The idea of syd is that it will be geared towards social simulation - that is, modeling systems that are driven by humans (or other social beings) interacting. To support social simulations syd will include some off-the-shelf models that can be composed to define agents with human-ish behaviors.
One category of such models are around the propagation and mutation of ideas and behaviors (“social contagion”). Given a population of agents with varying cultural values, how do these values spread or change over time? How do groups of individuals coalesce into coherent cultures?
What follows are some notes on a small selection of these models.
Sorting & peer effects
Two primary mechanisms are sorting, or “homophily”, the tendency to associate with similar people, and peer effects, the tendency to become more like people we are around often.
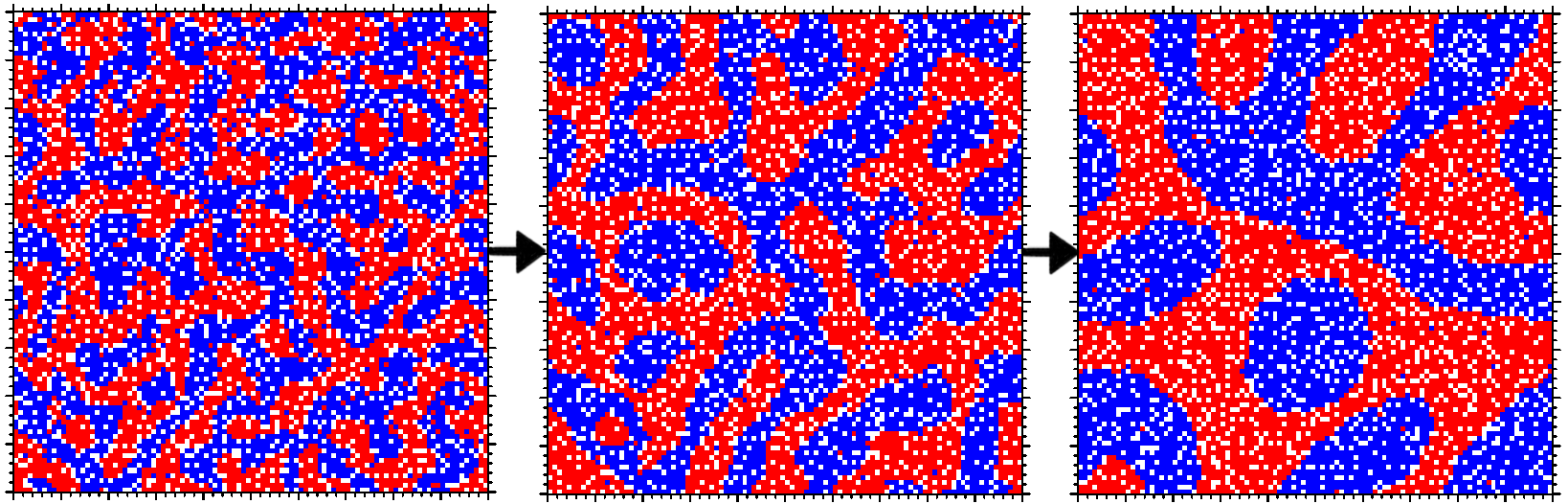
Schelling’s model of segregation may be the most well-known example of a sorting model, where residents move if too many of their neighbors aren’t like them.
Schelling’s model
A very simple peer effect model is Granovetter’s model. Say there is a population of ¦N¦ individuals and ¦n¦ of them are involved in a riot. Each individual in the population has some threshold ¦T_i¦; if over ¦T_i¦ people are in the riot, they’ll join the riot too. Basically this is a bandwagon model in which people will do whatever others are doing when it becomes popular enough.
Granovetter’s model does not incorporate the innate appeal of the behavior (or product, idea, etc), just how many people are participating in it. One could imagine though that the riot looks really exciting and people join not because of how many others are already there, but because they are drawn to something else about it.
