Simulation Designer Sketches
The other day I wrote a bit about the backend architecture of syd; here I’ll talk a bit about the tentative design plans. While the backend part of syd is supposed to make writing agent-based simulations easier, you still need to know implement these simulations with code. A typical process for developing such simulations involves design phases, e.g. pen-and-paper sketches or diagramming with flowcharting software where the high-level structure of the system is laid out. Causal loop diagrams are often used in this way.
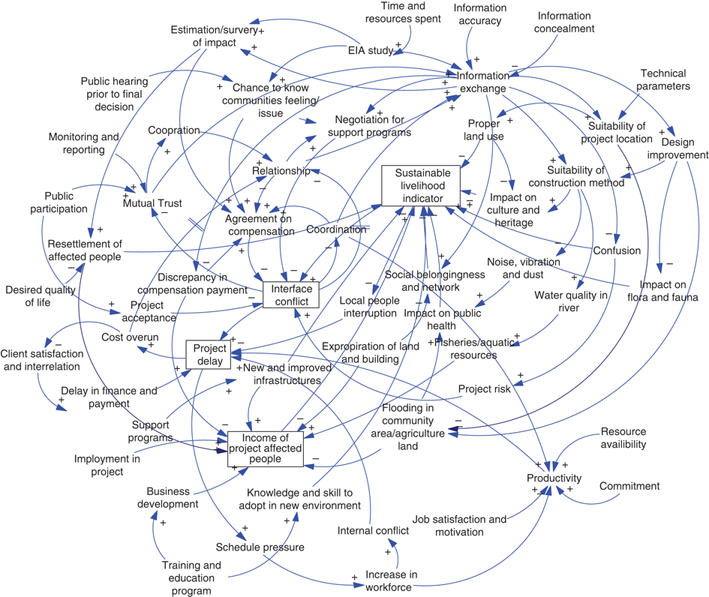
Ideally the process of designing and sketching this high-level system architecture is the same as implementing the system simulation. This isn’t a new idea; it’s the approach software like Vensim uses. The point of syd, however, is to appeal to people with little to no systems thinking background; existing systems modeling software is intended for professionals in academia and industry in addition to being closed source and expensive.
Node-based interface
The general idea is to use a node-based interface. With node-based interfaces you compose causal graphs which are a natural and intuitive representation of systems. As an added bonus, if you design it so that nodes can be composed of other nodes, the interface lends itself to modularity as well.
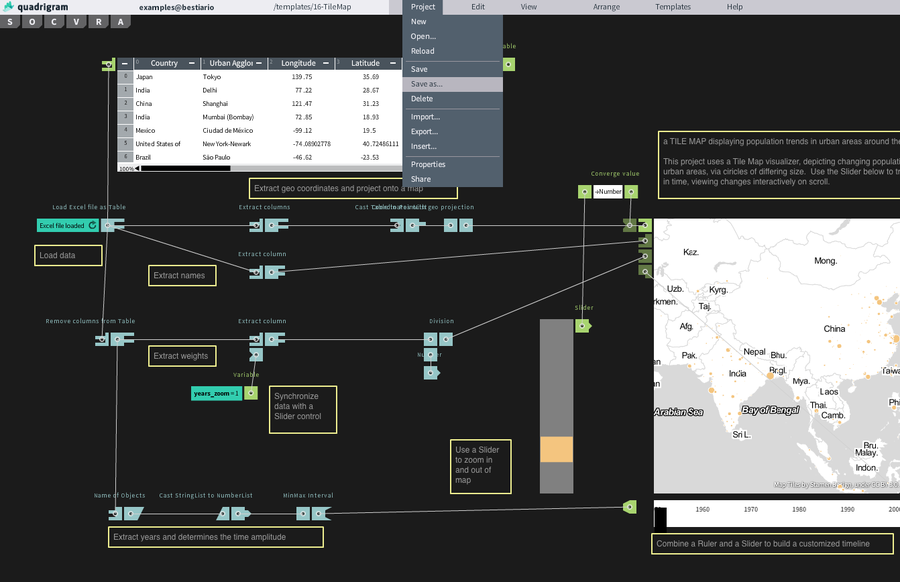
System and agent views
In the syd interface there are two view levels:
- the system level (i.e. the “environment” or the “world”). This works like conventional system dynamics software such as Vensim; i.e. you can define stocks and flows and connect them together.
- the agent level. In this view you design the internals of a type of agent (e.g. a person, a firm, etc).
