I recently wrote a conspiracy-generating bot for The New Inquiry's Conspiracy issue. The basic premise is that far-fetched conspiracy theories emerge from the human tendency for apophenia - finding meaning in random patterns - and that the problematic algorithm-level aspects of machine learning are instances of a similar phenomenon. The bot leverages how computer models can misidentify faces and objects as similar and presents these perceptual missteps as significant discoveries, encouraging humans to read additional layers of absent meaning.
The bot consists of the following core components:
In this post I'll give a high-level explanation for the basic structure of the bot. If you're interested in details, the full source code is available here.
Sourcing images, the material of conspiracy
For this bot the ideal conspiracy is one that connects seemingly unrelated and distance events, people, and so on not only to each other but across time. If that connection is made to something relevant to the present, all the better. The bot's source material then should combine obscure images with a lot of breadth (encompassing paintings, personal photos, technical drawings, and the like) with immediately recognizable ones, such as those from recent news stories.
Wikimedia Commons is perfect for the former. This is where all of Wikipedia's (and other Wiki sites') images are hosted, so it captures the massive variety of all those platforms. Wikimedia regularly makes full database dumps available, including one of all of the Commons' image links (commonswiki-latest-image.sql.gz). Included in the repo is a script that parses these links out of the SQL. The full set of images is massive and too large to fit on typical commodity hard drives, so the program provides a way to download a sample of those images. As each image is downloaded, the program runs object recognition (using YOLO; "people" are included as objects) and face detection (using dlib), saving the bounding boxes and crops of any detected entities so that they are easily retrieved later.
Extracted faces and objects
For recent news images the bot uses reality, a simple system that polls several RSS feeds and saves new articles along with their main images and extracted named entities (peoples, places, organizations, and so on). When new articles are retrieved, reality updates a FIFO queue that the bot listens to. On new articles, the bot runs object recognition and face detection and adds that data to its source material, expanding its conspiratorial repertoire.
Each of these sources are sampled from separately so that every generated conspiracy includes images from both.
At time of writing, the bot has about 60,000 images to choose from.
Generating conspiracies
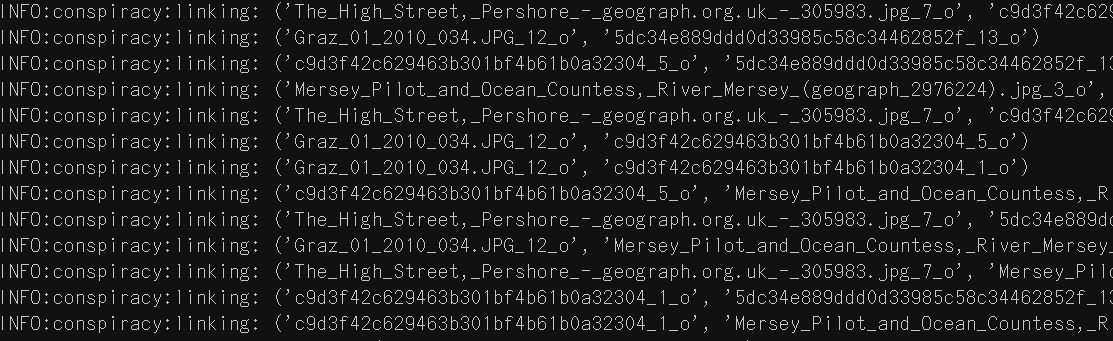
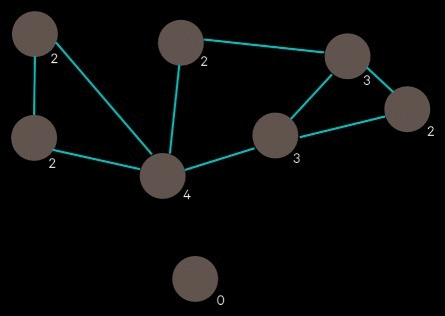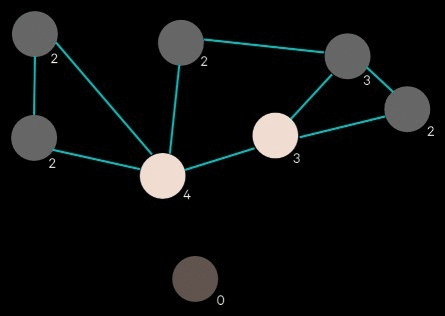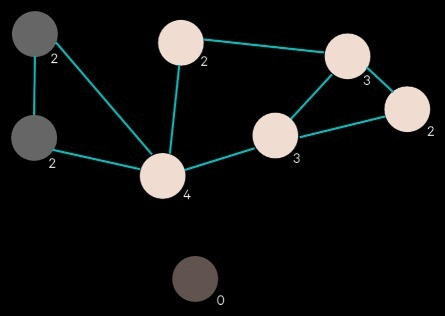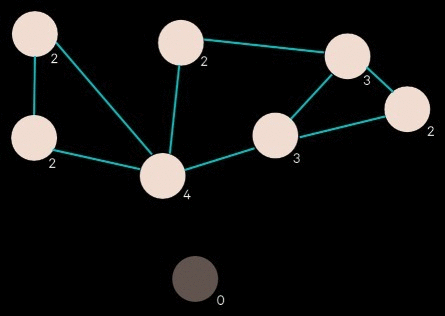
To generate a conspiracy, 650 images are sampled and their entities (faces and objects) are retrieved. The program establishes links between these entities based on similarity metrics; if two entities are similar enough, they are considered related and included in the conspiracy.
