Research Tools
My fellowship at the Jain Family Institute involves a lot of reading and research across various sources: typically papers in the form of PDFs, articles on my phone browser, and ePub books.
Prior to the fellowship the research I did was spontaneous and infrequent enough that my ad hoc system of typing out highlights by hand into a one or more markdown files and sorting through them manually worked alright. But now that I’m dealing with many, many more pages of research, this system has become kind of unwieldy.
Here I’ll go over the tools I’ve built over the past couple years (most within the past year) to make this process more manageable. They are mostly meant to address a few key pain points:
- Aggregating highlights from across several platforms (phone, desktop, and eReader) into a central repository
- Capturing charts and other graphics
- Tagging and organizing highlights
- Generating footnotes
These tools are still new–I’m still testing and tweaking them–so they don’t quite link up as well as they should. Eventually they’ll likely be grouped into a single tool, but that might not be for awhile.
Setup
Basically all of my reading happens on either my phone (Android), my laptop, or my eReader (a Kobo). Documents are either web articles (phone and laptop), PDFs (laptop1), or ePubs (eReader). I’ll occasionally print out PDFs, especially if I’m having a hard time focusing on the laptop.
The last pieces of the setup are vim, which I use to take notes and save highlights, and Firefox (though everything here would work fine for Chrome/Chromium).
eReader
The eReader is the most straightforward. Kobo readers have a built-in function for highlighting and annotating text. I haven’t really tested if this works for images though.
The highlighting and annotating functions work smoothly for the proprietary Kobo .kepub format, which books from the Kobo store come in. For .epub books, the highlighting is atrociously slow and finicky. Fortunately, .epub files can be converted to .kepub with kepubify.
Kobo eReaders store highlights and annotations in a SQLite database. I have a script which exports rows from this database to a JSON file, and another script that lets you easily mount and run this script when you plug your Kobo into your laptop.
Web articles
Copy and paste
On the desktop, saving text web articles are also straightforward: copy and paste. When text from a web article is copied, it’s saved in your system clipboard as both plain text and as HTML. When pasting into vim, only the plain text is pasted. Sometimes it’s helpful for me to have the HTML pasted–to preserve links, for example–but as markdown instead (since my notes are in markdown files).
I have a tool called nom I developed to make managing markdown files easier. One function it has is nom clip, which takes HTML saved in the system clipboard, converts it to markdown, and then prints it out.
