Clustering news articles with hs_cluster
This week I returned to tackling the news clustering problem I had been exploring last year.
The general goal is to take in groups of news articles, and cluster them so that news articles talking about the same event are grouped together.
Before, I used a clustering technique that was an incremental form of hierarchical agglomerative clustering (IHAC, implementation available here) which seemed better suited for the task compared to more popular approaches like k-means and DBSCAN. However, that technique had its own problems.
The problem
The clustering quality still was not where I needed it to be - in particular, many of the resulting article clusters (which I call “events”) included articles which were unrelated to the others.
This is a problem of cluster homogeneity, which asks: how many members are in clusters with members from other true clusters? The complement of this is completeness, which asks: how many members that belong together (in the true clustering) were clustered together? Lower completeness is tolerable - people are less likely to notice the absence of an article that belongs than the presence of an article that doesn’t (which is what homogeneity measures).
As a simple illustration, imagine the true clusters:
[A_1, A_2, A_3], [B_1, B_2, B_3]
The following clustering has a homogeneity score of 1 (the best score) and a completeness score of ¦\approx 0.685¦.
[A_1, A_2], [A_3], [B_1, B_2, B_3]
The following clustering has a completeness score of 1 (the best score) and a homogeneity score of ¦\approx 0¦.
[A_1, A_2, A_3, B_1, B_2, B_3]
For my task, the former is preferable to the latter.
Note that the following clustering has a homogeneity score of 1, but a completeness score of ¦\approx 0.387¦.
[A_1], [A_2], [A_3], [B_1], [B_2], [B_3]
We don’t want to achieve good homogeneity at the total expense of completeness, as is the case here!
Parameter selection
The severity of this problem was mostly affected by where I decided to snip the cluster hierarchy that IHAC produced. The problem is that this value is difficult to determine in advance as it may vary for different sets of articles.
This dilemma - known as parameter selection - is one that crops up a lot in clustering. For k-means, it’s the question of the value for ¦k¦; for DBSCAN, it’s the value of ¦\epsilon¦ under concern.
For IHAC my selection heuristic was based on the average density of branch nodes, but that was not working well.
In the case of k-means and DBSCAN, this problem of parameter selection is an area of active research, so there are a few promising techniques to start with.
DBSCAN parameter selection
For DBSCAN, one technique (outlined here) involves looking at the nearest neighbor for each point and identifying some majority value for ¦\epsilon¦ based on that.
The technique I’m using is similar - it involves taking the ¦n¦ nearest neighbors for each point, looking at the distances between them, and identifying the largest “jump” in distance. The average of the distances that precede those jumps in difference is used as ¦\epsilon¦.
(Though I also wonder if ¦\epsilon¦ is a parameter that could be learned; that is, if news events tend to have a similar article density.)
k-means parameter selection
For k-means, one effective approach is outlined here, called “¦f(K)¦”, which runs k-means iteratively with different values of ¦k¦ and computes scores for them (see the article for details).
You do need to specify an upper limit for ¦k¦, which in theory could just be ¦n¦ (the number of documents), but practically speaking, this can be very slow and it’s unlikely that every document will belong to its own cluster. I’ve been using ¦n//3 + 1¦ under the assumption that the events have at least 3 news articles each.
For k-means, getting ¦k¦ right is especially important. DBSCAN has a concept of outliers so points which don’t seem to belong to clusters will be treated as noise. But for k-means, every point must be assigned to a cluster, which can be problematic.
Evaluating these approaches
To evaluate these approaches, I needed some ground truth events. Fortunately, there is a resource for this: Wikinews.
On Wikinews, contributors write entries about news events and supply a list of sources for each. XML dumps of these pages are available - so I put together a program called focusgroup which parses these dumps, applies a few heuristics to weed out noise events - those in other languages, with too few sources, with sources which are no longer available, with unreliable sources, etc. - and then downloads and extracts the source pages’ main content into a database.
Evaluation datasets of 10, 20, and 30 randomly selected clusters/events were built from this data.
