Fugue Devlog 27: Good progress
I’m still working on Fugue. Funnily I had a draft update post exactly a year ago that I never finished, but this post is almost 2 years after the last one. A lot of preparatory progress has been made: characters and major plot points are starting to come together, and the whole production tooling/process is much further along.
Verses: Rust to C#
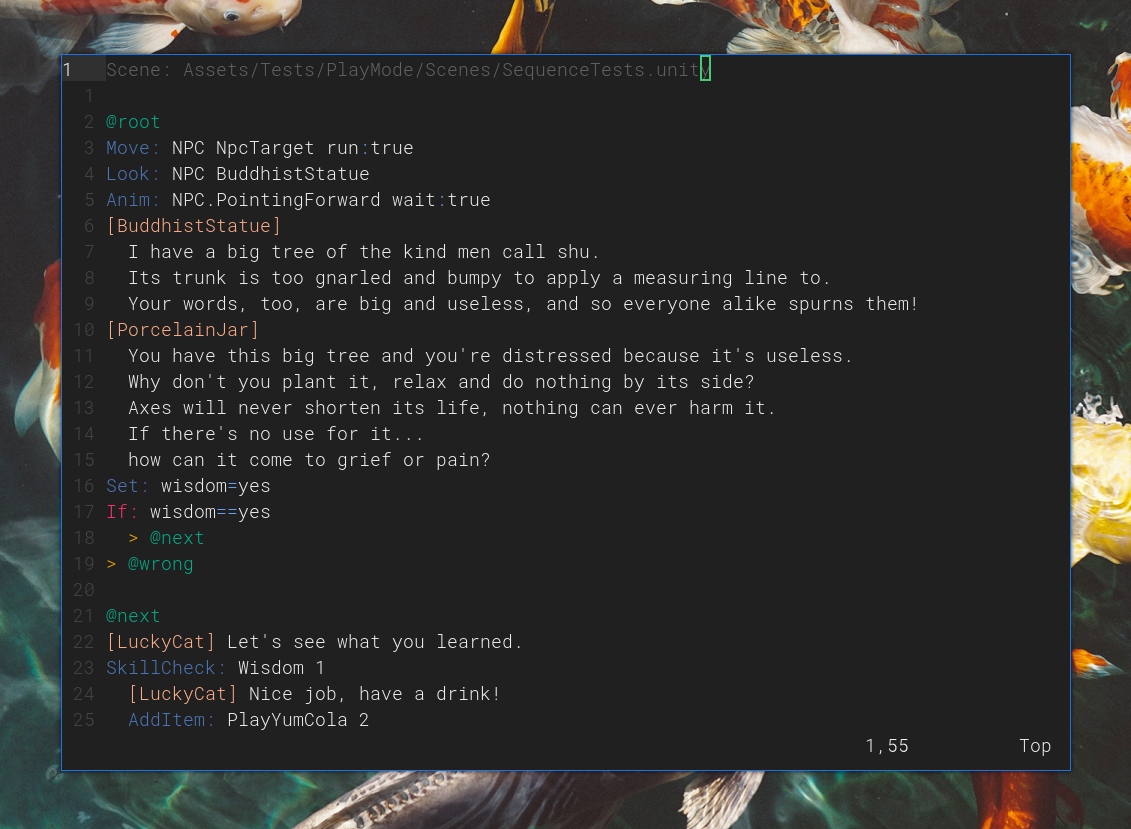
I’m trying to keep the core game logic outside of Unity/C# and move as much as possible into Rust, a language I’m more comfortable with. So I rewrote the Verses/Garland system, which is the scripting system (as in dialogue scripts) that manages most of the game state, into Rust and generated an FFI for it using uniffi (and its C# bindings generator). It’s just a lot easier for me to maintain and make changes. A few notes:
- I am a bit concerned about possible issues building Rust code for console platforms, but I’ll worry about that later.
- There’s a bit of plumbing required to wire up the library to Unity, but it’s not too bad.
- One minor annoyance is that Unity requires a full restart to load any changes to the library, though as the library stabilizes this should be less of a problem.
- Debugging is more complicated, and as far as I know there’s no way to hook into Unity’s logging system, so I log to a file instead.
- The generated code is for C# 12, while Unity supports only C# 9, so some unsightly post-processing is required to make the generated bindings Unity-compatible, but again it’s not too bad.
- There’s additional overhead calling over an FFI boundary, but I expect it to be negligible here.
So far this approach has been fine in terms of trade-offs. There’s also something nice about having a strict boundary between the “game environment” code and logic and a much more strongly enforced “single source of truth” in terms of the game state. But more complications could easily come up as I get more into writing the game’s scripts, so we’ll see.
Stagecraft: Blender to Unity
Similar to the Rust/C# divide I’m also trying to keep as much scene-building outside of Unity as possible. I find Blender a lot nicer to work with and it’s of course much more powerful for modeling, texturing, and so on. But it doesn’t have analogues to Unity’s components/MonoBehaviours, so there’s no clear way to represent the dynamic behavior necessary for a game. And many of Blender’s powerful features, like procedural textures, aren’t directly exportable to Unity.
To solve these issues I wrote a custom Blender add-on, Stagecraft. Where possible this add-on uses existing functionality, e.g. Blender’s baking system can be used for procedural textures. But what about game component behaviors? In my case I have a relatively small set of fixed behaviors that just require their data/configuration to be specified. For example, one behavior I have is ItemCarrier, which defines if the object has items the player can pick up. This only requires that the item IDs and quantities are specified, which are easy to attach to objects in Blender as custom properties. Unity built-ins like colliders can also be configured.
Stagecraft then exports the scene as its individual models (as GLTFs) and then a separate scene hierarchy that has all this additional data like ItemCarrier items. In Unity I have a custom importer which imports this scene hierarchy and creates all the appropriate game objects with the correct MonoBehaviours attached. It creates the correct lights and bakes the lightmap as well. The goal is that the scene is entirely specified in Blender and no edits should be made to the scene in Unity. We’ll see where the limits to this approach are, but so far it seems to work well.

There is one major improvement I’m figuring out, which is handling animation state machines and blend trees. I’d like to be able to bring in an asset with some animations (actions) and be able to define the equivalent of a Unity Animator from within Blender, with conditions and triggers that are handled by Verses/Garland.
Loom
I also have a new version of my world-building and content authoring tool, loom, which makes it easier to edit scripts, write quest outlines, and organize characters, factions, and locations.

Next steps
I’m still working on mechanics, but I need to have a playable prototype before I can really move further, hence the focus on getting the content production system further along. The next big tasks for this workflow are putting characters in scenes and having complex animation state machines, and then thoroughly testing the Verses/Garland script integrations in Unity. Hopefully soon I’ll have the whole skeleton of the game engine and production system finished and it’ll be easier to iterate on it and polish it. The hardest part is getting the foundation in place.
")