A simple extension of Granovetter’s model, the Standing Ovation model, captures this. The behavior in question has some appeal or quality ¦Q¦. We add some additional noise to ¦Q¦ to get the observed “signal” ¦S = Q + \epsilon¦. This error allows us to capture a bit of the variance in perceived appeal (some people may find it appealing, some people may not, the politics around the riot may be very complex, etc). If ¦S > T_i¦, then person ¦i¦ participates. After assessing the appeal, those who are still not participating then have the Granovetter’s model applied (they join if enough others are participating).
There are further extensions to the Standing Ovation model. You could say that an agent’s relationships affects their likelihood to join, e.g. if I see 100 strangers rioting I may not care to join, but if 10 of my friends are then I will.
Axelrod’s culture model
Axelrod’s culture model is a simple model of how a “culture” (a population sharing many traits, beliefs, behaviors, etc) might develop.
each individual is described by a vector of traits
the population is placed in some space (e.g. a grid or a social network)
an individual interacts with a neighbor with some probability based on their trait similarity
if they interact, pick one trait and match with the neighbor’s
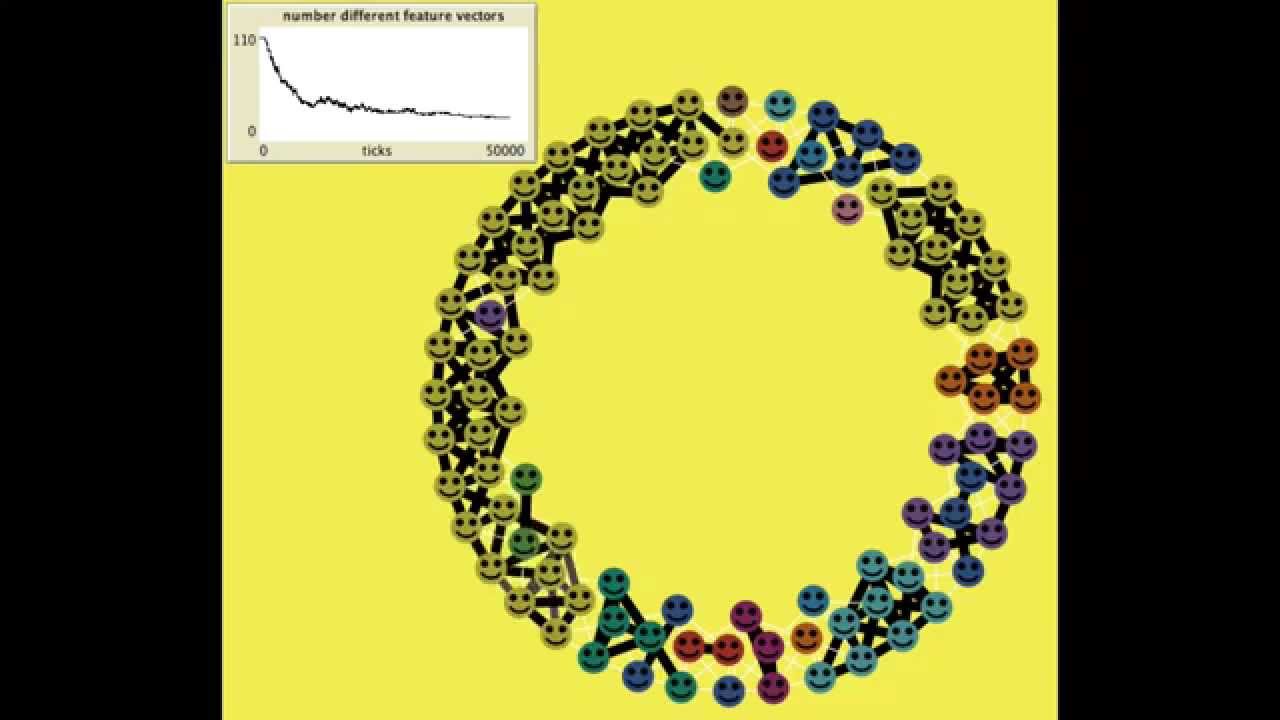
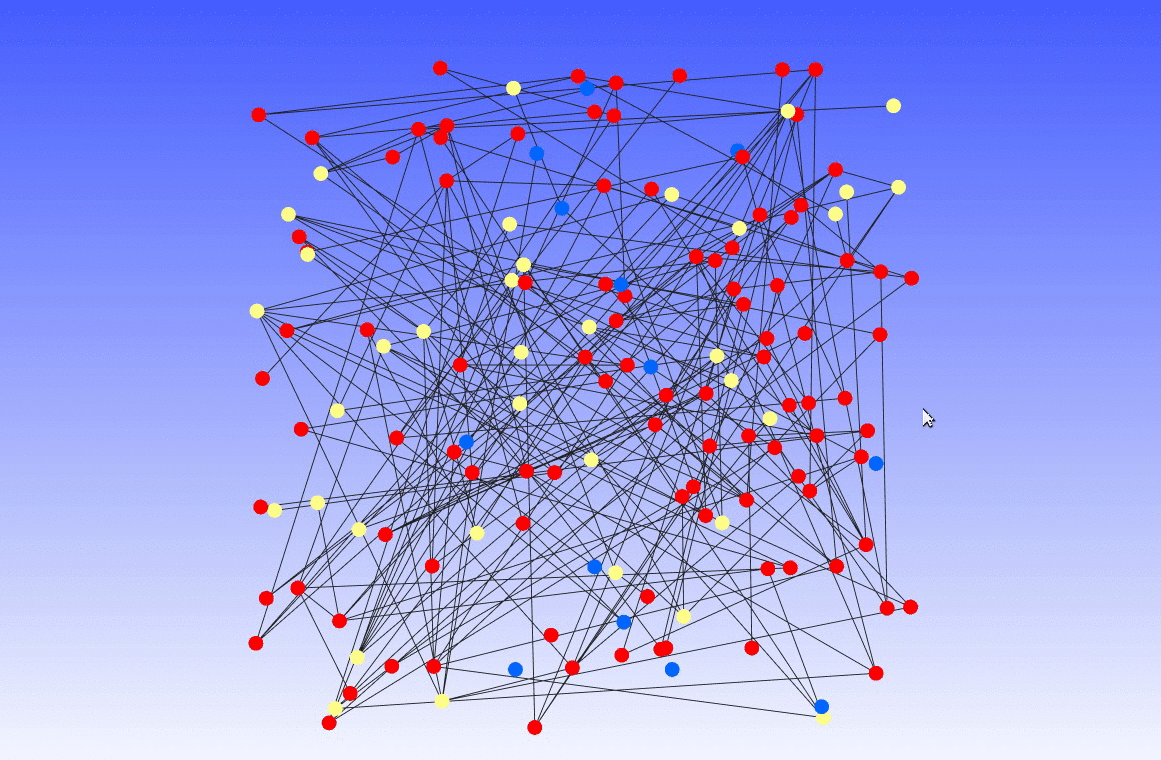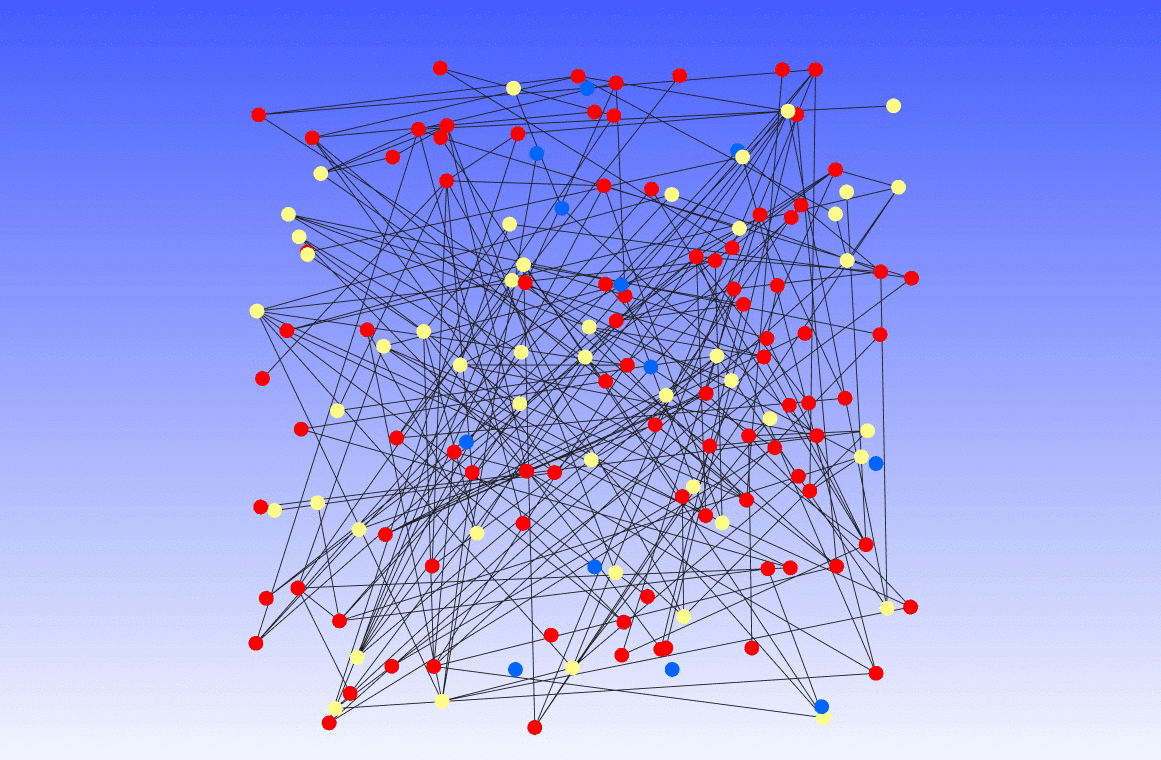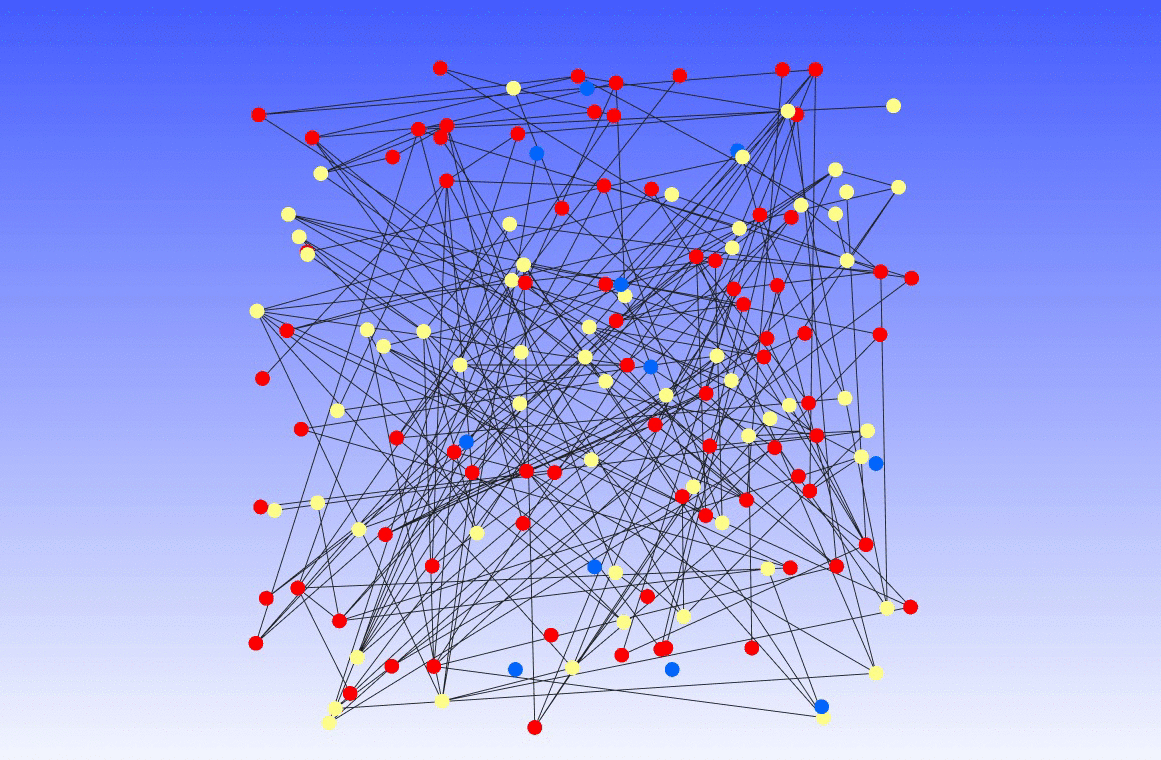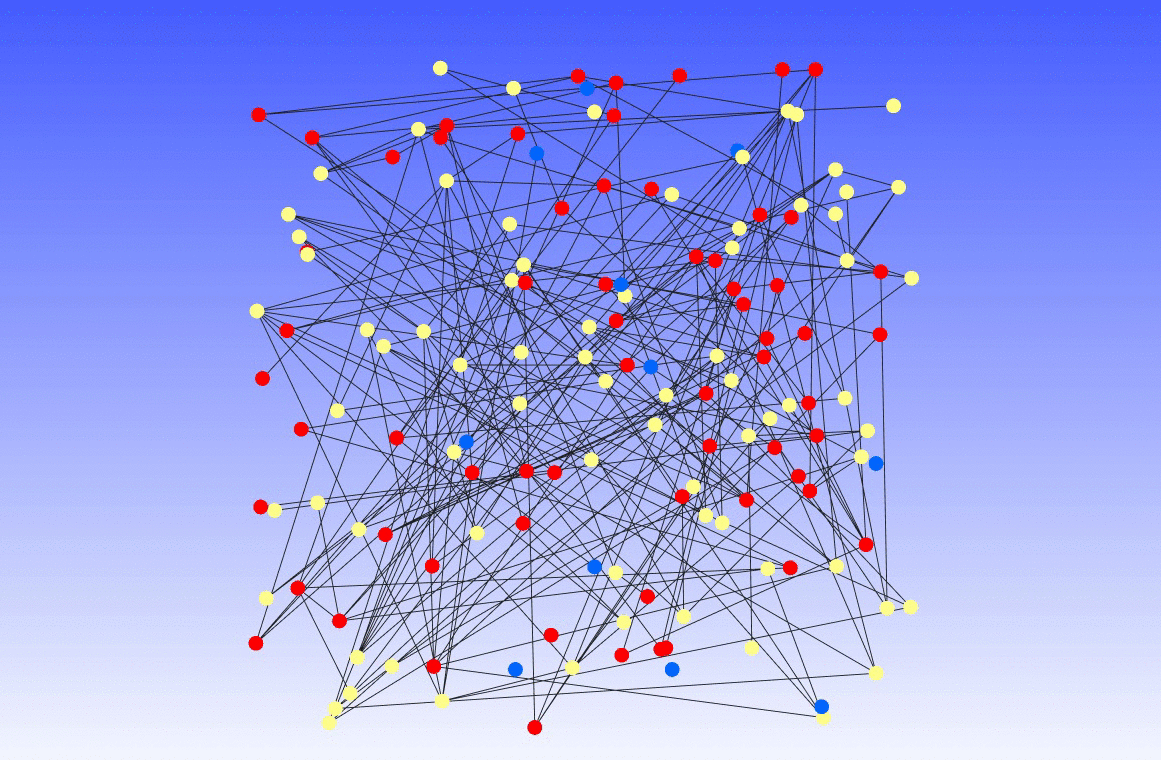
A social network version of Axelrod’s cultural disseminiation model
This model can be extended with a consistency rule: sometimes the value of one trait is copied over to another trait (in the same individual), this models the two traits becoming consistent. For example, perhaps the changing of one belief causes dependent beliefs to change as well, or requires beliefs it’s dependent on to change.