In my vim configuration file for markdown files (~/.vim/ftplugin/markdown.vim) I bound <leader>c to call this function, prepend > to each line (which defines a blockquote in markdown), and then output it into vim2:
" easily paste html clipboard content as quoted markdown function! PasteQuotedHTML() augroup AsyncGroup autocmd! autocmd User AsyncRunStop normal P augroup END call asyncrun#run("!", "", "nom clip | sed 's/^/> /' | xsel -bi") endfunction nnoremap <leader>c :call PasteQuotedHTML()<cr>
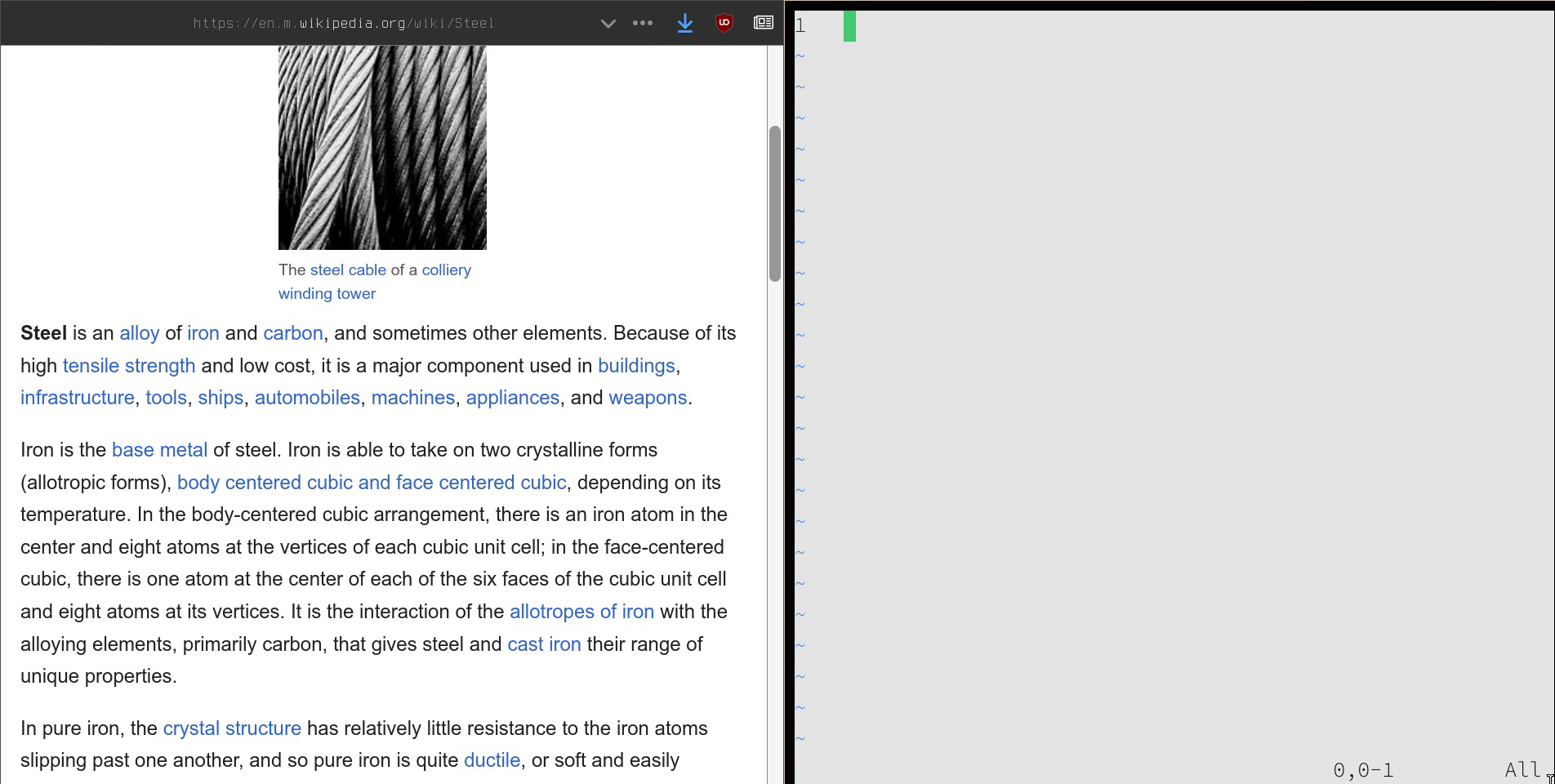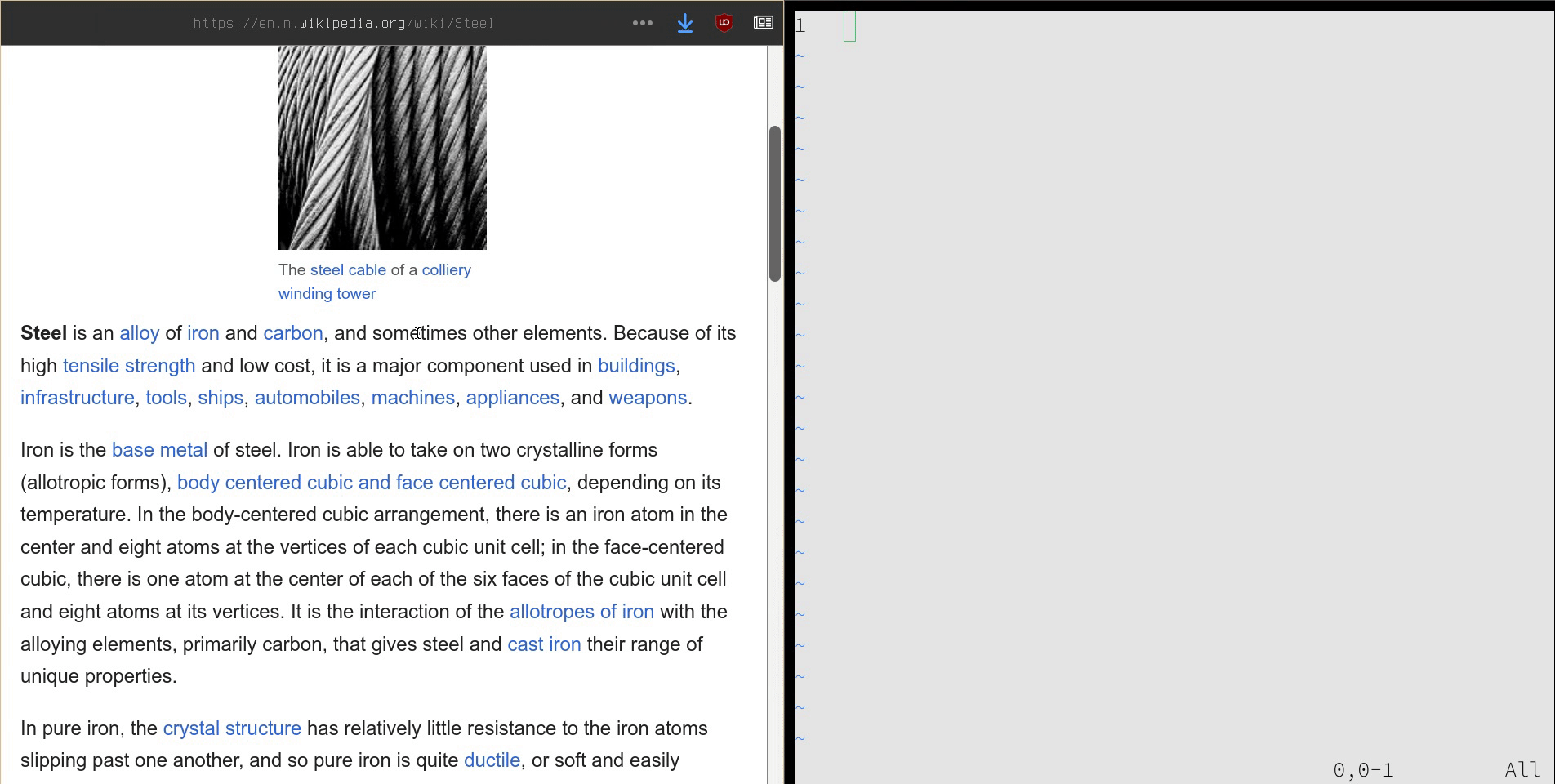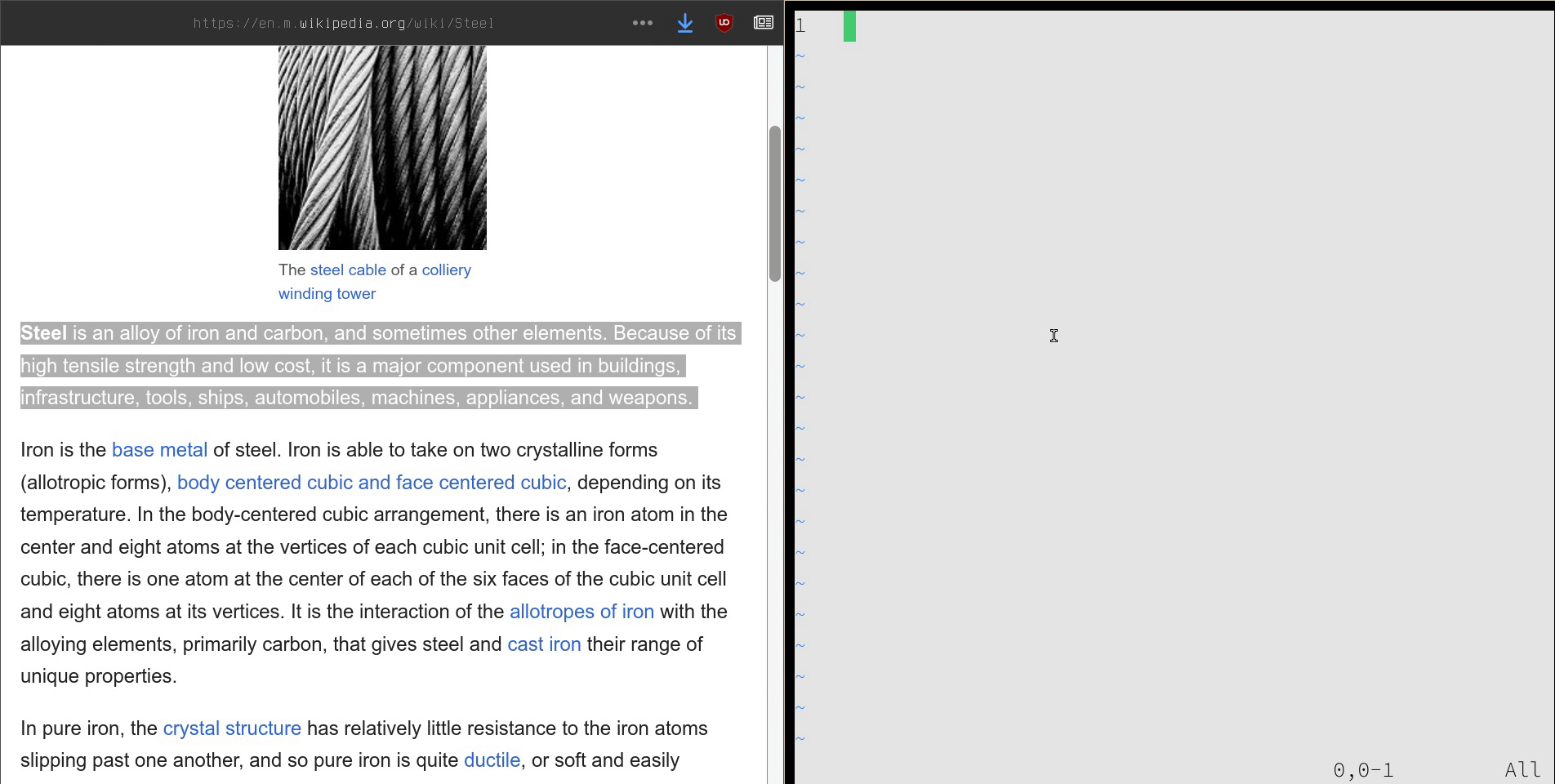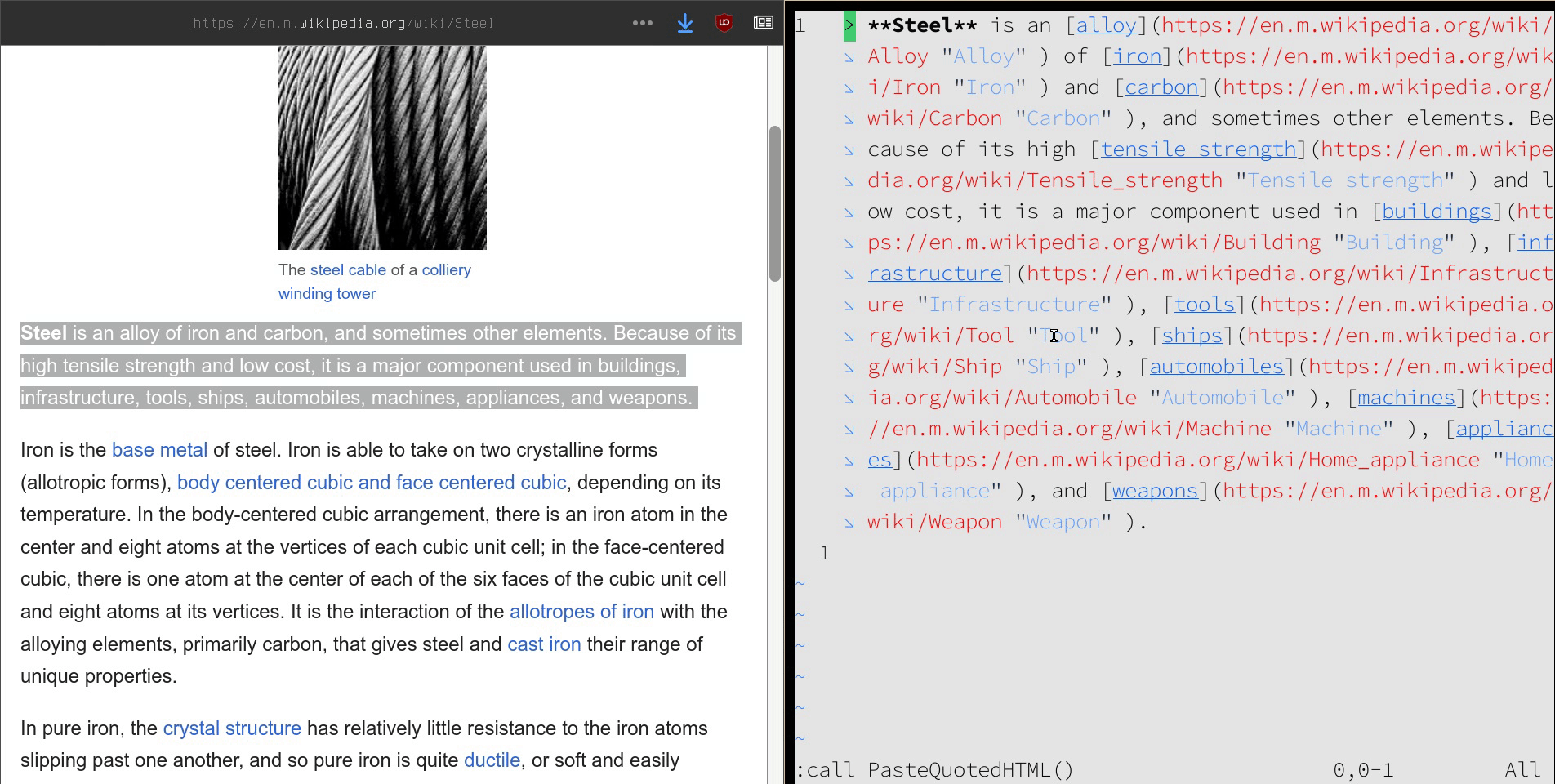
Mobile
Highlighting on phones is less straightforward. I briefly tried copying highlights into an email, sending it to myself, then copying it into a markdown file when I got to my laptop, but this ended up being too complicated and unpleasant.
I wrote a web extension called hili (for Firefox, but should work for Chrome in theory) that streamlines this. With hili, you select text or an image on a webpage, select “Highlight”, and then a tag prompt comes up. Enter the tags and save the highlight, and the selected text or image data, along with some metadata about the page (url, title), is sent to a server that appends the data to a JSON file. The goal here was a very fire-and-forget, uninterrupting way of highlighting that is easy to search through later.
One snag is that this requires a server to communicate with. I run the application on my personal server, but I’m often reading on the subway where there’s only an intermittent internet connection. For awhile this meant I’d be reading an article and come across something I’d want to save, but have to wait until the next subway stop for the internet connection to come back. Now hili queues highlights locally (indicated by the yellow box below) until an internet connection is detected, at which point the local highlights are synchronized with the server.

hili also helped with an anxiety of mine: I’d procrastinate reading articles that sounded especially interesting because I was worried about forgetting its contents. With hili I can save highlights without much thought, and this is less of a worry.
PDFs
PDF is a horrible format. It’s really not meant for reading on computers…but we do it anyways. Copy and pasting from text from a PDF will result in weird line breaks, there are often broken words (hyphenated) because the text is frequently justified, and is not particularly precise in selecting the text you want.
For a long time I’d either 1) copy the PDF text and manually fix line breaks, broken words, and delete extraneous text; or 2) manually type in whatever I wanted to highlight. Even though it probably takes longer, I usually went with the latter–it just felt faster than jumping around correcting little errors.