What follows are the scores for k-means with automated parameter selection, DBSCAN with automated parameter selection, and my hs_cluster approach (which I’ll explain below) on the 10, 20, and 30 event datasets (which I’ll call 10E, 20E, and 30E, respectively).
For k-means and DBSCAN, documents are represented using TF-IDF weighted vectors (see the vectorizer source for details).
(Note that k-means is not included for the 30 event dataset because automated parameter selection seemed to run indefinitely.)
| Approach | # Clusters | Completeness | Homogeneity | Time | |
|---|---|---|---|---|---|
| 10E | kmeans_cluster | 7 | 0.9335443486 | 0.7530130785 | 6.65s |
| dbscan_cluster | 6 | 1.0 | 0.7485938828 | 0.34s | |
| hs_cluster | 12 | 0.9287775491 | 0.9527683893 | 2.79s | |
| 20E | kmeans_cluster | 16 | 0.9684967878 | 0.8743004102 | 12.08s |
| dbscan_cluster | 16 | 0.9580321015 | 0.8637897487 | 0.52s | |
| hs_cluster | 35 | 0.8677638864 | 0.9888333740 | 4.42s | |
| 30E | kmeans_cluster | n/a | n/a | n/a | n/a |
| dbscan_cluster | 7 | 0.9306925670 | 0.2568053596 | 7.13s | |
| hs_cluster | 60 | 0.8510288789 | 0.9539905161 | 11.27s |
None of the approaches reliably get close to the number of true clusters. But what’s important is that the hs_cluster approach scores much better on homogeneity (at the expense of completeness, but again, that’s ok).
The hs_cluster approach
These automatic approaches are okay at finding decent values for these parameters, since these scores are not terrible - but they are clearly still weak on the homogeneity front.
An approach that doesn’t require specification of a parameter like ¦k¦ or ¦\epsilon¦ would be ideal.
I’ve developed an approach which I call hs_cluster (the reason for the name is left as an exercise for the reader) which has been effective so far. Like all approaches it needs some concept of document similarity (or distance, as is the case with k-means and DBSCAN)
Document similarity
First, the pairwise similarity between all documents is computed.
Here I’m trying to take advantage of some features of the news - in particular, the assumption that articles that belong to the same event will typically talk about the same named entities.
The simplest similarity computation for a pair of documents is just the size of entity intersection (I’ll go into some improvements on this further on).
Detecting outliers
Given these pairwise similarities, how do we know when two documents are significantly similar? This could be framed as a new parameter - i.e. some threshold entity intersection, above which we can say two documents are sufficiently alike.
However, this just introduces a new parameter selection problem, when the whole point of this new approach is to avoid doing exactly that!
Instead, statistical outliers seem promising. For a each document, we identify which of its similarities with other documents is an upper outlier, and consider those significant.
There are a few techniques for detecting outliers.
Perhaps the simplest involves using quartiles of the data: look at values above ¦Q_3 + 2(Q_3 - Q_1)¦. The main problem with this technique is that it’s sensitive to the sample size, e.g. if you are looking at a handful of documents, you’re unlikely to get reliable results.
Another technique is similar to the ¦\epsilon¦ selection for DBSCAN, where abnormally large jumps between values are identified, and outliers are considered values above that jump.
A third technique is based on median-absolute-deviation (MAD), outlined here. This technique has the benefit of not being sensitive to sample size.
In practice, the simple quartile approach has worked best. I haven’t looked at document sets of less than 10 in size, so perhaps below that it falls apart.
Creating the graph
These documents and their outlier similarities were then used to construct a graph where these outlier similarities define edges and their weights between documents.
Identifying and disambiguating cliques
Once the graph is formed, it’s just a matter of running a clique finding algorithm (the networkx library includes one) on it.
There is one last issue - an article may belong to multiple cliques, so we need to disambiguate them. The method is simple: stay in the clique for which membership is the strongest (as quantified by the sum of edge weights) and leave all the others.