Traits can also randomly change as well due to “error” (imperfect imitation or communication) or “innovation”.
Here agents form a directed graph (e.g. a social network), where edges have two values: frequency of communication and respect one agent holds for the other. For each possible belief, agents have an alignment score which can have an arbitrary scale, e.g. -3 for strong disbelief to 3 for strong belief.
The agent feels a “force” that causes them to change their own alignment. This force is the sum of force from alignment, force from cohesion, and force from separation.
force from alignment is computed by the average alignment across all agents - this is the perceived majority opinion.
force from cohesion: each agent computes the average alignment felt by their neighbors they respect (i.e. respect is positive), weighted by their respect for those neighbors.
force from separation: like the force from cohesion, but computed across their neighbors they disrespect (i.e. respect is negative), weighted by their respect for those neighbors.
This force is normalized and is used to compute a probability that the individual changes their alignment one way or the other. We specify some proportionality constant ¦\alpha¦ which determines how affected an agent is by the force. For force ¦F¦ the probability of change of alignment is just ¦\alpha F¦. It’s up to the implementer how much an agent’s alignment changes.
Memetics
A meme is an idea/belief/etc that behaves according to the rules of memetics, which models the spread of ideas by applying evolutionary concepts:
phenotypes & alleles
the “offspring” of a meme vary in their “appearance”
a meme contains characteristics (“alleles”), some of which are transmitted to their child
variability in allele combinations is responsible for variability at the phenotypic level
mutation
idea mutation may be random
or it may happen for a reason; ideas can change – to solve problems, for instance (these mutations are essentially innovations advocated by a change agent)
selection
some ideas are more likely to survive than others
an idea’s survival is based on how “fit” it is
an idea’s measure of fitness is the likelihood of its offspring surviving long enough to produce their own offspring, compared to other memes
Lamarckian properties
unlike biological evolution, members can be modified, activated or deactivated within a generation (people can adapt their ideas to deal with new information, for example)
drift
if multiple finite-sized populations exist, beginning w/ the same set of initial conditions & operate according to the same mechanisms/constraints, completely different sets of ideas can emerge b/w the populations
this drift is due to sampling error when a parent meme produces offspring (random allele heritage)
Memetic transmission may be horizontal (intra-generational) and/or vertical (intergenerational).
The primary mechanism for memetic transmission is imitation, but other mechanisms include social learning and instruction.
Note that the transmission of an idea is heavily dependent on its own characteristics.
For example, there are some ideas that have “mutation-resistant” qualities, e.g. “don’t question the Bible” (though that does not preclude them from mutation entirely).
Some ideas also have the attribute of “proselytism”; that is part of the idea is the spreading of the idea.
The Cavalli-Sforza Feldman model is a memetics model describing how a population of beliefs evolve over time.
There is a transmission function:
p = 1 - |1 - g|^{n \mu_t}
where:
¦p¦ is the probability that an individual’s belief state will be transformed (i.e. imitate another’s) after ¦n¦ contacts
¦g¦ is the probability of transformation after each contact
¦\mu_t¦ is the proportion of people the individual can come into contact with who already have the target belief state
There’s also a selection function:
\mu_t' = \frac{\mu_t (1+s)}{1 + s \mu_t}
where:
¦\mu_t’¦ is the proportion of beliefs that survive selection for a single generation
¦\mu_t¦ is the proportion of beliefs before selection
¦s¦ is the degree of fitness
“The popular enforcement of unpopular norms”
The models presented so far make no distinction between public and private beliefs, but it’s very clear that people often publicly conform to ideas that they may not really feel strongly about. This phenomenon is called pluralistic ignorance: “situations where a majority of group member privately reject a norm but assume (incorrectly) that most others accept it”.
It’s one thing to publicly conform to ideas you don’t agree with, but people often go a step further and try to enforce others to comply to these ideas. Why is that?
The “illusion of transparency” refers to the tendency where people believe that others can read more about their internal state than they actually can. Maybe something embarrassing happened and you feel as if everyone knows, even if no one possibly could. In the context of pluralistic ignorance, this tendency causes people to feel as though others can see through their insincere alignment with the norm, so they take additional steps to “prove” their conviction.
each agent ¦i¦ has a binary private belief ¦B_i¦ which can be 1 (true believer) or -1 (disbeliever).
true enforcement is when a true believer/disbeliever enforces others to comply/oppose
false enforcement is when a false believer enforces others to comply
An agent ¦i¦ choice to comply with the norm is ¦C_i¦. If ¦C_i=1¦ the agent chooses to complex, otherwise ¦C_i=-1¦. This choice depends on the strength of the agent’s convictions ¦0 < S \leq 1¦.
A neighbor ¦j¦’s enforcement of the norm is represented as ¦E_j=1¦; if they enforce deviance instead then ¦E_j=-1¦. Thus we can compute ¦C_i¦ as:
where ¦0 < K < 1¦ is an additional cost of enforcement for those who also comply (it is ¦K¦ more difficult to get someone who does not privately/truly align with the belief to enforce it).
¦W_i¦ is the need for enforcement, which is the proportion of agent ¦i¦’s neighbors whose behavior does not confirm with ¦i¦’s beliefs ¦B_i¦:
W_i = \frac{1- (B_i/N_i) \sum_{j=1}^{N_i} C_j}{2}
Agents can only enforce compliance or deviance if they have complied or deviated, respectively.
The model can be extended by making it so that true disbelievers can be “converted” to true believers (i.e. their private belief changes to conform to the public norm).
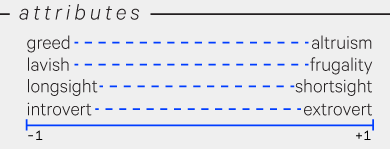
The agents in syd will need to be parameterized in some way that meaningfully affects their behavior. Another way to put this is that the agents need some values that guide their actions. In Humans of Simulated New York Fei and I defined individuals along the axes of greed vs altruism, lavishness vs frugality, long-sightedness vs short-sightedness, and introversion vs extroversion. The exact configuration of these values are what made an agent an individual: a lavish agent would spend more of their money, an extroverted agent would have a larger network of friends (which consequently made finding a job easier), greedy agents would pay their employees less, and so on.
HOSNY value dimensions
The dimensions we used aren’t totally comprehensive. There are many aspects of human behavior that they don’t encapsulate. Fortunately there is quite a bit of past work to build on - there have been many past attempts to inventory a value spectrums that defines and distinguishs cultures. The paper A Proposal for Clustering the Dimensions of National Culture (Maleki, A., de Jong, M, 2014) neatly catalogues these previous efforts and proposes their own measurements as well.
The authors propose the following cultural dimensions:
individualism vs collectivism
power distance: “the extent to which hierarchical relations and position-related roles are accepted”
uncertainty avoidance: “to what extent people feel uncomfortable with certain, unknown, or unstructured situations”
mastery vs harmony: “competitiveness, achievement, and self-assertion versus consensus, equity, and harmony”
traditionalism vs secularism: “religiosity, self-stability, feelings of pride and, consistency between emotion felt and their expression vs secular orientation and flexibility”
indulgence vs restraint: “the extent to which gratification of desires and feelings is free or restrained”
assertiveness vs tenderness: “being assertive and aggressive versus kind and tender in social relationships”
gender egalitarianism
collaborativeness: “the spirit of ‘team-work’”
We can (imprecisely) map the dimensions we used in HOSNY to these:
greed vs altruism -> individualism vs collectivism and collaborativeness
lavishness vs frugality -> indulgence vs restraint
long-sightedness vs short-sightedness -> indulgence vs restraint
introversion vs extroversion -> assertiveness vs tenderness (?)
It doesn’t feel very exact though.
All of the previously defined dimensions are worth a look too:
The other day I wrote a bit about the backend architecture of syd; here I’ll talk a bit about the tentative design plans. While the backend part of syd is supposed to make writing agent-based simulations easier, you still need to know implement these simulations with code. A typical process for developing such simulations involves design phases, e.g. pen-and-paper sketches or diagramming with flowcharting software where the high-level structure of the system is laid out. Causal loop diagrams are often used in this way.
A causal loop diagram
Ideally the process of designing and sketching this high-level system architecture is the same as implementing the system simulation. This isn’t a new idea; it’s the approach software like Vensim uses. The point of syd, however, is to appeal to people with little to no systems thinking background; existing systems modeling software is intended for professionals in academia and industry in addition to being closed source and expensive.