Fortunately, the copy-and-paste errors are consistent enough that a lot of the cleanup can be automated, which is what this script does. This feels small, but ends up being a huge time saver. Like with HTML pasting, I added a function to my vim configuration (same file as before), bound to <leader>d, which automatically applies this processing to text in the system clipboard:
" easily paste pdf clipboard content as quoted markdown function! PasteQuotedPDF() augroup AsyncGroup autocmd! autocmd User AsyncRunStop normal P augroup END call asyncrun#run("!", "", "xsel -b | ~/.bin/pdfpaste | sed 's/^/> /' | xsel -bi") endfunction nnoremap <leader>d :call PasteQuotedPDF()<cr>
It’s not perfect though. The heuristics used to clean up the text can hit false positives, as in the demo below (“European-derived” is collapsed to “Europeanderived” because the script takes all hyphenations at the end of lines to be word breaks).

Some PDFs are scans of books or articles. These are basically just images, so highlighting text usually doesn’t work with them. If you’re lucky, the scans will have been OCR’d and there will be selectable text. However, the OCR quality can vary; sometimes you’ll copy in PDF text and have to manually correct errors, which can be tedious. Still, better than manually typing in everything.
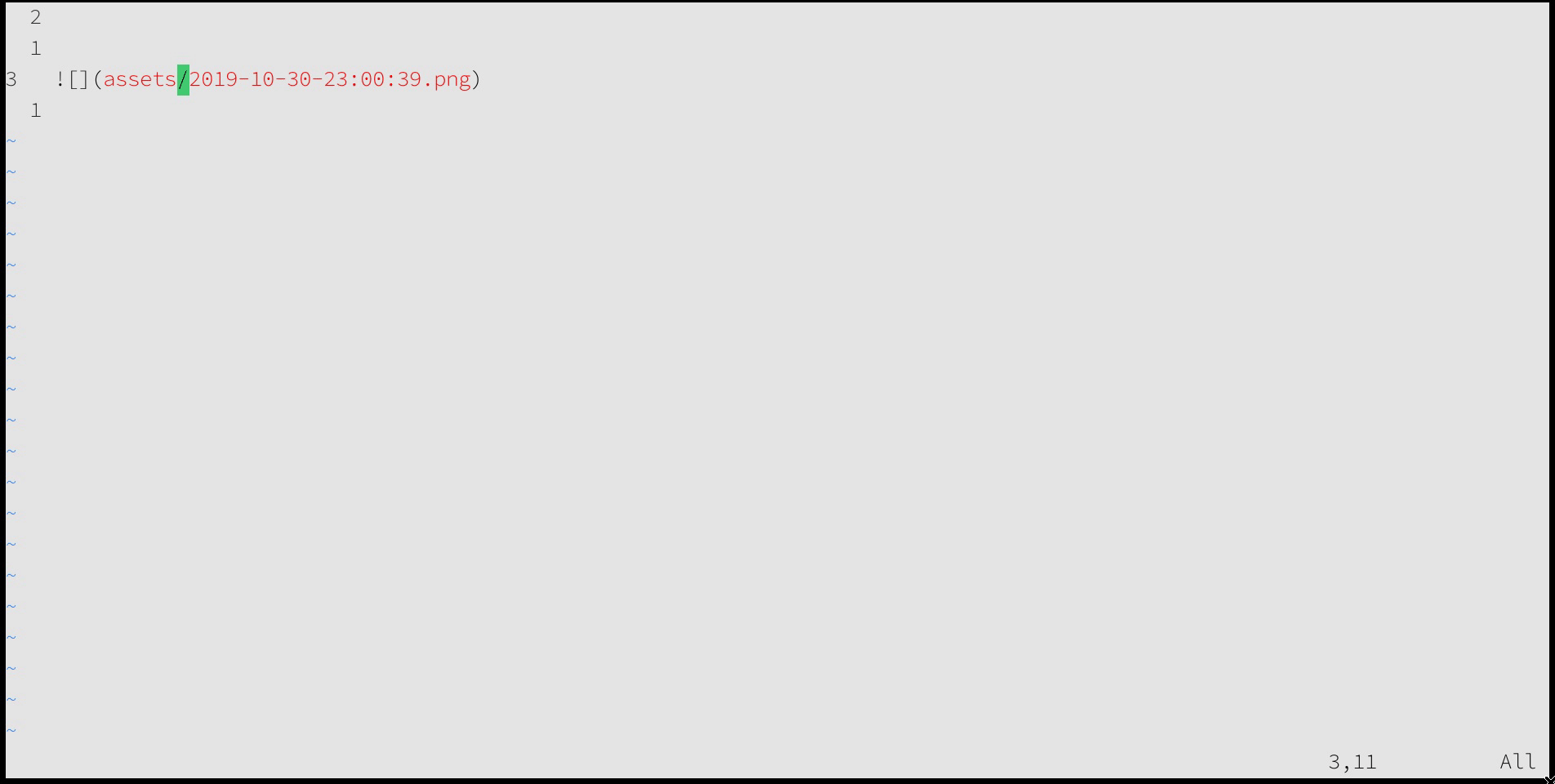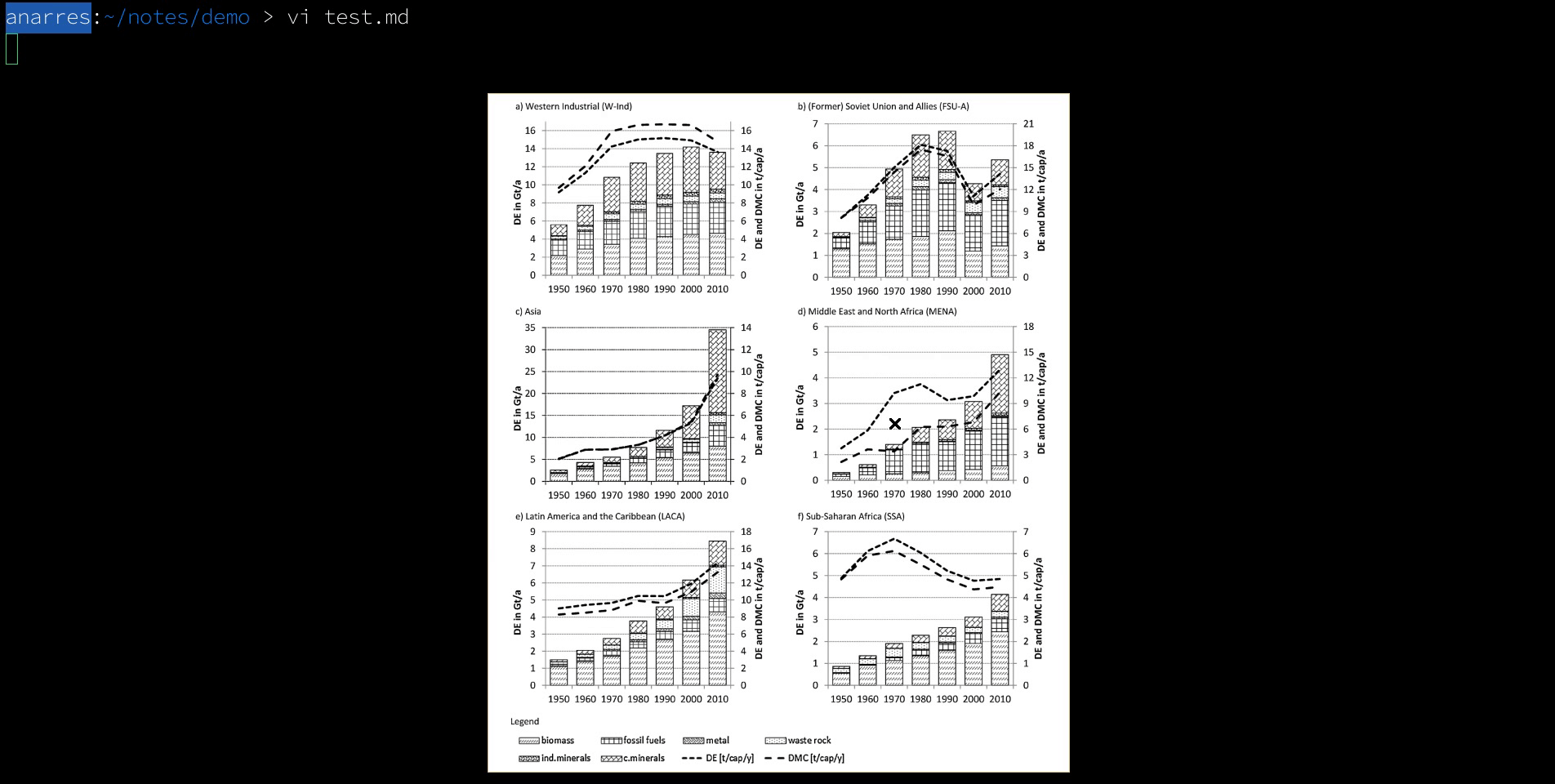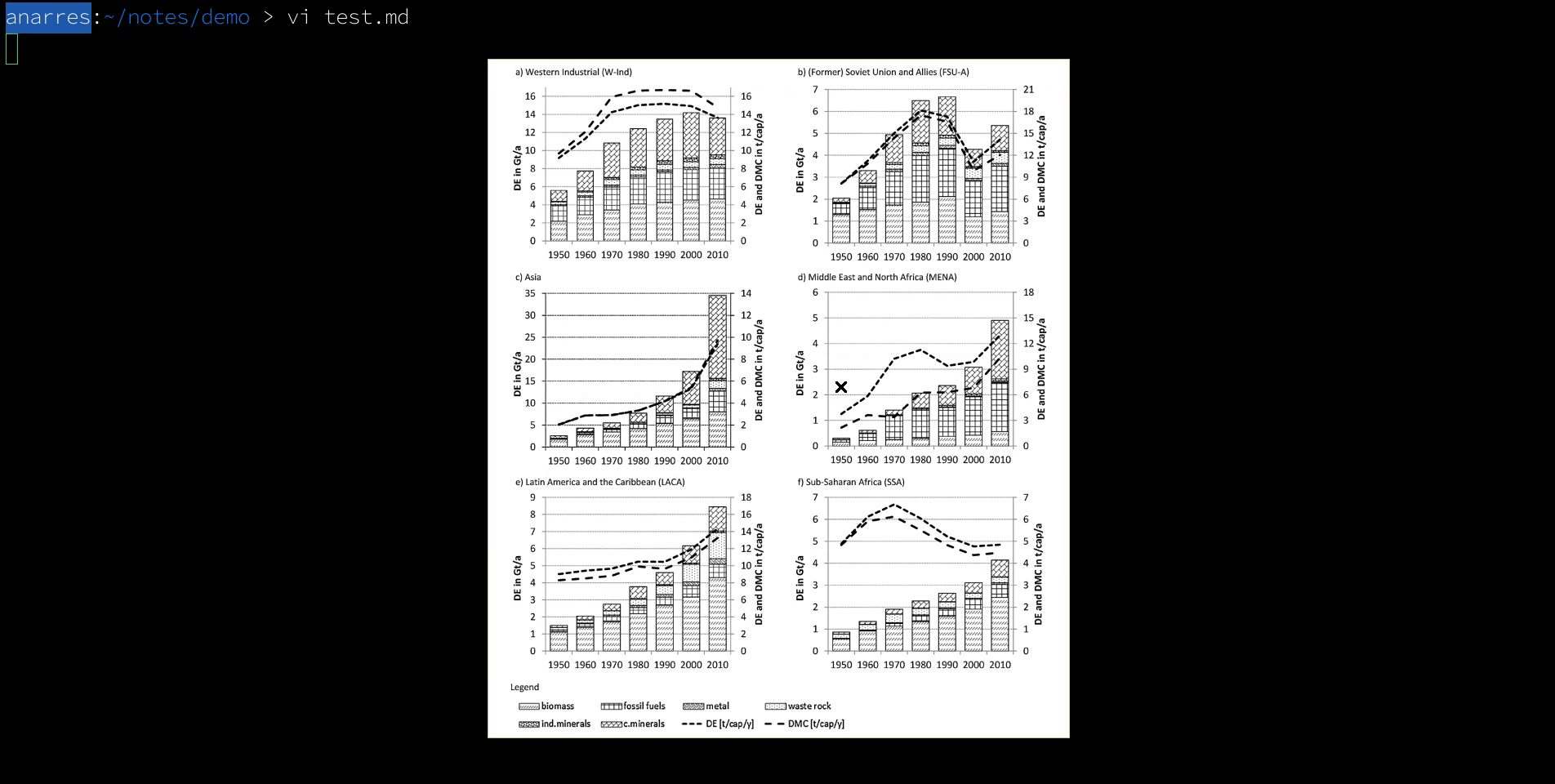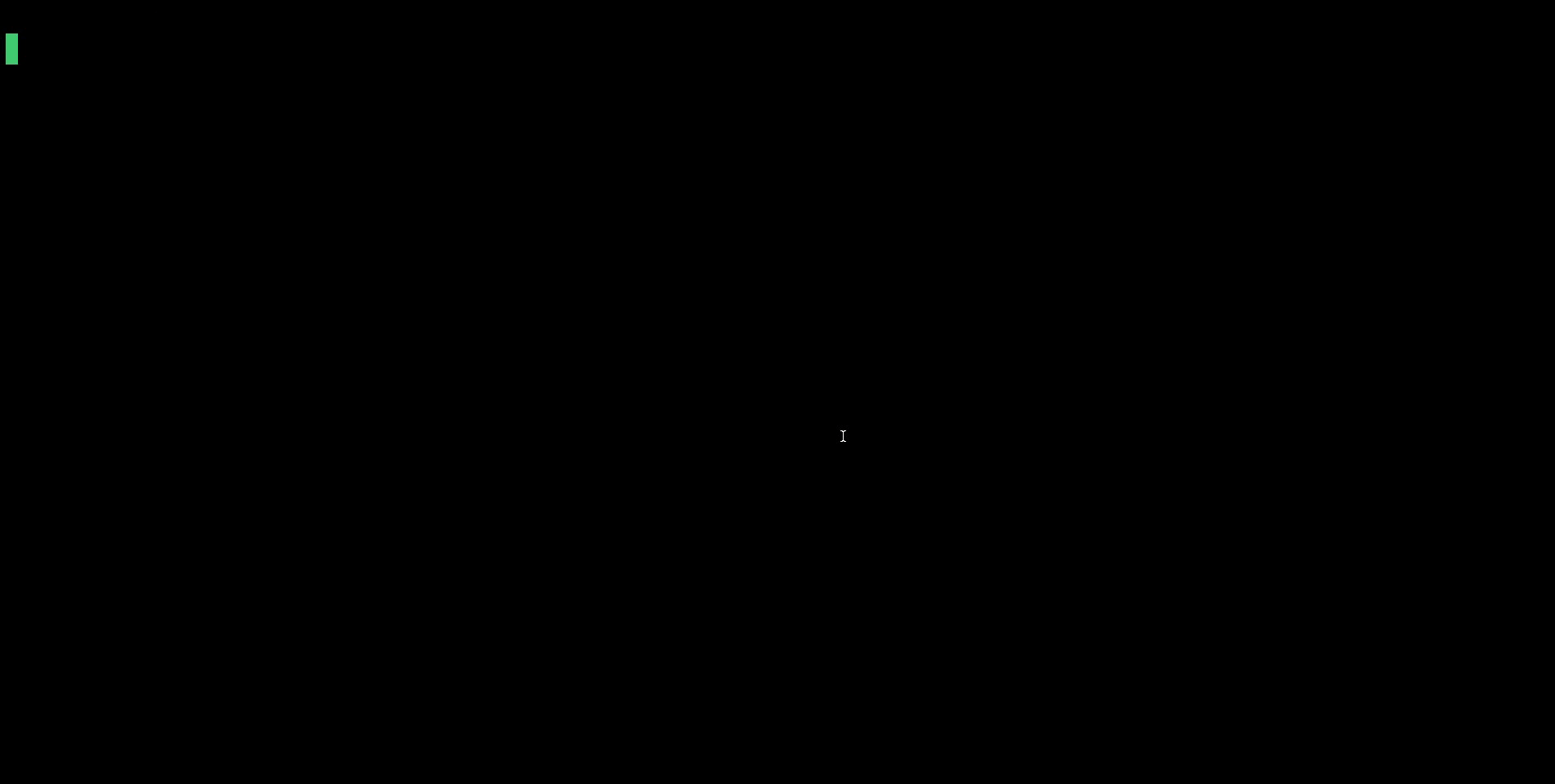