Initial results
The initial results of this approach were promising:
| Completeness | Homogeneity | |
|---|---|---|
| 10E | 0.9287775491 | 0.9527683893 |
| 20E | 0.8347274166 | 0.9724715221 |
| 30E | 0.8491559191 | 0.9624775352 |
And here is the graph for the 10E dataset (all graphs are shown before clique disambiguation):
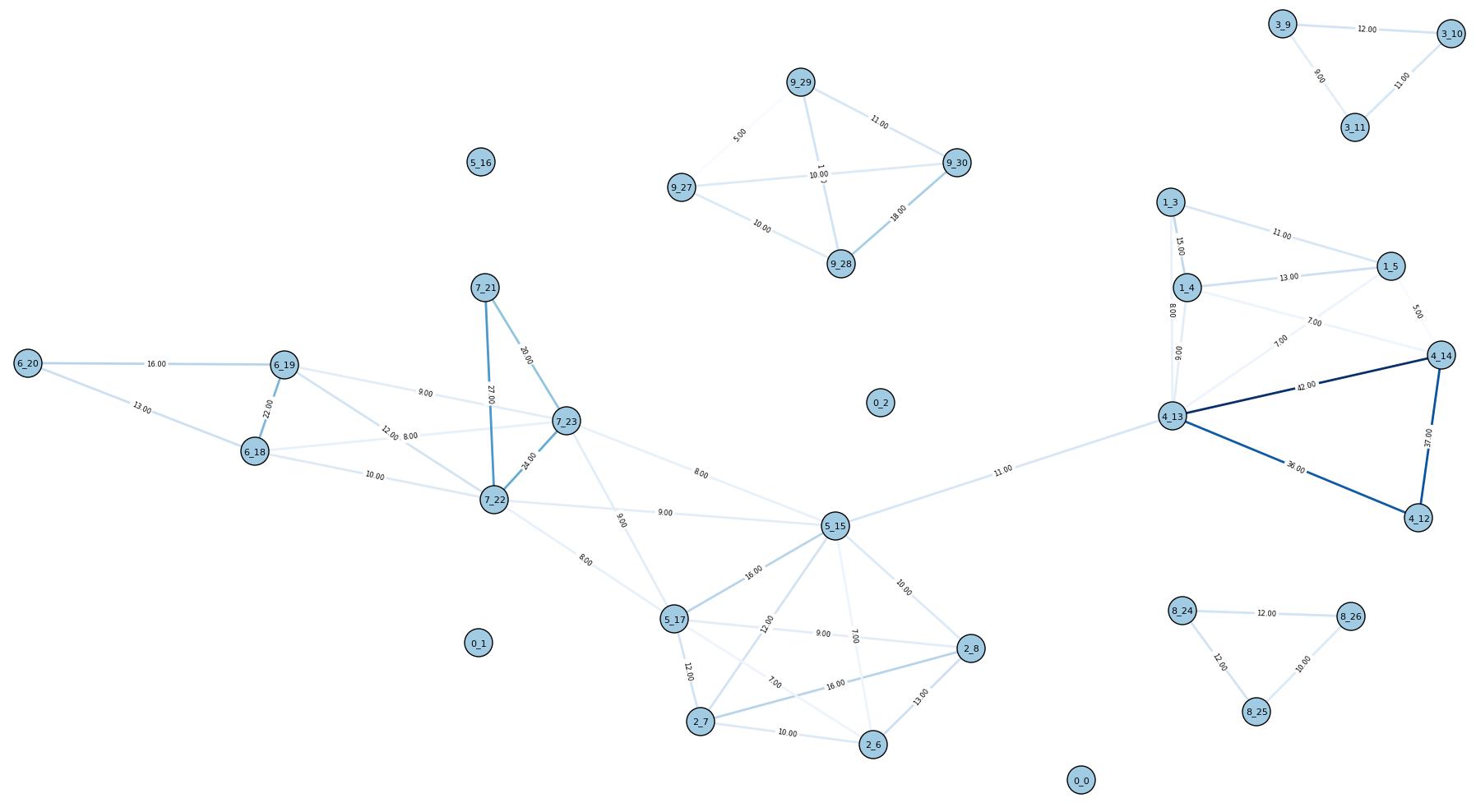
(Node labels are in the format of {cluster id}_{article id}.)