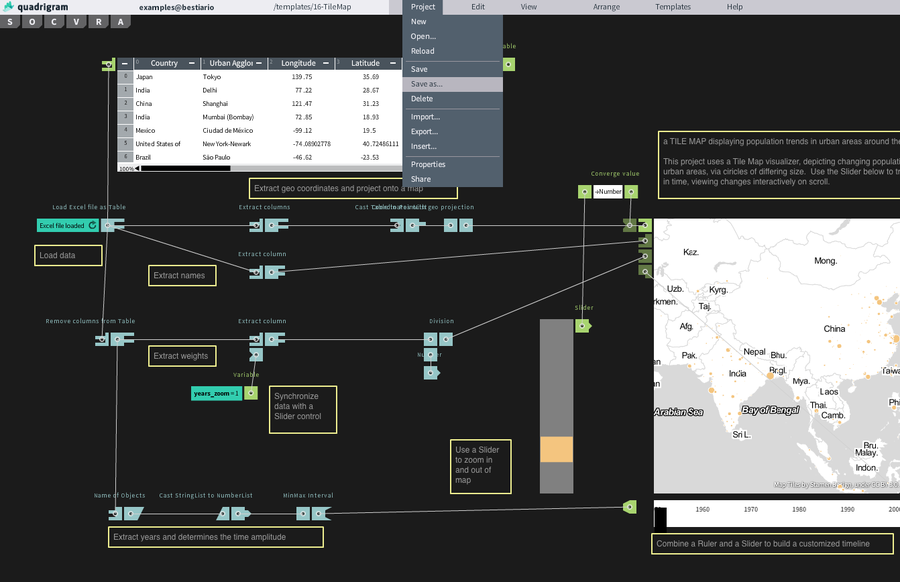
Node-based interface
The general idea is to use a node-based interface. With node-based interfaces you compose causal graphs which are a natural and intuitive representation of systems. As an added bonus, if you design it so that nodes can be composed of other nodes, the interface lends itself to modularity as well.
A node-based interface (quadrigram)
System and agent views
In the syd interface there are two view levels:
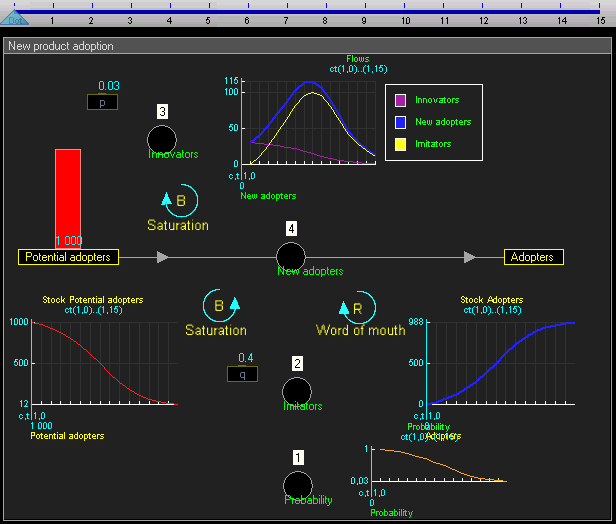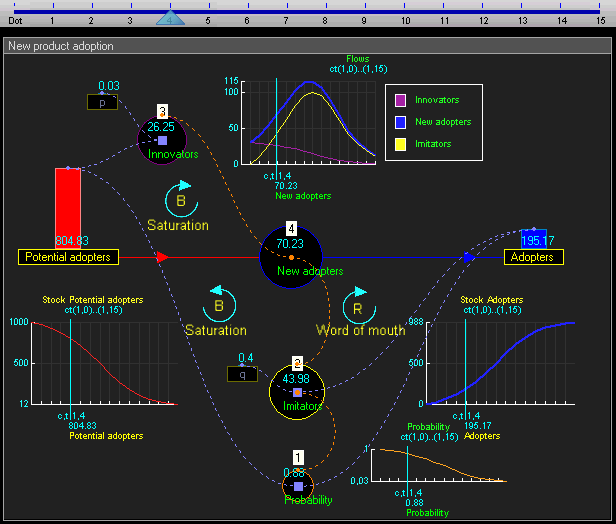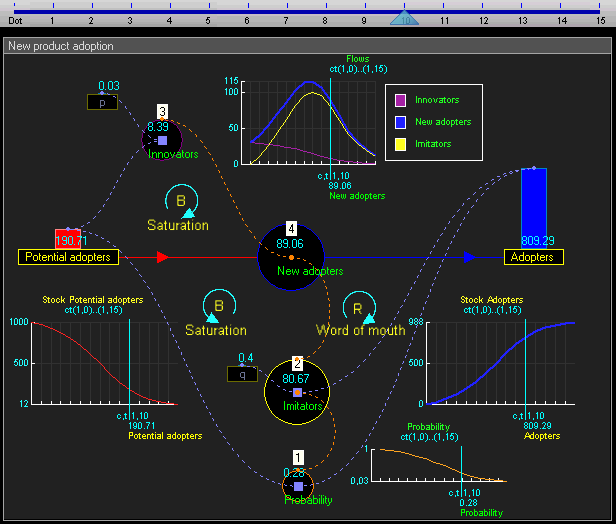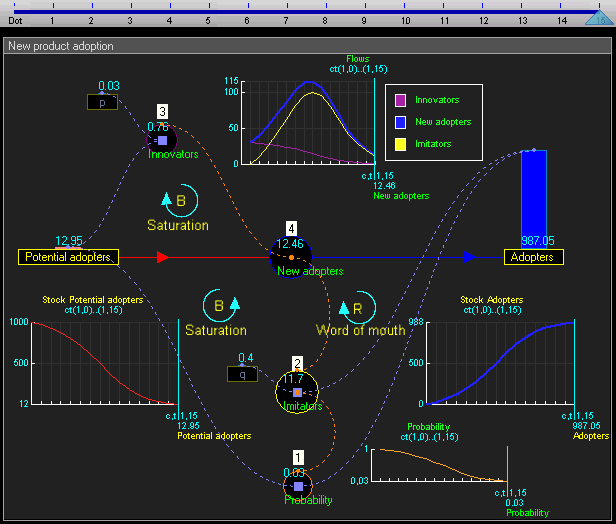
the system level (i.e. the “environment” or the “world”). This works like conventional system dynamics software such as Vensim; i.e. you can define stocks and flows and connect them together.
the agent level. In this view you design the internals of a type of agent (e.g. a person, a firm, etc).
Since the system level view is quite similar to conventional system dynamics software (and also because I haven’t fully thought it through yet) I won’t go into much detail there. Basically the system level supports the creation of stocks (quantities), flows (changes in quantities that can link between stocks), and outputs (e.g. graphs and other visualizations). This gif of TRUE gives a good sense of it:
TRUE
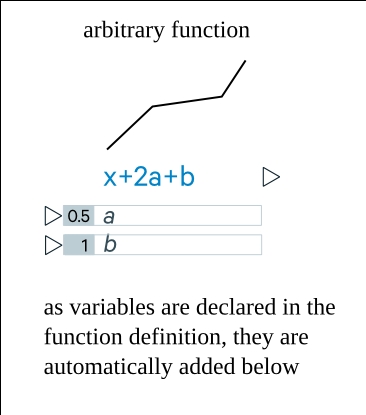
For example, a flow may be some arbitrary function that other outputs and inputs can link to.
Arbitrary function node
You can also take a bunch of flows and stocks and group them into a module node, which “black boxes” the internals so you avoid spaghetti:
Node-based spaghetti
You can also visualize aggregate statistics for agent types as well.
Agent aggregations
The system view is also where you spawn populations of agents.
Designing agents
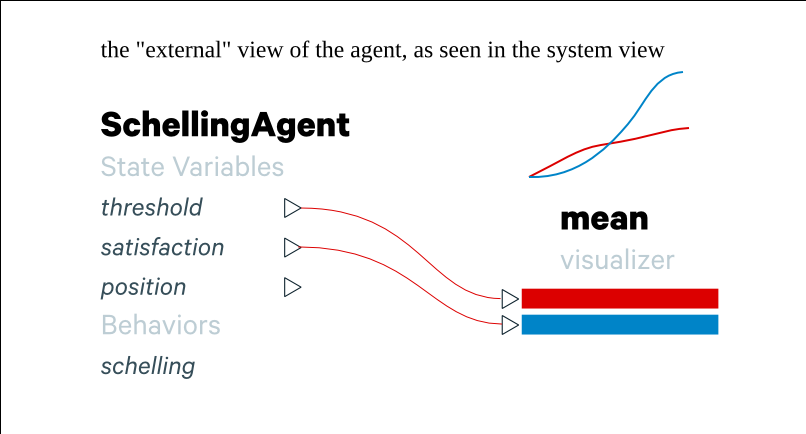
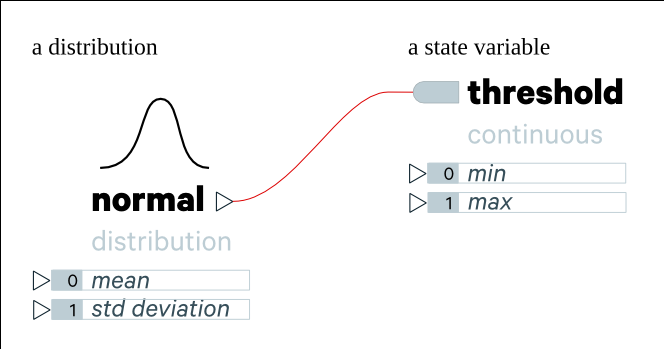
Agents are defined as types (e.g. a person, or a firm, or a car driver, etc) and are composed of state variables and behaviors.
