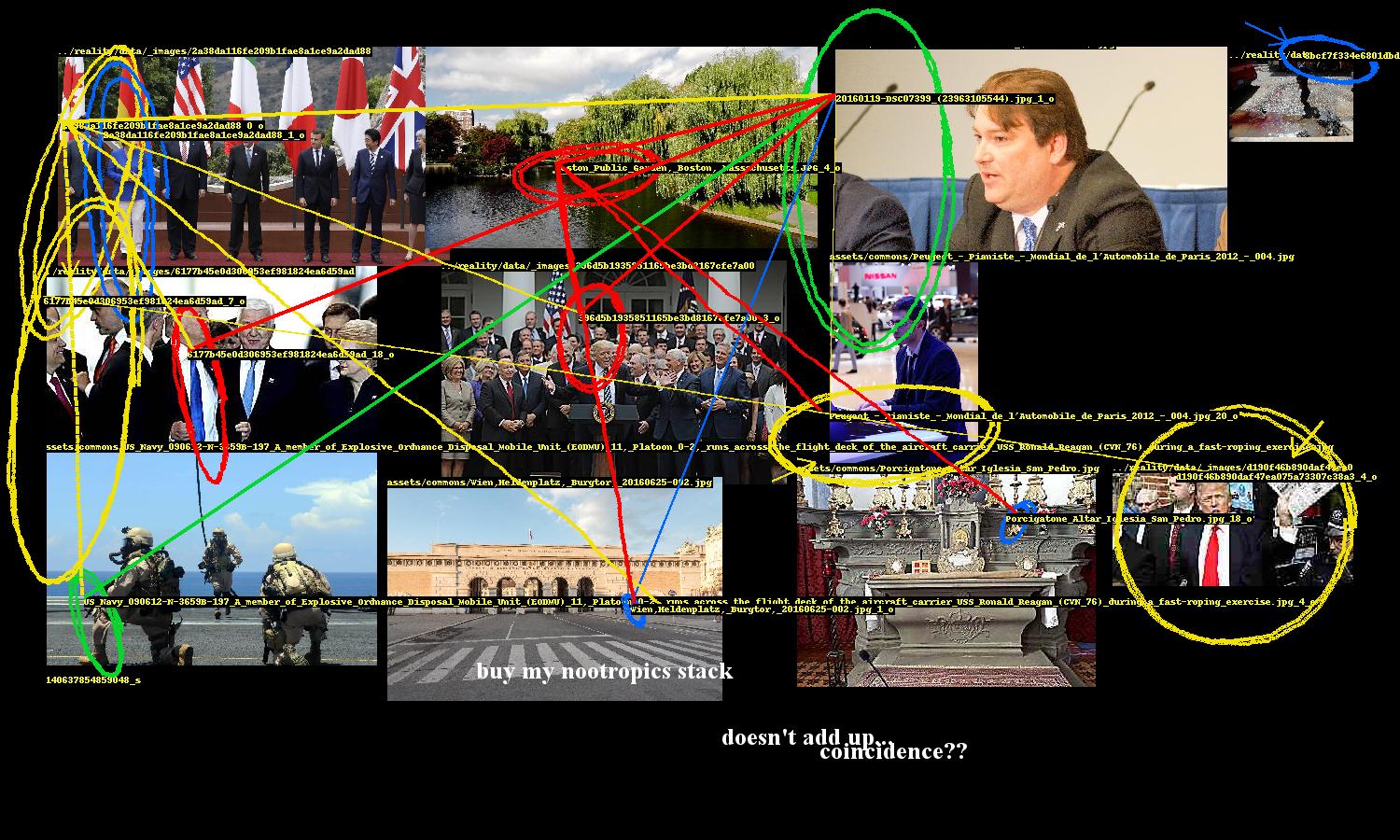
I recently wrote a conspiracy-generating bot for The New Inquiry’s Conspiracy issue. The basic premise is that far-fetched conspiracy theories emerge from the human tendency for apophenia - finding meaning in random patterns - and that the problematic algorithm-level aspects of machine learning are instances of a similar phenomenon. The bot leverages how computer models can misidentify faces and objects as similar and presents these perceptual missteps as significant discoveries, encouraging humans to read additional layers of absent meaning.