It looks pretty good - some of the true clusters are isolated cliques. But there are still many connections between unrelated articles, so it seems that there’s room for improvement.
Weighting intersections
“Global” IDF
Up until now we were only looking at intersection of entities, so all entities are treated equally. However, there are some fairly uninformative entities, like “US” or “Congress” which we expect to see naturally occur in many articles. We want to down-weight these entities since their appearance across two documents is unremarkable. Conversely, we want to up-weight entities which rarely occur, since their presence in an intersection is unlikely and therefore more meaningful.
Normally the approach here would be to incorporate IDF (inverse document frequency) weighting; typically this IDF is calculated from the input documents. However, the corpora I’m working with now (and expect to use in the future) are fairly small, perhaps 30-100 documents at a time, which limits the possibility of any meaningful IDF being generated. Instead I’ve opted for an IDF model built on an external source of knowledge - about 113,200 New York Times articles. That way we have some “global” understanding of a term’s importance in the context of news articles.
So now instead of merely looking at the size of the intersection, it uses the sum of the IDF weights of the intersection’s members.
Inverse length weighting
The possible intersection between two documents is affected by the length of the documents, so the IDF-weighted overlaps are then further weighted by the inverse of the average length of the two documents being compared.
Results of weighting
Incorporating these weights seem to help for the most part:
| Completeness | Homogeneity | |
|---|---|---|
| 10E | 0.9557853457 | 1.0 |
| 20E | 0.8375545102 | 0.9793536415 |
| 30E | 0.8548535867 | 0.9689355683 |
Here is the resulting graph for 10E:
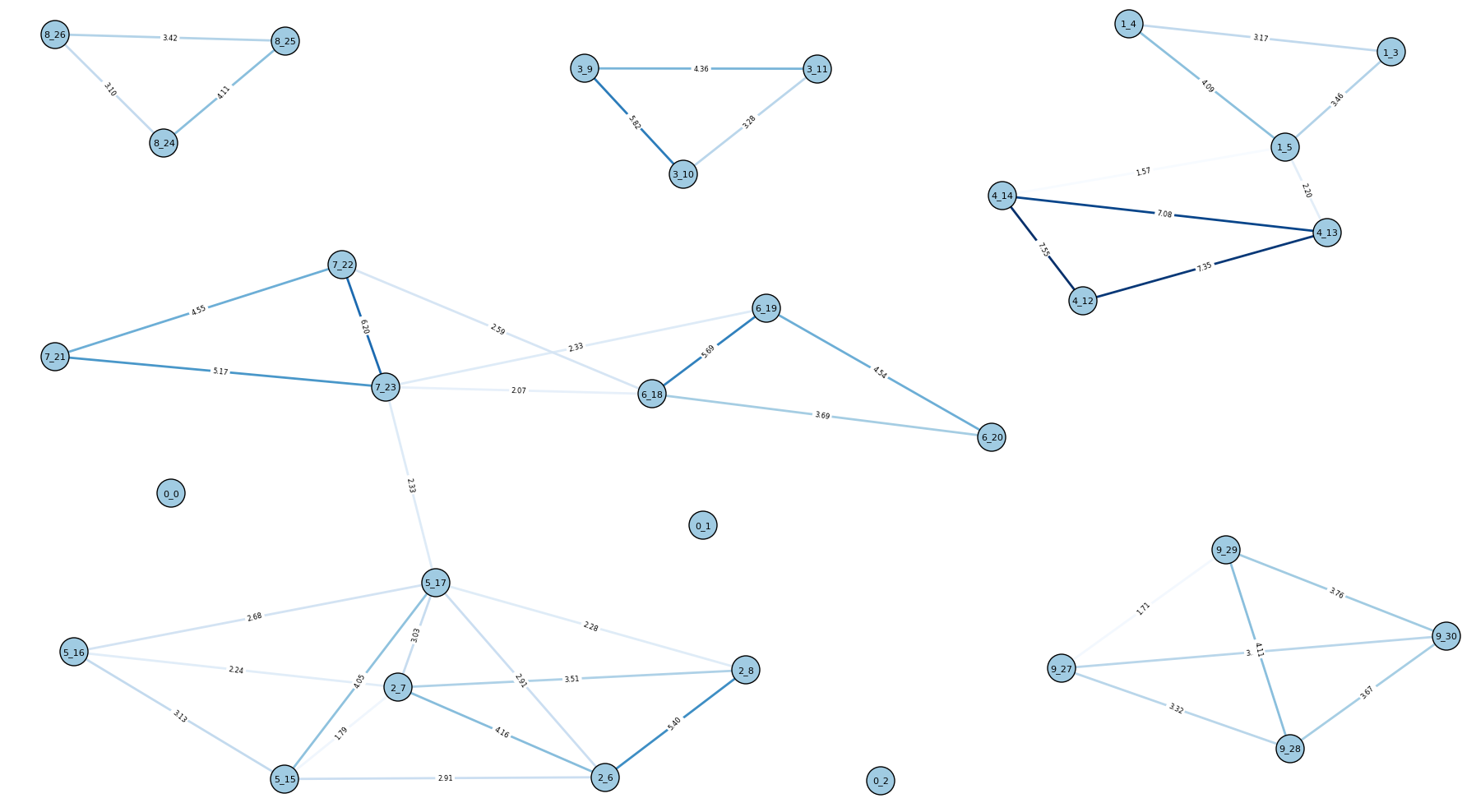
It looks a lot cleaner than before!
Incorporating keywords
A grim observation from the data is that entities may not be enough to fully discern different news events, such as these two events in the 10E dataset:
[2] US soldier arrested for rape and four murders in Iraq
[5] Two Iraqi MPs killed in bombing at parliament
And these two events in the 20E dataset:
[3] Al Jazeera airs new Osama Bin Laden tape
[5] Bin Laden's former driver convicted of supporting terrorism
(Event names are taken from their Wikinews page title)