State variables have a name and may be of a particular type (e.g. discrete/categorical or continuous, perhaps collections or references as well). Depending on its type it may have additional parameters that can be set (e.g. if it is a continuous state variable, it may have minimum and maximum values).
State variables may be instantiated with a hardcoded value, which is identical across all agents of that type, or they may be instantiated with some function (e.g. a random distribution or a distribution learned from data), which may cause its value to vary for each individual agent. Note that a limitation here is that at instantiation state variables are treated as independent; i.e. we can’t (yet) instantiate them using conditional distributions (conditioned on other state variables, for instance).
State variable instantiations
State variables are changed over the course of the simulation through behaviors. Behaviors are isolated components that are attached to an agent.
A behavior
So far behaviors are black-boxes that read from some state variables and write to other state variables. A warning is raised if a required state variable is not present; perhaps there should be an option to map the expected state variable name to an existing state variable (e.g. if a behavior expects the state variable foo but my agent has bar, I can tell the behavior to use bar instead).
A warning will also be raised if there are multiple behaviors that need to write to the same state variable. So far I haven’t thought of a way for the user to easily specify how such write conflicts should be resolved.
Behavior warning
A special kind of behavior is a metabehavior, which, instead of modulating state variable values, adds or removes other behaviors based on conditions. I haven’t yet figured out the best way to represent this in the interface.
Final notes
There are a few additional features that would be great to include:
export models as JSON (or some other nice interchange format)
hierarchical simulations; i.e. take another model and include it as a node in another simulation. For instance, maybe you have a simulation about the internal workings of a company (modeling employees and so on) and you want to use that as a sub-simulation in a model of a national economy.
level-of-depth (LOD) and multiscale simulations
These extra features and some other aspects of the interface as described here (especially agent behaviors) require re-architecting of some of the backend, so I don’t know when we’ll be able to prototype the interface. I’m not totally confident that this approach will be general/flexible enough for more complex simulations, but we’ll see when we start to prototype and use it.
I’ve been interested in extending the work on Humans of Simulated New York into a more general agent-based simulation framework, one that is both accessible to non-technical audiences and powerful enough for more “professional” applications as well. We are all so ill-equipped to contend with the obscenely complex systems we’re a part of, and we end up relying on inadequate (and often damaging) heuristics that cause us to point blame at parties that either have little do with our problems or are similarly victimized by them. Maybe if we had tools which don’t require significant technical training to help us explore these causal rat’s nests, to make this insane interconnectedness more intuitive and presentable, we could think through and talk about these wicked problems more productively.
Recently Fei and I started working on a project, tentatively called “system designer” (syd for short), which we hope will provide a foundation for that kind of tooling. syd is currently functional but its features are provisional - I’ve included some examples of visualizations built on top of it, demoing simple models, although it is capable of more sophisticated agent-based models as well.
From an engineering perspective, the goal is to make it easy to write agent-based simulations which may have massive amounts of computationally demanding agents without having to deal with the messiness of parallel and distributed computing.
From a design perspective, the goal is to provide interfaces that make defining, running, visualizing, and analyzing such simulations an exploratory experience, almost like a simulation video game (e.g. SimCity).
In both the design and engineering cases there are many interesting challenges.
I’m going to discuss the engineering aspects of the project here and how syd is approaching some of these problems (but bear in mind syd is still in very early stages and may change significantly). At another point I’ll follow-up with more about the design and interface aspects (this is something we’re still sketching out).
syd is built on top of aiomas which handles lower-level details like inter-node communication, so I won’t discuss those here.
(note that at time of writing, not all of what’s discussed here has been implemented yet)
3D Schelling model with
The demands of simulation
If you’re conducting a relatively lightweight simulation, like cellular automata, in which agents are composed of a few simple rules, you can easily run it on a single machine, no problem. The update of a single agent takes almost no time.
Unfortunately, this approach starts to falter as you get into richer and more detailed simulations. In our first attempts at Humans of Simulated New York, Fei and I designed the agents to be fairly sophisticated - they would have their own preferences and plan out a set of actions for each day, re-planning throughout the day as necessary. Even with our relatively small action space (they could work, look for work, relax, or visit a doctor), this planning process can take quite awhile, especially when it’s executed by hundreds or thousands of agents.
Here you could turn to parallel or distributed methods: you’d take your population of agents, send them to a bunch of different threads or processes or computers (generally referred to as “multi-node” architecture), and then update them in parallel. For example, if you run your simulation across two machines instead of just one, you can almost double the speed of your simulation.
Normally to convert a single-node simulation to a multi-node one you’d have to change up your code to support communication across nodes and a laundry list of other things, but syd abstracts away the difference. You simply instantiate a ComputeSubstrate and you pass in either a single host or a list of hosts. If you pass a single host, the simulation runs in the local process; if a list of hosts, syd transparently runs it as a multi-node simulation:
That’s great, but it doesn’t come for free. Consider a simulation in which each agent must consult a few other agents before deciding what to do. For a single-node (here I’m using a “node” to refer to a single serial process) simulation this communication would happen quickly - all agents are in the same process so there’s basically no overhead to get data from one another.
As soon as we move to the multi-node case we have to worry about the overhead that network communication introduces. The computers we distribute our population across could be on separate continents, or maybe we just have a terrible internet connection, and there may be considerable lag if an agent on one node needs a piece of data from an agent on another node. This network overhead can totally erase all speed gains we’d get from distributing the simulation.
The typical way of managing this network overhead is to be strategic about how agents are distributed across the nodes. For example, if we’re simulating some kind of social network, maybe agents really only communicate with their friends and no one else. In this case, we’d want to put groups of friends in the same process so they don’t have to go over the network to communicate, and we’d effectively eliminate most of the network communication.
The problem here (maybe you’re starting to see a pattern) is that there is no one distribution strategy that works well for all conceivable agent-based simulations. It really depends on the particular communication patterns that happen within the simulation. In the literature around engineering these agent-based systems you’ll see mention of “spheres of influence” and “event horizons” which determine how to divide up a population across nodes. Agents that are outside of each other’s spheres of influence or beyond each other’s event horizons are fair game to send to different nodes. Unfortunately what exactly constitutes a “sphere of influence” or “event horizon” varies according to the specifics of your simulation.
In syd, if you create a multi-node substrate you can also specify a distribution strategy (a Distributor object) which determines which agents are sent to which nodes. So far there are only two strategies:
syd.distributors.RoundRobin: a naive round robin strategy that just distributes agents sequentially across nodes.
syd.distributors.Grid2DPartition: if agents live in a grid, this recursively bisects the grid into “neighborhoods” so that each neighborhood gets its own node. This is appropriate when agents only communicate with adjacent agents (e.g. cellular automata). Network communication still happens at the borders of neighborhoods, but overall network communication is minimized.
You can also define your own Distributor for your particular case.
There is yet another problem to consider - in some simulations, agents may be mobile; for example, if we’re simulating a grid world, we may distribute agents according to where in the grid they are (e.g. with the Grid2DPartition distributor), but what if they move to another part of the grid? We might want to move them to the node that’s running that part of the grid. But if this happens a lot, now we’ve introduced a ton of overhead shuffling agents from node to node.
As another example - if the topology of the simulation is a social network instead of a grid, such that they are communicating most with their friends, what happens if those relationships change over time? If they become friends with agents on another node, should we re-locate them to that node? Again, this will introduce extra overhead.
I haven’t yet come up with a good way of handling this.
Social network SIR model with
Race conditions and simultaneous updates
There is yet another problem to consider. With a single-node simulation, agents all update their states serially. There is no fear of race conditions: we don’t have to worry about multiple agents trying to simultaneously access a shared resource (e.g. another agent) and making conflicting updates or out-of-sync reads.
This is a huge concern in the multi-node case, and the way syd works around it is to separate agent updates into two distinct phases:
the decide phase, a.k.a. the “observation” or “read” phase, where the agent collects (“observes”) the information it needs from other agents or the world and then decides on what updates to make (but it does not actually apply the updates).
the update phase, a.k.a. the “write” phase, where the agent applies all queued updates.
So in the decide phase, agents queue updates for themselves or for other agents as functions that mutate their state. This has the effect of agents simultaneously updating their states, as opposed to updating them in sequence.
Unfortunately, this structure does not entirely solve our problems - it is possible that there are conflicting or redundant updates queued for an agent, and those usually must be dealt with in particular ways. I’m still figuring out a good way to manage this.
Node failures
Another concern is the possibility of node failure. What if a machine dies in the middle of your simulation? All the agents that were on that machine will be lost, and the simulation will become invalid.
The approach that I’m going to try is to snapshot all agent states every ¦n¦ steps (to some key-value store, ideally with some kind of redundancy in the event that one of those nodes fail!). If a node failure is detected, the simulation supervisor will automatically restart the simulation from the last snapshot (this could involve the spinning up of a new replacement machine or just continuing with one less machine).
Abstract the pain away
Long story short: parallel and distributed computing is hard. Fortunately for the end-user, most of this nasty stuff is hidden away. The plan is to include many “sensible defaults” with syd so that the majority of use-cases do not require, for example, the implementation of a custom Distributor, or any other messing about with the internals. You’ll simply indicate that you want your simulation to run on multiple computers, and it’ll do just that.