The bot consists of the following core components:
- object recognition (using the YOLO darknet model, ported to TensorFlow)
- face detection (using dlib’s HOG face detection) and comparison (using facenet)
- text recognition/OCR (using tesseract)
- image manipulation and annotation (using Pillow), including “hand-drawn” scrawlings
- image layout (i.e. bin packing)
- perceptual hashing (to compute image similarity)
- image sourcing, via sampling Wikimedia Commons image dumps and news articles (using reality, which I’ll explain in a bit)
In this post I’ll give a high-level explanation for the basic structure of the bot. If you’re interested in details, the full source code is available here.
Sourcing images, the material of conspiracy
For this bot the ideal conspiracy is one that connects seemingly unrelated and distance events, people, and so on not only to each other but across time. If that connection is made to something relevant to the present, all the better. The bot’s source material then should combine obscure images with a lot of breadth (encompassing paintings, personal photos, technical drawings, and the like) with immediately recognizable ones, such as those from recent news stories.
Wikimedia Commons is perfect for the former. This is where all of Wikipedia’s (and other Wiki sites’) images are hosted, so it captures the massive variety of all those platforms. Wikimedia regularly makes full database dumps available, including one of all of the Commons’ image links (commonswiki-latest-image.sql.gz). Included in the repo is a script that parses these links out of the SQL. The full set of images is massive and too large to fit on typical commodity hard drives, so the program provides a way to download a sample of those images. As each image is downloaded, the program runs object recognition (using YOLO; “people” are included as objects) and face detection (using dlib), saving the bounding boxes and crops of any detected entities so that they are easily retrieved later.

For recent news images the bot uses reality, a simple system that polls several RSS feeds and saves new articles along with their main images and extracted named entities (peoples, places, organizations, and so on). When new articles are retrieved, reality updates a FIFO queue that the bot listens to. On new articles, the bot runs object recognition and face detection and adds that data to its source material, expanding its conspiratorial repertoire.
Each of these sources are sampled from separately so that every generated conspiracy includes images from both.
At time of writing, the bot has about 60,000 images to choose from.
Generating conspiracies
To generate a conspiracy, 650 images are sampled and their entities (faces and objects) are retrieved. The program establishes links between these entities based on similarity metrics; if two entities are similar enough, they are considered related and included in the conspiracy.

The FaceNet model used to compute face similarity. For objects, a very naive approach is used: the perceptual hashes of object crops are directly compared (perceptual hashes are a way of “fingerprinting” images such that images that look similar will produce similar hashes).
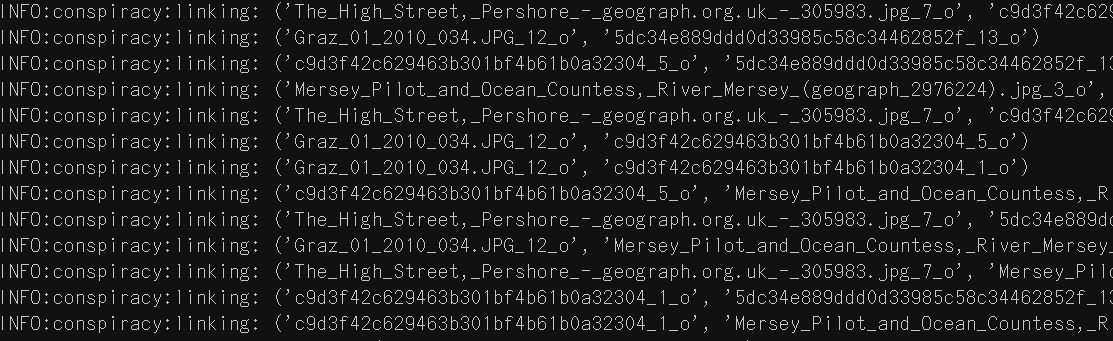
Because reality saves a news article’s text along with its image, we can also search through that text and its extract entities to pull out text-based conspiracy material. The program starts by looking for a few simple patterns in the text, e.g. ENTITY_A is ... ENTITY_B, which would match something like Trump is mad at Comey. If any matches are found, a screenshot of the article’s page is generated. Then optical character recognition (OCR) is run on the screenshot to locate one of those extracted phrases. If one is found, a crop of it is saved to be included in the final output.
