Geiger (Intro/Update)
A couple months ago I thought it would be interesting to see if a summary could be generated for a comment section. As a comment section grows, the comments become more repetitive as more people pile into make the same point. It also seems that some natural clustering forms as some commenters focus on particular aspects of an article or topic.
When there are hundreds to thousands of comments, there is little to be gained by reading all of them. However, it may be useful to quantify how much support certain opinions have, or what is most salient about a particular topic. What if there we had some automated means of presenting us such insight? For example, for an article about a new coal industry regulation: 27 comments are focused on how this regulation affects jobs, 39 are arguing about the environmental impacts, 6 are mentioning the meaning of this regulation in an international context, etc.
Having such insight can serve a number of purposes:
- Provide a quick understanding of the salient points for readers of an article
- Direct focus for future articles on the topic
- Give a quick view into how people are responding to an article
- Provide fodder for follow-up pieces on how people are responding
- Surface entry points for other readers into the conversation
Geiger is still very much a work in progress and has led to a lot of experimentation, some of which worked ok, some of which didn’t work at all, but so far nothing has worked as well as I’d like.
Below is a screenshot from an early prototype of Geiger which allowed me to try a battery of common techniques (TF-IDF bag of words with DBSCAN, K-Means, HAC, and LDA) and compare their results on any New York Times article with comments.
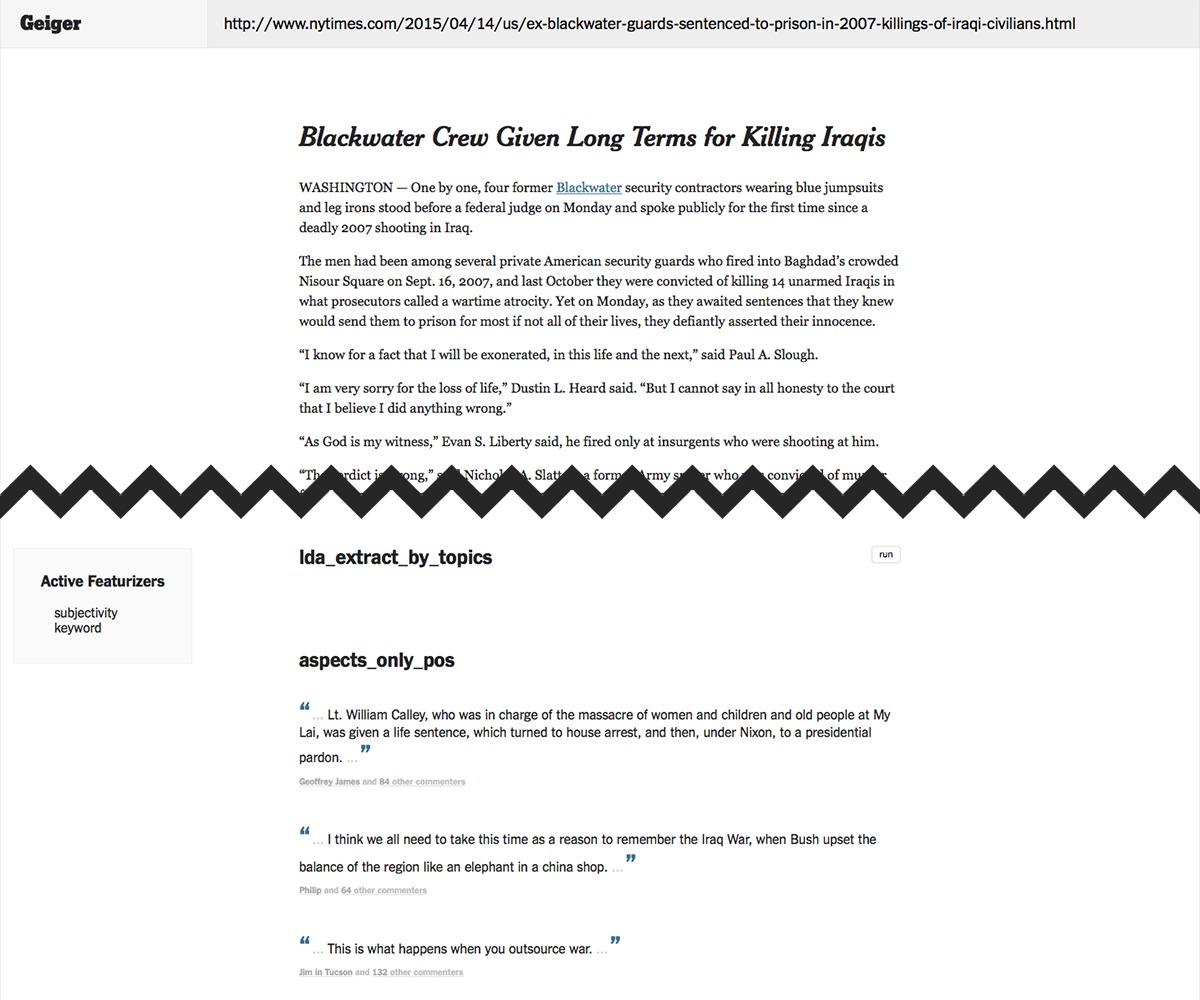
None of those led to particularly promising results, but a few alternatives were available.