References
Antelmi, A., Cordasco, G., Spagnuolo, C. & Vicidomini, L. (2015). On Evaluating Graph Partitioning Algorithms for Distributed Agent Based Models on Networks. European Conference on Parallel Processing.
Bharti, R. (2016). HIVE - An Agent Based Modeling Framework. Master’s Projects.
Chenney, S. (2001). Simulation Level-of-Detail. Game Developers Conference.
Chenney, S. Simulation Culling and Level-of-Detail. IEEE Computer Graphics and Applications.
Chenney, S., Arikan, O. & Forsyth, D. (2001). Proxy Simulations for Efficient Dynamics. EUROGRAPHICS.
Chris Rouly, O. (2014). Midwife: CPU cluster load distribution of Virtual Agent AIs. Complex, Intelligent and Software Intensive Systems (CISIS).
He, M., Ruan, H. & Yu, C. (2003). A Predator-Prey Model Based on the Fully Parallel Cellular Automata. International Journal of Modern Physics C.
Holcombe, M., Coakley, S., Kiran, M., Chin, S., Greenough, C., Worth, D., Cincotti, S., Raberto, M., Teglio, A., Deissenberg, C., van der Hoog, S., Dawid, H., Gemkow, S., Harting, P. & Neugart, M. (2013). Large-Scale Modeling of Economic Systems. Complex Systems, 22.
K. Bansal, A. (2006). Incorporating Fault Tolerance in Distributed Agent Based Systems by Simulating Bio-computing Model of Stress Pathways. Proceedings of SPIE, 6201.
K. Som, T. & G. Sargen, R. (2000). Model Structure and Load Balancing in Optimistic Parallel Discrete Event Simulation. Proceedings of the Fourteenth Workshop on Parallel and Distributed Simulation.
Kim, I., Tsou, M. & Feng, C. (2015). Design and implementation strategy of a parallel agent-based Schelling model. Computers, Environment and Urban Systems, 49(2015), pp. 30-41.
Kubalík, J., Tichý, P., Šindelář, R. & J. Staron, R. (2010). Clustering Methods for Agent Distribution Optimization. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews).
Lees, M., Logan, B., Oguara, T. & Theodoropoulos, G. (2004). Simulating Agent-Based Systems with HLA: The Case of SIM_AGENT - Part II. International Conference on Computational Science.
Logan, B. & Theodoropoulos, G. (2001). The Distributed Simulation of Multi-Agent Systems. Proceedings of the IEEE, 89(2).
Lysenko, M. & M. D’Souza, R. (2008). A Framework for Megascale Agent Based Model Simulations on Graphics Processing Units. Journal of Artificial Societies and Social Simluation, 11(4/10). http://jasss.soc.survey.ac.uk/11/4/10.html.
Márquez, C., César, E. & Sorribes, J. (2015). Graph-Based Automatic Dynamic Load Balancing for HPC Agent-Based Simulations. European Conference on Parallel Processing.
Navarro, L., Flacher, F. & Corruble, V. (2011). Dynamic Level of Detail for Large Scale Agent-Based Urban Simulations. Proceedings of 10th International Conference on Autonomous Agents and Multiagent Systems, pp. 701-708.
Oey, M., van Splunter, S., Ogston, E., Warnier, M. & M.T. Brazier, F. (2010). A Framework for Developing Agent-Based Distributed Applications. BNAIC 2010: 22rd Benelux Conference on Artificial Intelligence.
Pleisch, S. & Schiper, A. (2000). Modeling Fault-Tolerant Mobile Agent Execution as a Sequence of Agreement Problems. Reliable Distributed Systems.
Richiardi, M. & Fagiolo, G. (2014). Empirical Validation of Agent-Based Models.
Rousset, A., Herrmann, B., Lang, C. & Philippe, L. (2015). A communication schema for parallel and distributed Multi-Agent Systems based on MPI. European Conference on Parallel Processing.
Rubio-Campillo, X. (2014). Pandora: A Versatile Agent-Based Modelling Platform for Social Simulation. SIMUL 2014: The Sixth International Conference on Advances in System Simulation.
Scheutz, M. & Schermerhorn, P. (2006). Adaptive Algorithms for the Dynamic Distribution and Parallel Execution of Agent-Based Models. Journal of Parallel and Distributed Computing.
Sunshine-Hill, B. (2013). Managing Simulation Level-of-Detail with the LOD Trader. Motion in Games.
Tsugawa, S., Ohsaki, H. & Imase, M. (2012). Lightweight Distributed Method for Connectvity-Based Clustering Based on Schelling’s Model. 26th International Conference on Advanced Information Networking and Applications Workshops.
Vecchiola, C., Grosso, A., Passadore, A. & Boccalatte, A. (2009). AgentService: A Framework for Distributed Multi-Agent System DEvelopment. International Journal of Computers and Applications, 31(3), pp. 204-210.
Dubitzky, W., Kurowski, K., & Schott, B, eds. (2012). Large-Scale Computing Techniques for Complex System Simulations.
For our month-long DBRS Labs residency, Fei and I built the beginnings of a tool set for economy agent-based simulation. My gut feeling is the next phase of this AI renaissance will be around simulation. AlphaGo’s recent victory over the Go world champion - a landmark in AI history - resulted from a combination of deep learning and simulation techniques, and we’ll see more of this kind of hybrid.
Simulation is important to planning, a common task in AI. Here “planning” refers to any task that requires producing a sequence of actions (a “plan”) that leads from a starting state to goal state. An example planning problem might be: I need to get to London (starting state) from New York (goal state), what’s the best way of getting there? A good plan for this might be: book a flight to London, take a cab to the airport, get on the flight. But there are infinitely many other plans, depending on how detailed you want to get. I could walk and swim to London - it’s not a very good plan, but it’s a plan nonetheless!
To produce such plans, there needs to be a way of anticipating the outcome of certain actions. This is where simulation comes in. For example, in deciding how to get to the airport, I have to consider various scenarios - traffic could be bad at this particular hour, maybe there’s some chance the cab breaks down, and so on. Simulation is the consideration of these scenarios.
So simulation, especially as it relates to planning, is crucial to AI’s more interesting applications, such as policy and economic simulation which seeks to understand the implications of policy decisions. Much like machine learning, planning and simulation have a long history and are already used in many different contexts, from shipping logistics to spacecraft. The residency was a great opportunity to begin exploring this space.
First plan
The general idea was to use a simulation technique called agent-based modeling, in which a system is represented as individual agents - e.g. people - that have predefined behaviors. These agents all interact with one another to produce emergent phenomena - that is, outcomes which cannot be attributed to any individual but rather arise from their aggregate interactions. The whole is greater than the sum of its parts.
Originally we aimed to create a literal simulation of New York City and use it to generate narratives of its agents: simulated citizens (“simulants”). We wanted to produce a simulation heavily drawn from real world data, collating various data sources (census data, market data, employment data, whatever we could scrap together) and unpacking their abstract numbers into simulated lives. Data ostensibly is a compact way of representing very nuanced phenomena - it lossy-compresses a person’s life. Using simulation to play out the rich dynamics embedded within the data seemed like a good way to (re-)vivify it. It wouldn’t reach the fidelity and honesty of lived experience, but might nevertheless be better than just numbers.
Over time though we became more interested in using simulation to postulate different world dynamics and see how those played out. What would the world look like if people behaved in this way or had these values? What would happen to this group of people if the government instituted this policy? What happens to labor when technology is productive enough to replace them? What if the world had less structural inequality than it does now?
Acknowledgements
This speculative direction had many inspirations:
Past and speculated initiatives around AI and governance were one - in particular, Allende’s Cybersyn, the ambitious, way-before-its-time attempt to manage an economy via networked computation under the control of the workers, and the imagined AI-managed civilization of Iain M. Banks’ Culture. These reached for utopian societies in which many, if not all, aspects were managed by some form of artificial intelligence, presumably involving simulation to understand the societal impacts of its decisions.
Cybersyn’s consoles (via )
Another big inspiration was speculative social science fiction such as Ursula K. Le Guin’s “Hainish Cycle”, which explores how differences in fundamental aspects of humans lead to drastically different societies. From these we aspired to create something which similarly carves out a space to hypothesize alternative worlds and social conditions.
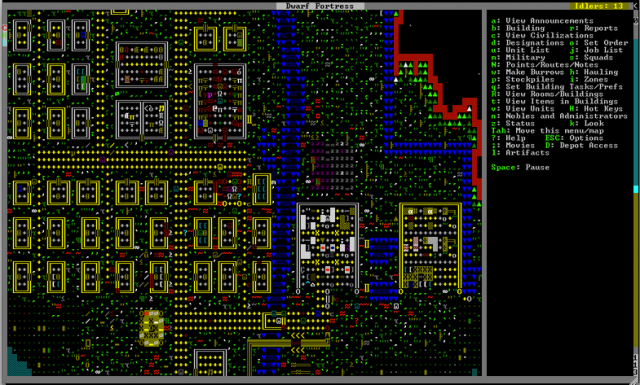
Dwarf Fortress (via )
We also referred to what could be called “generative narrative” video games. In these games, no story is fixed or preordained; rather, only the dynamics of the game world are defined. Things take on a life of their own. Bay 12 Games’ Dwarf Fortress is one of the best examples of this - a meticulously detailed simulation of a colony of dwarves which almost always ends in tragedy. Dwarf Fortress has inspired other games such as RimWorld, which follows the same general structure but on a remote planet. Beyond the pragmatic applications of economic simulation, the narrative aspect produces characters and a society to be invested in and to empathize with.