This network of entity relationships forms the conspiracy. The rest of the program is focused on presentation.
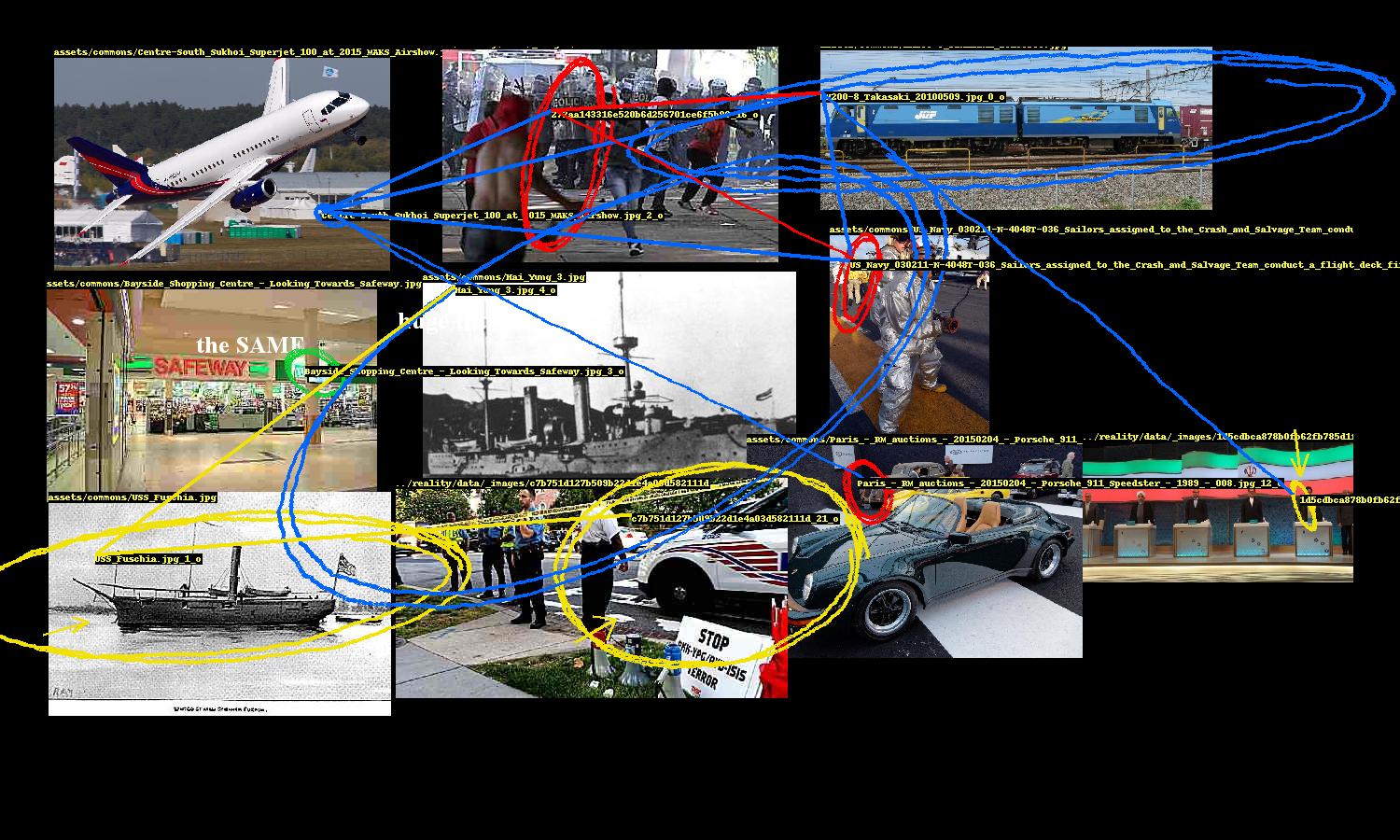
Image layout and annotation
Once relationships between faces and objects are established, the next challenge is to present the implicated images in a convincingly conspiratorial way. This problem breaks down into two parts: image 1) layout and 2) annotation.