In any case, what’s to be done for graphics in PDFs? I have a simple script for taking screenshots which dumps them into a folder (~/docs/shots/). I added another function to my vim configuration (same file as before) that automatically moves this to a folder called assets (relative to the current markdown file) and then drops in the markdown syntax for the image:
" screenshot, move to assets folder, paste in markdown nnoremap <leader>s "=system("fpath=$(shot region <bar> tail -n 1); fname=$(basename $fpath); mv $fpath assets/$fname; echo ''")<CR>P
And finally, another vim function lets me easily view the image with gx:
" open markdown syntax urls " open local images with feh " open local gifs with gifview function! OpenUrlUnderCursor() let l:lnum = line('.') let l:line = getline(l:lnum) let l:coln = col('.') let l:lcol = l:coln while l:line[l:lcol] != '(' && l:line[l:lcol] != '<' && l:lcol >= 0 let l:lcol -= 1 endwhile let l:rcol = l:coln while l:line[l:rcol] != ')' && l:line[l:rcol] != '>' && l:rcol <= col("$")-1 let l:rcol += 1 endwhile let l:obj = l:line[l:lcol + 1: l:rcol - 1] let l:url = matchstr(l:obj, '\(http\|https\):\/\/[^ >,;]*') let l:img = matchstr(l:obj, '[^<>()]\+\.\(jpg\|jpeg\|png\|gif\)') if l:url != '' call netrw#BrowseX(l:url, 0) elseif l:img != '' if matchend(l:img, 'gif') >= 0 silent exec "!gifview -a '".l:img."'" | redraw! else silent exec "!feh --scale-down '".l:img."'" | redraw! endif else echomsg 'The cursor is not on a link.' endif endfunction nnoremap gx :call OpenUrlUnderCursor()<cr>