It seemed that looking at keywords might provide the missing information to disambiguate these events. So for each article I applied a few keyword extraction algorithms followed by the same approach that was used for entities: use the length-weighted sum of the IDF-weighted keyword intersections.
The final similarity score is then just the sum of this keyword score and the entity score from before.
The results for 10E are actually hurt a bit by this, but improved slightly for 20E and 30E:
| Completeness | Homogeneity | |
|---|---|---|
| 10E | 0.9051290086 | 0.9527683893 |
| 20E | 0.8574072716 | 0.9888333740 |
| 30E | 0.8414058524 | 0.9704378548 |
If we look at the graph for 10E, it’s clear why the results were worse:
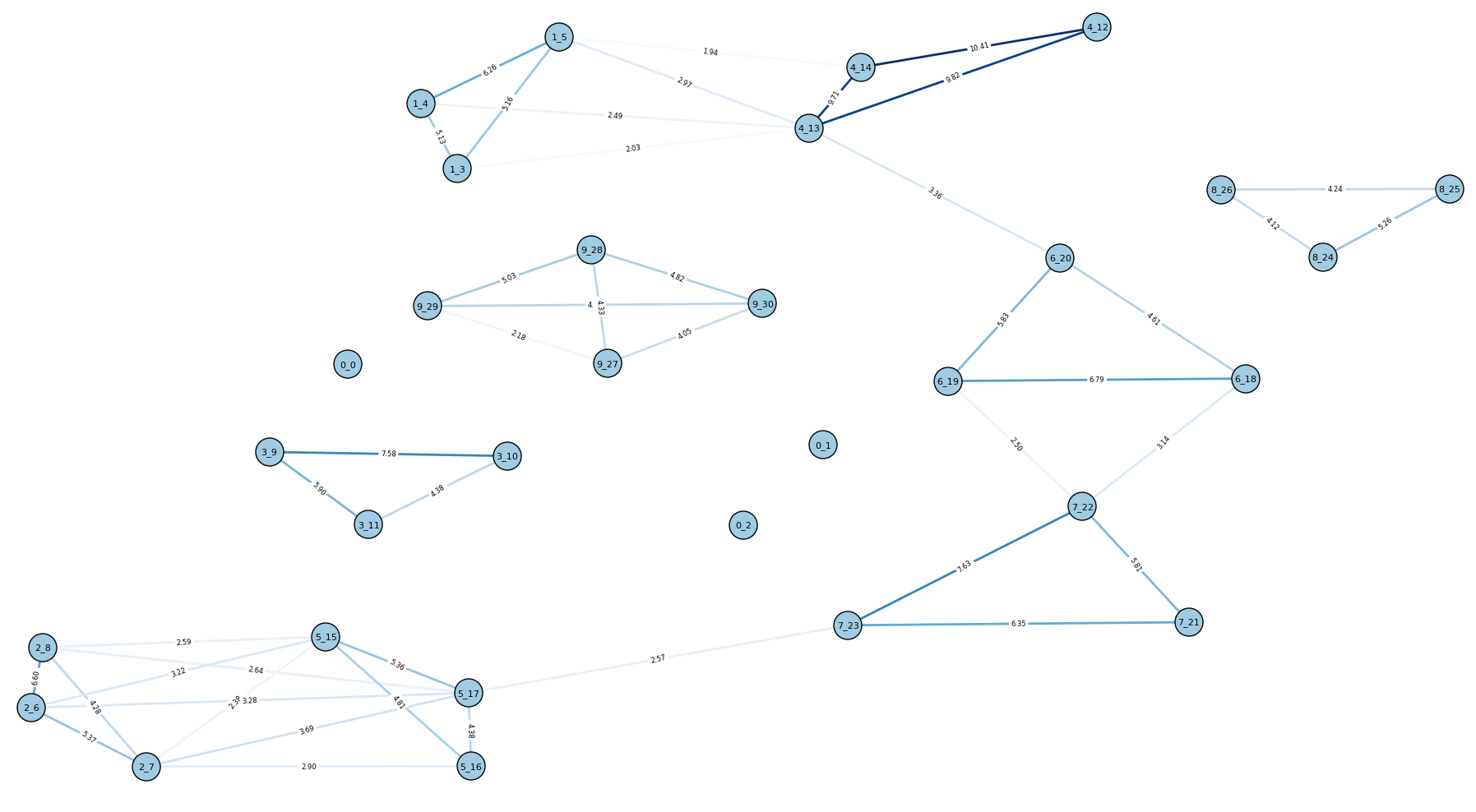
More noise (i.e. unwanted edges) have been introduced, as you might expect.
For now, I’ve left the keyword intersection in, but it may require some additional processing to eliminate noisy terms.
Next steps
hs_cluster can overshoot the true number of events by quite a bit, but this is because it is still very conservative in how it connects articles together for now. Finding so many extra clusters (i.e. lower completeness) indicates missing edges (this is clear in the graph for the 20E dataset, below), so edge formation needs more investigation: is it a problem of outlier detection? Is it a problem of computing document similarity?