1) Layout
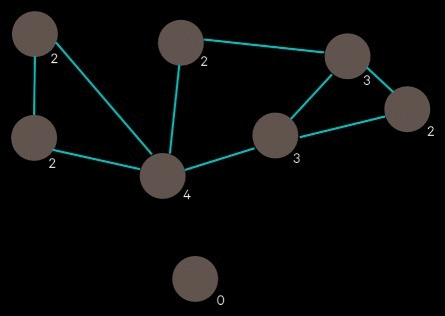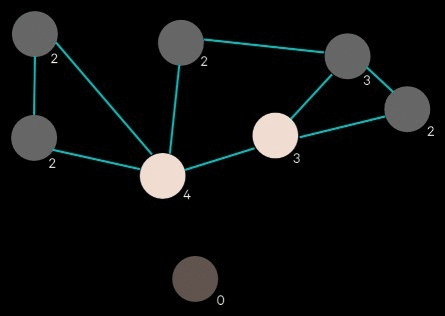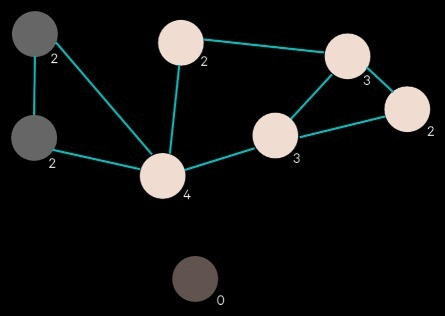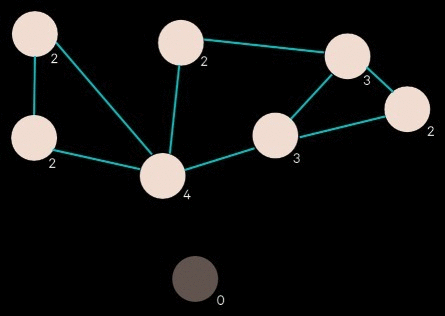
Layout is tricky because it’s a bin packing problem, which is NP-hard, but fortunately there exists implementations of good solutions, such as rectpack, which is used here. There is no guarantee that all of the selected images will fit, so there is some additional processing to ensure that the images that do get included have a maximal amount of connectivity between them.
The generated network of entity relationships forms a graph of the selected images. Two images have an edge between them if at least one pair of their entities are linked. We start with the image that has the highest degree (i.e. the image that is connected to the most other images). We look at what images its connected to and pick the image with the highest degree out of those, and repeat. The result is a sequence of connected images, descending by degree.
Here’s where some style is added. Images are not placed exactly as prescribed by the bin packing algorithm; there is some “shakiness” where they are placed with some margin of error. This gives the layout a rushed, haphazard look, enhancing the conspiracy vibe.
2) Annotation
A conspiracy’s entities need to be highlighted and the links between them need to be drawn. While Pillow, Python’s de facto image processing library, provides ways to draw ellipses and lines, they are too neat and precise. So the program includes several annotation methods to nervously encircle these entities, occasionally scrawl arrows pointing to them, and hastily link them.
These were fun to design. The ellipse drawing method uses an ellipse function where the shape parameters a, b are the width and height of the entity’s bounding box. The function is rotated to a random angle (within constraints) and then the ellipse is drawn point by point, with smooth noise added to give it an organic hand-drawn appearance. There are additional parameters for thickness and how many times the ellipse should be looped.

This part of the program also includes computer text, which are randomly sampled from a set of conspiracy clichés, and also writes entity ids on the images.