Aspect summarization
This problem of clustering-to-summarize comments is similar to aspect summarization, which is more closely associated with ratings and reviews. For instance, you may have seen how Yelp’s business pages have a few sentences selected at the top, with some term (the “aspect”) highlighted, and then the number of reviewers that mentioned this term. That’s aspect summarization - the aggregate reviews are being summarized by highlighting aspects which are mentioned the most.

Sometimes aspect summarization includes an additional layer of sentiment analysis, so that instead of just quantifying the number of people talking about an aspect, whether they are talking positively or negatively can also be surfaced (Yelp isn’t doing this, however).
The process of aspect summarization can be broken down into three steps:
- Identify aspects
- Group documents by aspect
- Rank aspect groups
To identify aspects I used a few keyword extraction approaches (PoS tagging for noun phrases, named entity recognition, and other methods like Rapid Automatic Keyword Extraction) and then learned phrases by looking at keyword co-occurrences. If two keywords are adjacent (or separated by only a conjunction or hyphen) in at least 80% in the documents where they are present, we consider it a key phrase.
This simple co-occurrence approach is surprisingly effective. Here are some phrases learned on a set of comments for the coal industry regulation article:
‘carbon tax’, ‘green energy’, ‘sun and wind’, ‘clean coal’, ‘air and water’, ‘high level’, ‘slow climate’, ‘middle class’, ‘signature environmental’, ‘mitch mcconnell’, ‘poor people’, ‘coal industry’, ‘true cost’, ‘clerical error’, ‘coal miner’, ‘representative democracy’, ‘co2 emission’, ‘power source’, ‘clean air’, ‘future generation’, ‘blah blah’, ‘ice age’, ‘planet earth’, ‘climate change’, ‘energy industry’, ‘critical thinking’, ‘particulate matter’, ‘coal mining’, ‘corporate interest’, ‘solar and wind’, ‘air act’, ‘acid rain’, ‘carbon dioxide’, ‘heavy metal’, ‘obama administration’, ‘monied interest’, ‘greenhouse gas’, ‘human specie’, ‘president obama’, ‘long term’, ‘political decision’, ‘big coal’, ‘coal and natural’, ‘al gore’, ‘bottom line’, ‘power generation’, ‘wind and solar’, ‘nuclear plant’, ‘global warming’, ‘human race’, ‘supreme court’, ‘environmental achievement’, ‘renewable source’, ‘coal ash’, ‘legal battle’, ‘united state’, ‘wind power’, ‘epa regulation’, ‘economic cost’, ‘federal government’, ‘state government’, ‘natural gas’, ‘west virginia’, ‘nuclear power’, ‘radioactive waste’, ‘battle begin’, ‘coal fire’, ‘energy source’, ‘common good’, ‘renewable energy’, ‘coal burning’, ‘nuclear energy’, ‘big tobacco’, ‘carbon footprint’, ‘red state’, ‘sea ice’, ‘peabody coal’, ‘tobacco industry’, ‘american citizen’, ‘fossil fuel’, ‘fuel industry’, ‘climate scientist’, ‘carbon credit’, ‘power plant’, ‘republican president’, ‘electricity cost’
Some additional processing steps were performed, such as removing keywords that were totally subsumed by key phrases; that is, keywords which only ever appear as part of a key phrase. Keywords were also stemmed and merged, e.g. “polluter”, “pollute”, “pollutant”, “pollution” are grouped as a single aspect.