Since the system level view is quite similar to conventional system dynamics software (and also because I haven’t fully thought it through yet) I won’t go into much detail there. Basically the system level supports the creation of stocks (quantities), flows (changes in quantities that can link between stocks), and outputs (e.g. graphs and other visualizations). This gif of TRUE gives a good sense of it:
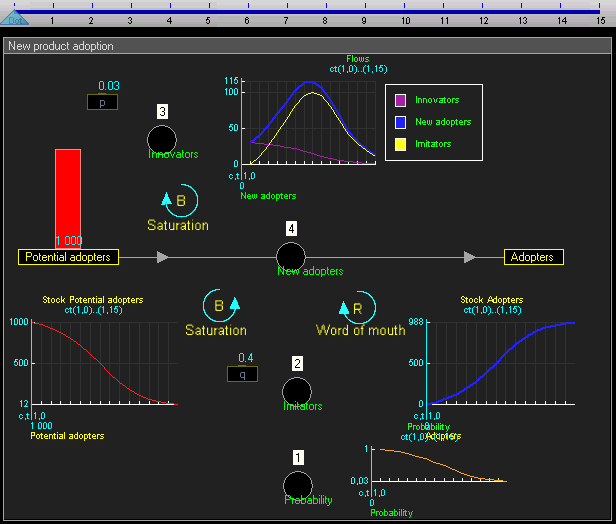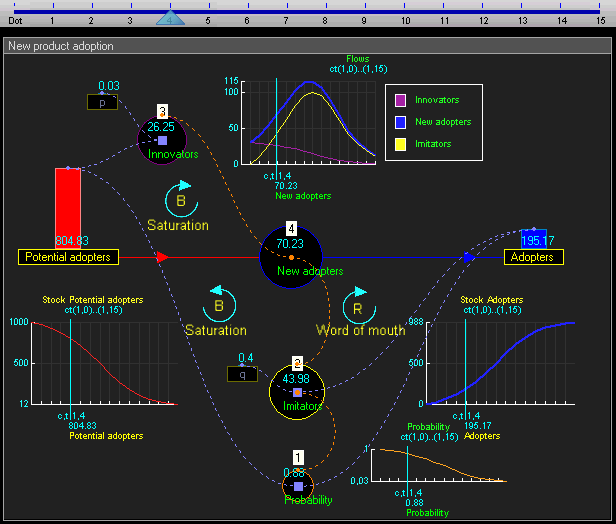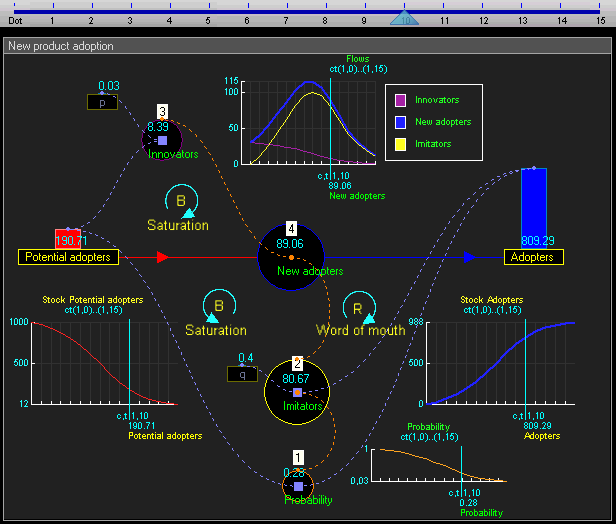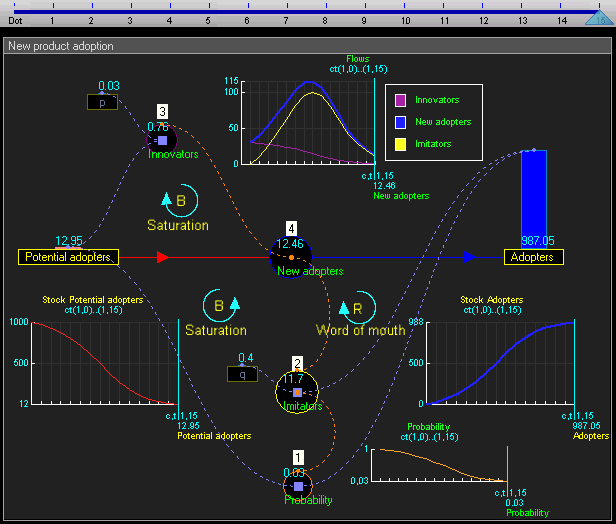
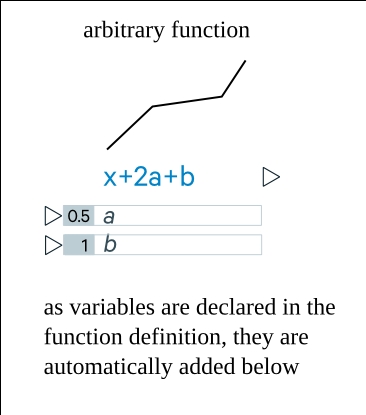
For example, a flow may be some arbitrary function that other outputs and inputs can link to.