In a similar vein, we looked at management simulation games, such as SimCity/Micropolis, Cities: Skylines (by Paradox Interactive, renowned for their extremely detailed sim games), Roller Coaster Tycoon, and more recently, Block’hood, from which we took direction. These games provide a lot of great design cues for making complex simulations easy to play with.
Micropolis & Block’hood
Game of Life
In both a literal and metaphorical way, these simulation games are essentially Conway’s Game of Life writ large. The Game of Life is the prototypical example of how a set of simple rules can lead to emergent phenomena of much greater complexity. Its world is divided into a grid, where each cell in the grid is an agent. Each cell has two possible states: on (alive) or off (dead). The rules which govern these agents may be something like:
a cell dies if it has only one or no neighbors
a cell dies if it is surrounded by four or more neighbors
a dead cell becomes alive if it has three neighbors
How the system plays out can vary drastically depending on which cells start alive. Compare the following two - both use the same rules, but with different initial configurations (these gifs are produced from this demo of the Game of Life).
Game of Life: Small Exploder vs Tumbler
This is characteristic of agent-based models: different starting conditions and parameters can lead to fantastically different outcomes.
Navigating complexity
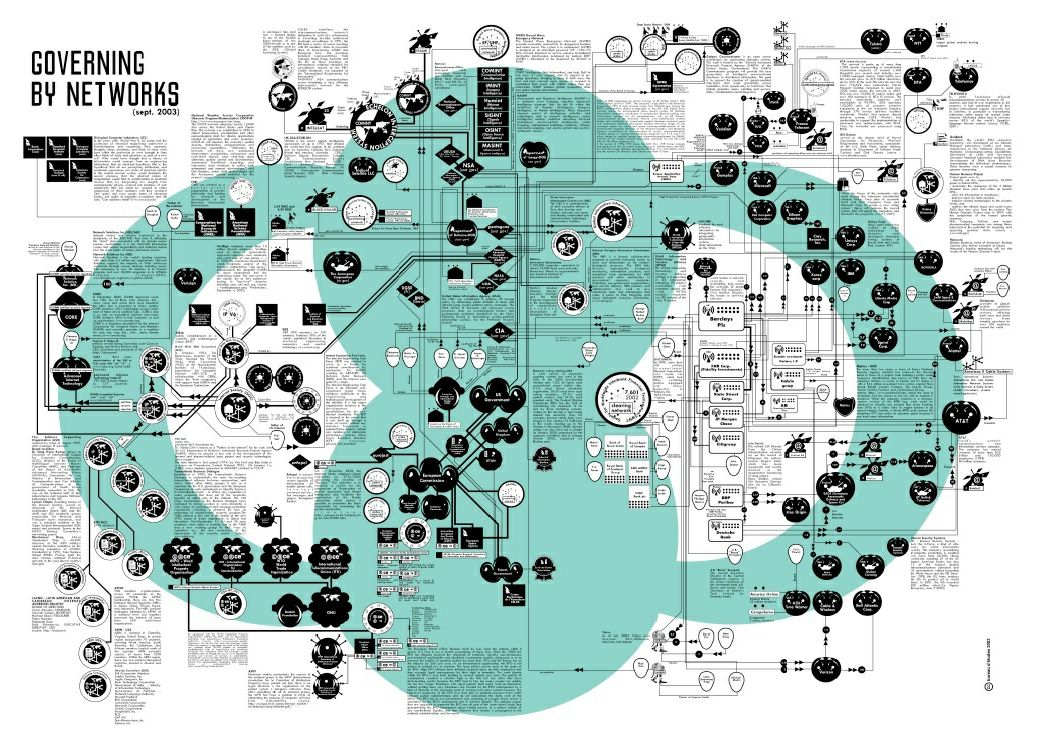
Interactive and well-designed simulation can also function as an educational tool, especially for something as complex as an economy. The dissociation between our daily experience and the abstract workings of the economy is massive. Trying to think about all its moving parts induces a kind of vertigo, and there is no single position from which the whole can be seen. While our project is not there yet, perhaps it may eventually aid in the cognitive mapping Fredric Jameson calls for in Postmodernism: “a situational representation on the part of the individual subject to that vaster and properly unrepresentable totality which is the ensemble of society’s structures as a whole”. Bureau d´Études’ An Atlas of Agendas attempts this mapping by painstakingly notating nauseatingly sprawling networks of power and influence, but it is still quite abstract, intimidating, and disconnected from our immediate experience.
Bureau d´Études’s
Nick Srnicek calls for something similar in Accelerationism - Epistemic, Economic, Political (from Speculative Aesthetics):
So this is one thing that can help out in the current conjuncture: economic models which adopt the programme of epistemic accelerationism, which reduce the complexity of the world into aesthetic representations, which offer pragmatic purchase on manipulating the world, and which are all oriented toward the political accelerationist goals of building and expanding rational freedom. These can provide both navigational tools for the current world, and representational tools for a future world.
Today’s cyberlearning–the tight coupling of cyber-technology with learning experiences offering deeply integrated and personally attentive artificial intelligence–is critical to addressing these global, seemingly intractable, challenges. Cyberlearning provides us (1) access to information and (2) the capacity to experience this information’s implications in diverse and visceral ways. It helps us understand, communicate, and engage productively with multiple perspectives, promoting inclusivity, collaborative decision-making, domain and transdisciplinary expertise, self actualization, creativity, and innovation (Burleson 2005) that has transformative societal impact.
We found some encouragement for this approach in Modeling Complex Systems for Public Policies, which was published last year and covers the current state of economic and public policy modeling. In the preface, Scott E. Page writes:
…whether we focus our lens on the forests or students of Brazil or the world writ large, we cannot help but see the inherent complexity. We see diverse, purposeful connecting people constructing lives, interacting with institutions, and responding to rules, constraints, and incentives created by policies. These activities occur within complex systems and when the activities aggregate they produce feedbacks and create emergent patterns and functionalities. By definition, complex systems are difficult to describe, explain, and predict, so we cannot expect ideal policies. But we can hope to improve, to do better. (p. 14)
Early attempts
We had a lot of anxiety in the deciding on the simulation’s level of detail. There were a few constraints which prevent us from going too crazy, e.g. computational feasibility (whether or not we can run the simulation in a reasonable amount of time) and sensitivity/precision issues (i.e. all the problems of modeling chaotic systems). These practical concerns were offset by a desire to represent all the facets of life we were interested in, which was too ambitious. This main tension is best described by Borges’ On Exactitude in Science, where a map is so detailed that it directly overlays the terrain it is meant to represent. A large part of modeling’s value is that it does not seek a one-to-one representation of its referent, generally because it is not only impractical but because the point of a model is to capture the essence of a system without too much noisy detail. For us, the details were important, but we also avoided too literal a model to leave some space for the simulation to surprise us.
Planning agents
First we tried fairly sophisticated simulants, which each had their own set of utility functions. These utility functions determined, for instance, how important money was to them or how much stress bothered them. Some agents valued material wealth over mental health and were willing to work longer hours, while others valued relaxation.
We went way too granular here. Agents would make a plan for their day, hour-by-hour, involving actions such as relaxing, looking for work, seeing friends, going to work, sleeping, visiting the doctor, and so on. Agents used A* search (a powerful search algorithm) to generate a plan they believed would maximize their utility, then executed on that plan. Some actions might be impossible from their current state - for instance, they might be sick and want to visit the doctor, but not have enough money - but agents could set these desired actions as long-term goals and work towards them.
To facilitate developing these kinds of goal-oriented agents, we built the cess framework. Because there is a lot of computation happening here, cess includes support for running a simulation across a cluster. However, even with the distributed computation, modeling agents at this level of detail was too slow for our purposes (we wanted something snappy and interactive), so we abandoned this approach (development of cess will continue separately).
A simple economy
Given that our residency was for only a month, we ended up going with something simple: a conventional agent-based model of a very basic economy, with flexibility in defining the world’s parameters. A lot of what we wanted to include had to be left out. A good deal of the final simulation was based on previous work (of which there is plenty) in economic modeling. In particular:
In addition to our simulants (the people), we also had firms, which included consumer good firms, capital equipment firms, raw material firms, and hospitals, and the government. The firms use Q-learning, as described in “An agent-based model of a minimal economy”, to make production and pricing decisions. Q-learning is a reinforcement learning technique where the agent is “rewarded” for taking certain actions and “punished” for taking others, so that they eventually know how to act under certain conditions. Here firms use this to learn when producing more or less is a good idea and what profit margins consumers will tolerate.
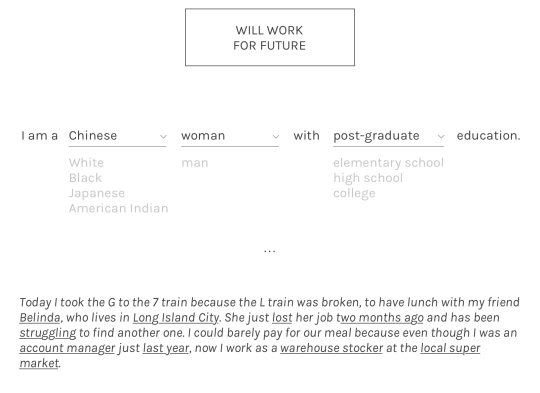
We still wanted to start from something resembling our world, at least to make the very tenuous claim that our simulation actually proves anything a tiny bit less tenuous. We gathered individual-level American Community Survey data from IPUMS USA and used that to generate “plausible” simulated New Yorkers. At first we tried trendy generative neural net methods like generative adversarial networks and variational autoencoders, but we weren’t able to generate very believable simulants that way. In the end we just learned a Bayes net over the data (I hope this project’s lack of neural nets doesn’t detract from its appeal 😊), which turned out pretty well.