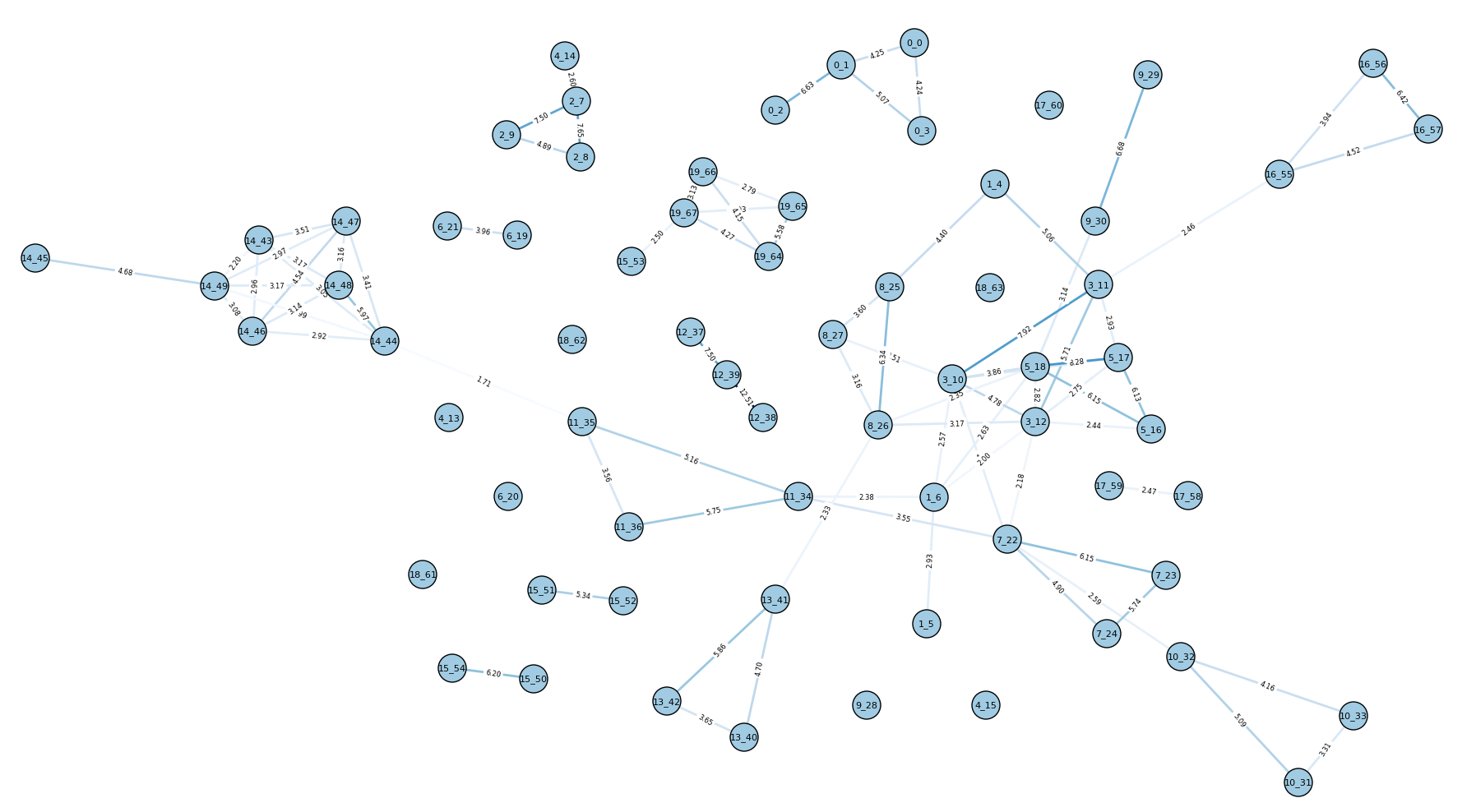
It’s also unclear how hs_cluster will perform on larger document sets. The 30E dataset includes 103 documents and takes 11-12 seconds. This grows exponentially with the graph size. I have not looked deeply into clique-finding algorithms, but a quick look shows that the Bron-Kerbosch algorithm is an efficient way of identifying cliques.
Overall, the results are encouraging. There’s still room for improvement, but it seems like a promising direction.
Source
Source code for the project is available at https://github.com/frnsys/hscluster. The IDF models are not included there; if you are interested, please get in touch - I’m on Twitter as @frnsys.