Tagging and sorting
The final piece is the most recent addition: a tool for quickly going through highlights and tagging bits of text. When I’m in the middle of research, I’m using dumping pretty large chunks of text into my notes file, without worrying too much about annotating or tagging it. Early on in the research I’m often not really sure what’s relevant, or how a particular highlight fits into the broader topic or questions I’m interested in.
At the end, however, I’m left with hundreds of pages of text chunks that I need to go through and sort. I used to go through all of these highlights and repeat the copy-and-pasting process, just with smaller chunks of text organized into tag groups. It was an extremely slow process.
Now I have grotto3, which renders these notes as HTML, and provides a very quick interface to select and tag text and images. This information is all saved into a CSV file that can easily be processed later.
As a bonus, since the tags and annotations are well-structured, grotto can automatically organize these selections into an outline (well, tag groupings) and generate markdown footnotes.

Future work
Right now these various tools don’t really talk to each other, and they dump their data in different locations and in somewhat different formats. In the future these formats would be harmonized and another tool would be built to quickly explore and search through them. Until then, it’s a manual process.
I’ve also been curious to try mind maps as a way to organize research. grotto could help with this by auto-generating a mind map based on tag co-occurrence, but I haven’t given it a try yet. Even so, there’s something to be said for the tactile experience of organizing information on paper, so an automatic system might not be ideal.
Honorary mention: signal-daemon

A tool that isn’t directly related to highlighting or annotating text but is worth mentioning is signal-daemon, which is a very simple script that lets you “text” notes to another number you register with Signal (e.g. a Google Voice number), and then downloads those texts to a markdown file on your computer. I use this to write down random thoughts, in general, but also on whatever topic I’m researching.
I tried reading PDFs on my phone and found it too straining. I did however put together a script that extracts highlights and annotations for MoonReader, available here.
This uses the asyncrun plugin.
There were a lot of challenges setting up the tag highlighting interactions, mostly to do with the DOM model having a tree structure and edge cases involving overlapping or nested tag highlights…happy to go more into it if it’s of interest to anyone.