Grouping documents by aspects is straightforward (just look at overlaps). For this task I treated individual sentences as the documents, much like Yelp does.
Ranking them is a bit trickier. I used a combination of token length (assuming that phrases are more interesting than single keywords), support (number of sentences which mention the aspect), and IDF weighting of the aspect. The latter is useful because, for instance, we expect many comments will mention the “coal industry” if the article is about the coal industry, rendering it uninformative.
Although you get a bit of insight into what commenters are discussing, the results of this approach aren’t very interesting. We don’t really get any summary of what people are saying about an aspect. This is problematic when commenters are talking about an aspect in different ways. For instance, many commenters are talking about “climate change”, but some ask whether or not the proposed regulation would be effective in mitigating it, whereas others debate whether or not climate change is a legitimate concern.
Finally, one problem here, which is consistent across all methods, is that this method is ignorant of synonymy - it cannot recognize when two words which look different mean essentially the same thing. For instance, colloquially people use “climate change” and “global warming” interchangeably, but here they are treated as two different aspects. This is a consequence of text similarity approaches which rely on matching the surface form of words - that is, which only look at exact term overlap.
This is especially challenging when dealing with short text documents, which I explain in greater length here.
Word2Vec word embeddings
There has been a lot of excitement around neural networks, and rightly so - their ability to learn representations is very useful. Word2Vec is capable of learning vector representations of words (“word embeddings”) which allow us to capture some degree of semantic quality in vector space. For example, we could say that two words are semantically similar if their word embeddings are close to each other in vector space.
I loaded up Google’s pre-trained Word2Vec model (trained on 100 billion words from a Google News dataset) and tested it out a bit. It seemed promising:
w2v.similarity('climate_change', 'global_warming')
>>> 0.88960381786226284
I made some attempts at approaches which leaned on this Word2Vec similarity of terms rather than their exact overlap - when comparing two documents A and B, each term from A is matched to is maximally-similar term in B and vice versa. Then the documents’ similarity score is computed from these pairs’ similarity values, weighted by their average IDF.
A problem with using Word2Vec word embeddings is that they are not really meant to quantify synonymy. Words that have embeddings close together do not necessarily mean similar things, all that it means is that they are exchangeable in some way. For example:
w2v.similarity('good', 'bad')
>>> 0.71900512146338569
The terms “good” and “bad” are definitely not synonyms, but they serve the same function (indicating quality or moral judgement) and so we expect to find them in similar contexts.
Because of this, Word2Vec ends up introducing more noise on occasion.
Measuring salience
Another angle I spent some time on was coming up with some better way of computing term “salience” - how interesting a term is. IDF is a good place to start, since a reasonable definition of a salient term is one that doesn’t appear in every document, nor does it only appear in one or two documents. We want something more in the middle, since that indicates a term that commenters are congregating around.
Thus middle IDF values should be weighted higher than those closer to 0 or 1 (assuming these values are normalized to ¦[0,1]¦). To capture this, I put terms’ IDF values through a Gaussian function with its peak at ¦x=0.5¦ and called the resulting value the term’s “salience”. Then, using the Word2Vec approach above, maximal pairs’ similarity scores are weighted by their average salience instead of their average IDF.
The results of this technique look less noisy than before, but there is still ample room for improvement.
Challenges
Working through a variety of approaches has helped clarify what the main difficulties of the problem are:
- Short texts lack a lot of helpful context
- Recognizing synonymy is tricky
- Noise - some terms aren’t very interesting given the article or what other people are saying
What’s next
More recently I have been trying a new clustering approach (hscluster) and exploring ways of better measuring short text similarity. I’m also going to take a deeper look into topic modeling methods, which I don’t have a good grasp on yet but seem promising.