Further manipulation
Images are randomly “mangled”, i.e. scaled down then back up, unsharpened, contrast-adjusted, then JPEG-crushed, giving them the worn look of an image that has been circulating the internet for ages, degraded by repeat encodings.

Assembling the image
Once all the images are prepared, placed, and annotated, the final image is saved and added to the webpage.
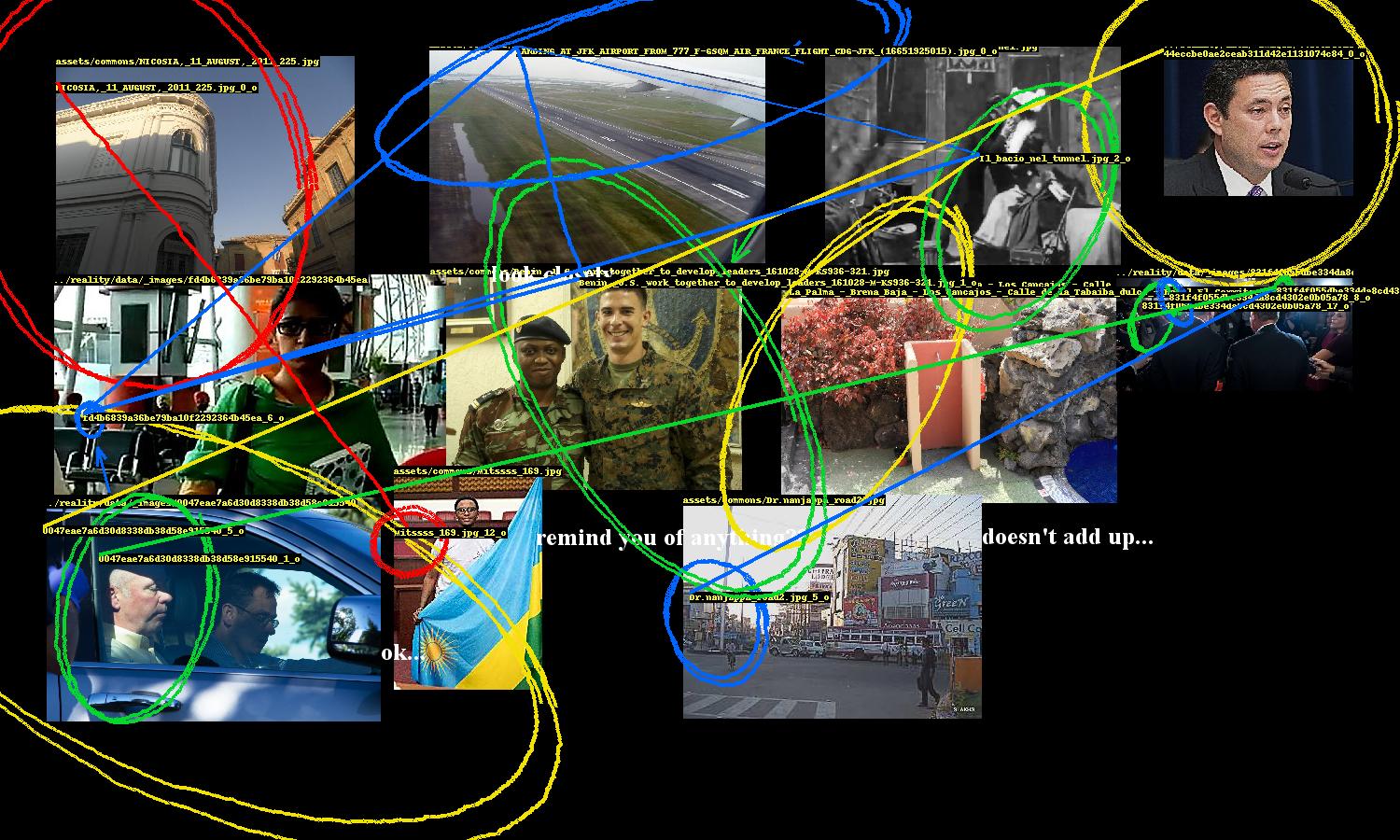
There you have it - an algorithm for conspiracies.