A Bayes net allows us to generate new data that reflects real-world correlations, so we can do things like: given a Chinese, middle-aged New Yorker, what neighborhood are they likely to live in, and what is their estimated income? The result we get back won’t be “real” as in the data isn’t connected to a real person, but it will reflect the patterns in the original data. That is to say, it could be a real person.
The code we use to generate simulants is available here. This is basically what it does:
>>>frompeopleimportgenerate>>>year=2005>>>generate(year){'age':36,'education':<Education.grade_12:6>,'employed':<Employed.non_labor:3>,'wage_income':3236,'wage_income_bracket':'(1000, 5000]','industry':'Independent artists, performing arts, spectator sports, and related industries','industry_code':8560,'neighborhood':'Greenwich Village','occupation':'Designer','occupation_code':2630,'puma':3810,'race':<Race.white:1>,'rent':1155.6864868468731,'sex':<Sex.female:2>,'year':2005}
This is how we spawned our population of simulants. Because we were also interested in social networks, simulants could become friends with one another. We ripped out the parameters from the logistic regression model (the “confidant model” in the graphic below) described in Social Distance in the United States: Sex, Race, Religion, Age, and Education Homophily among Confidants, 1985 to 2004 (Jeffrey A. Smith, Miller McPherson, Lynn Smith-Lovin, University of Nebraska - Lincoln, 2014) and used that to build out the social graph. This social network determined how illnesses and job opportunities spread.
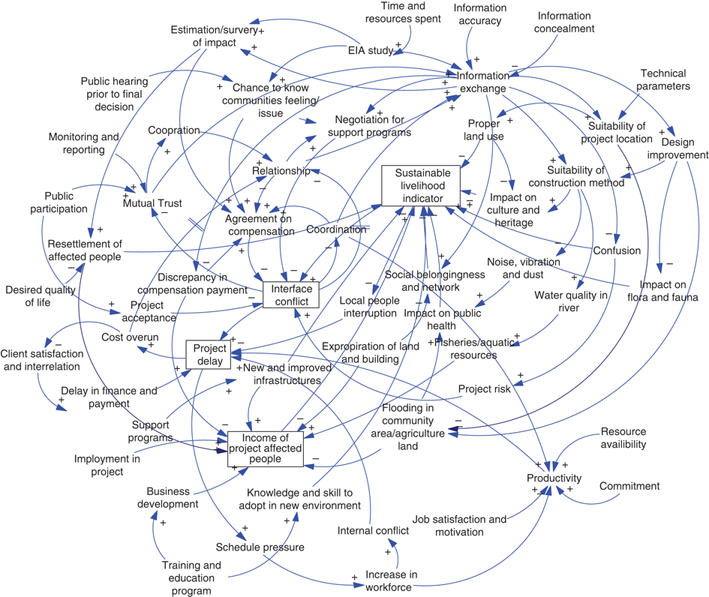
The graphic below goes into the simulation design in more detail:
An overview of the simulation design
We designed the dynamics of the world so it could model some of the questions posed earlier. For instance, we modeled production and productive technology to explore the idea of automation. Say it takes 10 labor to produce a good, each worker produces 20 labor, and equipment adds an additional 10 labor. Now say your firm wants to produce 10 goods, which requires 100 labor. If you have no equipment, you would need five workers (5*20=100). However, if you have equipment for each worker, you only need four workers (4*(20+10)=120). (In our simulation, each piece of equipment requires one worker to operate it, so you can’t just buy 10 pieces of equipment and not hire anyone). To model a more advanced level of automation, we could instead say that each piece of equipment now produces 100 labor, and now to meet that product quota, we only need one worker (1*(20+100)=120). Then we just hit play and see what happens to the world.
An early version of the city
Steering the city
As Ava Kofman points out in “Les Simerables”, these kinds of simulations embed their creators’ assumptions about how the world does or should work. Discussing the dynamics of SimCity, she notes:
To succeed even within the game’s fairly broad definition of success (building a habitable city), you must enact certain government policies. An increase in the number of police stations, for instance, always correlates to a decrease in criminal activity; the game’s code directly relates crime to land value, population density, and police stations. Adding police stations isn’t optional, it’s the law.
Or take the game’s position on taxes: “Keep taxes too high for too long, and the residents may leave your town in droves. Additionally, high-wealth Sims are more averse to high taxes than low- and medium-wealth Sims.”
The player’s exploration of utopian possibility is limited by these parameters. The imagination extolled by Wright is only called on to rearrange familiar elements: massive buildings, suburban quietude, killer traffic. You start each city with a blank slate of fresh green land, yet you must industrialize.
The landscape is only good for extracting resources, or for being packaged into a park to plop down so as to increase the value of the surrounding real estate. Certain questions are raised (How much can I tax wealthy residents without them moving out?) while others (Could I expropriate their wealth entirely?) are left unexamined.
These assumptions seem inevitable - something has to glue together the interesting parts - but they can be designed to be transparent and mutable. Unlike the assumptions with which we operate daily, these assumptions must be made explicit through code. Keeping all of this in mind, we wanted to make the simulation interactive in such a way that you can alter the fundamental parameters which govern the economy’s dynamics. But, while you can tweak numbers of the system, you can’t yet change the rules themselves. That’s something we’d like to add down the line.
An early idea for player interaction
We played around with a few ideas for making the simulation interactive. At first we thought to have individuals create their own characters, specifying attributes such as altruism and frugality. Then we would run the player’s simulant through a year of their life and generate a short narrative about what happened. How the simulant behaves is dependent on the attributes the player input, as well as data-derived environmental factors. One of our goals was to model structural inequality and oppression, so depending on who you are, you may be, for instance, more or less likely to be hired.
World building was a very important component to us. By keeping all player-created individuals as part of the population for future players, the world is gradually shaped to reflect the values of all the people who have interacted with it. (Unfortunately we didn’t have time to implement this yet.)
We didn’t quite go that route in the end. Because we’ll demo the simulation to an audience, we wanted to design for that format - simultaneous participation. In the latest version, players propose and vote on new legislation between each simulated month and try to produce the best outcome (in terms of quality of life) for themselves and/or everyone.
The simulants in the city are meant to visualize structural inequality, as derived from American Community Survey and New York unemployment data (a full list of data sources is available in the project’s GitHub repo). We borrowed from Flatland’s hierarchy of shapes and made it so that polygon count correlates with economic status. So in our world, pyramids are unemployed, cubes are employed, and spheres are business owners. The simulant shapes are then colored according to Census race categories. It becomes pretty clear that certain colors have more spheres than others.
Differentiating simulants by shape and color
The city’s buildings also convey some information - each rectangular slice represents a different business, and each color corresponds to a different industry (raw material firms, consumer good firms, capital equipment firms, and hospitals). The shifting colors and height of the city becomes an indicator of economic health and priority - as sickness spreads, hospitals spring up accordingly.
Changing tenants in a building
For other indices, we fall back to basic line charts. An important one is the quality of life chart, which gives a general indication about how content the citizens are. Quality of life is computed using food satisfaction (if they can buy as much food - the consumer good in our economy - as they need) and health.
In many scenarios, the city collapses under inflation and gradually slouches into destitution. One by one its simulants blink out of existence. It’s really hard to strike the balance for a prosperous city. And the way the economy organized - market-based, with the sole guiding principle of expanding firm profits - is not necessarily conducive to that kind of success.
Mere speculation
Players can choose from a few baked-in scenarios along the axes of food, technology, and disease:
food
a bioengineered super-nutritional food is available
“regular” food is available
a blight leaves only poorly nutritional food
technology
hyper-productive equipment is available
“regular” technology is available
a massive solar flare from the sun disables all electronic equipment
disease
disease has been totally eliminated
“regular” disease
an extremely infectious and severe disease lurks
A post-scarcity society is one option
So people can see how things play out in a vaguely utopian, dystopian, or “neutral” (closer to our world) setting. Sometimes these scenarios play out as you’d expect - the infectious disease scenario wipes out the population in a month or two - but not always. Hyper-productive equipment, for instance, can lead to misery, unless other parameters (such as government) are collectively adjusted by players.
Where could this go?
These simulations are promising in domains like public policy - with movements like “smart cities”, it seems inevitable that this application will become ubiquitous - but their potential is soured by the reality of how policy and technological decisions are made in practice. Technological products tend to reproduce the power dynamics that produced them. As alluded to in Eden Medina’s piece, Cybersyn could have easily been implemented as a top-down control system instead of something which the workers actively participated in and took some degree of ownership over.
So it could go either way, really.
To me the value of these simulations is as a means to speculate about what the world could be like, to see how much better (or worse) things might be given a few changes in our behavior or our relationships or our environment. We seem to be reaching a high-water mark of stories about dystopia (present and future), and it has been harder for me to remember that “another world is possible”. Our project is not yet radical enough in the societies it can postulate, but we hope that these simulations can serve as a reminder that things could be different and provide a compelling vision of a better world to work towards.
A big thank you to Amelia Winger-Bearskin and the rest of the DBRS Labs folks for their support and to Jeff Tarakajian for answering our questions about the Census!