You can also take a bunch of flows and stocks and group them into a module node, which “black boxes” the internals so you avoid spaghetti:
You can also visualize aggregate statistics for agent types as well.
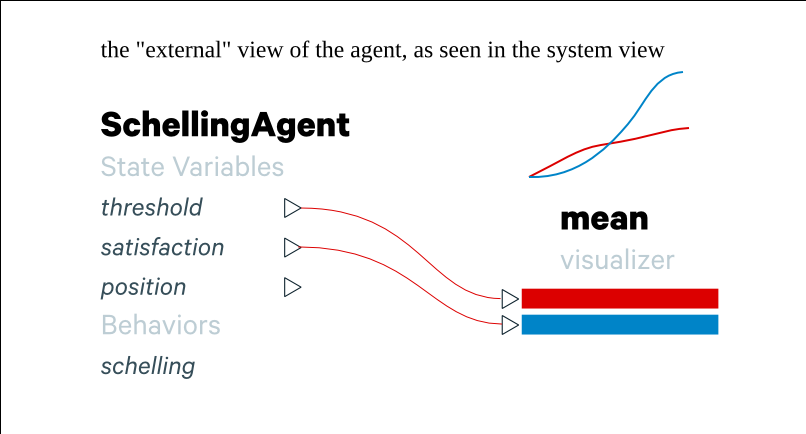
The system view is also where you spawn populations of agents.
Designing agents
Agents are defined as types (e.g. a person, or a firm, or a car driver, etc) and are composed of state variables and behaviors.
State variables have a name and may be of a particular type (e.g. discrete/categorical or continuous, perhaps collections or references as well). Depending on its type it may have additional parameters that can be set (e.g. if it is a continuous state variable, it may have minimum and maximum values).
State variables may be instantiated with a hardcoded value, which is identical across all agents of that type, or they may be instantiated with some function (e.g. a random distribution or a distribution learned from data), which may cause its value to vary for each individual agent. Note that a limitation here is that at instantiation state variables are treated as independent; i.e. we can’t (yet) instantiate them using conditional distributions (conditioned on other state variables, for instance).
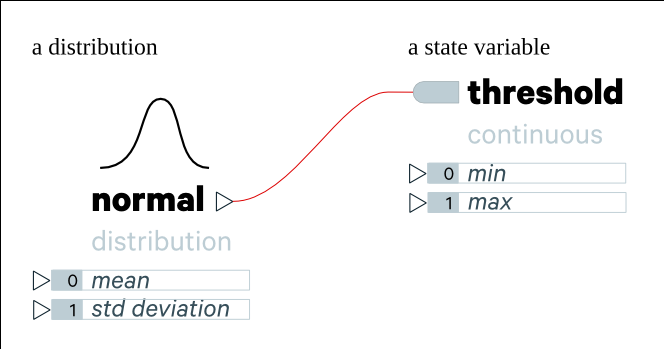
State variables are changed over the course of the simulation through behaviors. Behaviors are isolated components that are attached to an agent.

So far behaviors are black-boxes that read from some state variables and write to other state variables. A warning is raised if a required state variable is not present; perhaps there should be an option to map the expected state variable name to an existing state variable (e.g. if a behavior expects the state variable foo but my agent has bar, I can tell the behavior to use bar instead).
A warning will also be raised if there are multiple behaviors that need to write to the same state variable. So far I haven’t thought of a way for the user to easily specify how such write conflicts should be resolved.

A special kind of behavior is a metabehavior, which, instead of modulating state variable values, adds or removes other behaviors based on conditions. I haven’t yet figured out the best way to represent this in the interface.
Final notes
There are a few additional features that would be great to include:
- export models as JSON (or some other nice interchange format)
- hierarchical simulations; i.e. take another model and include it as a node in another simulation. For instance, maybe you have a simulation about the internal workings of a company (modeling employees and so on) and you want to use that as a sub-simulation in a model of a national economy.
- level-of-depth (LOD) and multiscale simulations
These extra features and some other aspects of the interface as described here (especially agent behaviors) require re-architecting of some of the backend, so I don’t know when we’ll be able to prototype the interface. I’m not totally confident that this approach will be general/flexible enough for more complex simulations, but we’ll see when we start to prototype and use it.