Face and object distance matrices
The FaceNet model used to compute face similarity. For objects, a very naive approach is used: the perceptual hashes of object crops are directly compared (perceptual hashes are a way of "fingerprinting" images such that images that look similar will produce similar hashes).
Links generated by similarity
Because reality saves a news article's text along with its image, we can also search through that text and its extract entities to pull out text-based conspiracy material. The program starts by looking for a few simple patterns in the text, e.g. ENTITY_A is ... ENTITY_B, which would match something like Trump is mad at Comey. If any matches are found, a screenshot of the article's page is generated. Then optical character recognition (OCR) is run on the screenshot to locate one of those extracted phrases. If one is found, a crop of it is saved to be included in the final output.
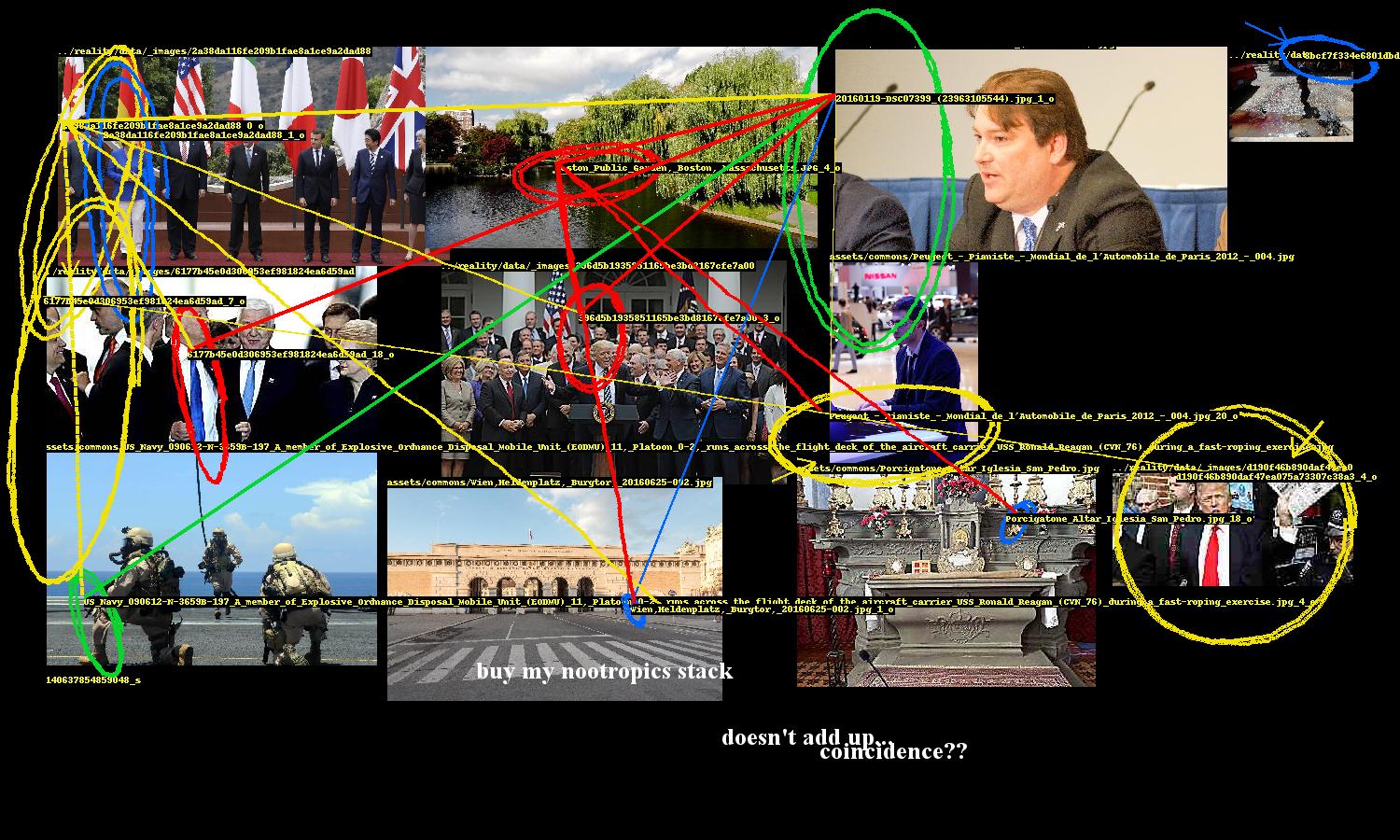
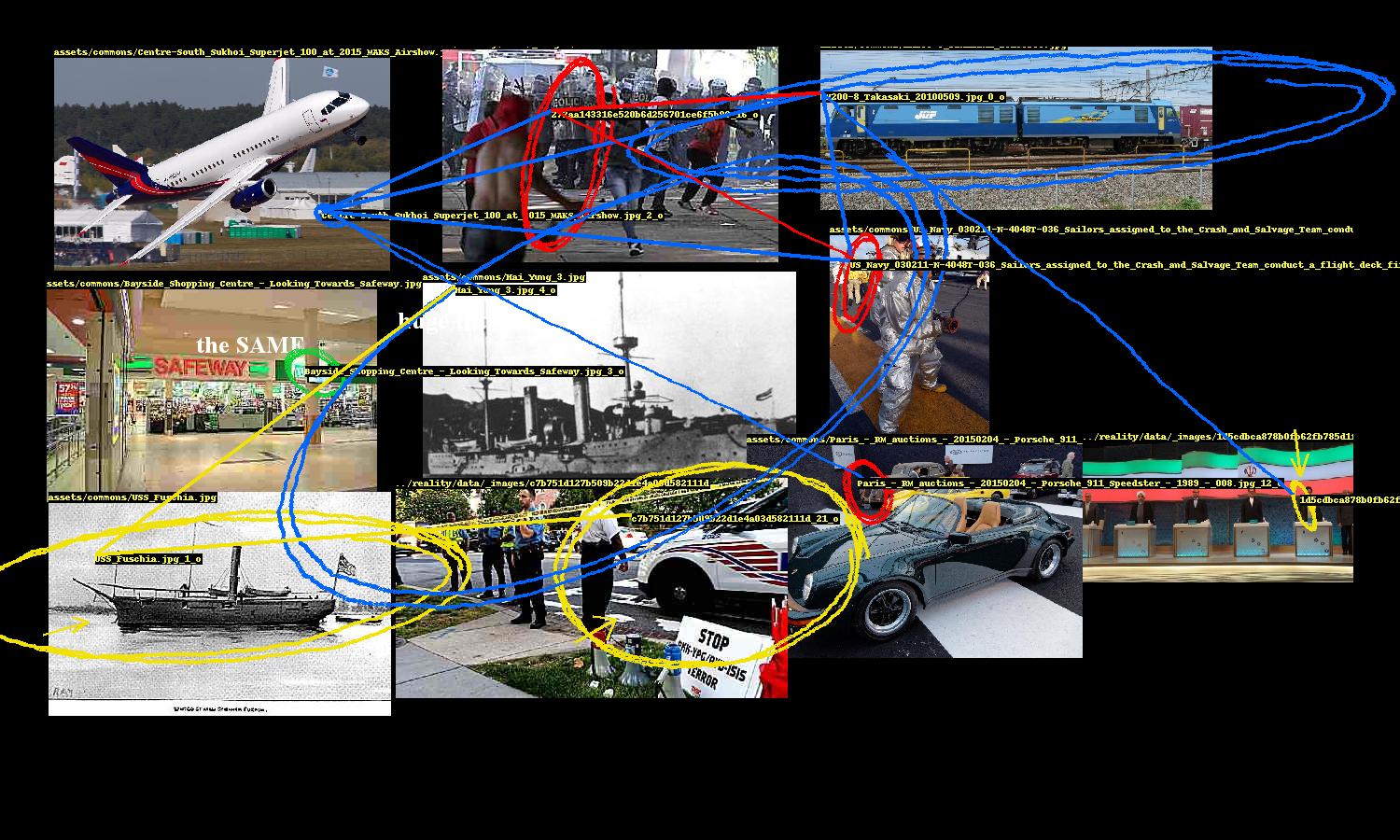
This network of entity relationships forms the conspiracy. The rest of the program is focused on presentation.
Image layout and annotation
Once relationships between faces and objects are established, the next challenge is to present the implicated images in a convincingly conspiratorial way. This problem breaks down into two parts: image 1) layout and 2) annotation.
1) Layout
Layout is tricky because it's a bin packing problem, which is NP-hard, but fortunately there exists implementations of good solutions, such as rectpack, which is used here. There is no guarantee that all of the selected images will fit, so there is some additional processing to ensure that the images that do get included have a maximal amount of connectivity between them.
The generated network of entity relationships forms a graph of the selected images. Two images have an edge between them if at least one pair of their entities are linked. We start with the image that has the highest degree (i.e. the image that is connected to the most other images). We look at what images its connected to and pick the image with the highest degree out of those, and repeat. The result is a sequence of connected images, descending by degree.
Ordering images based on links
Here's where some style is added. Images are not placed exactly as prescribed by the bin packing algorithm; there is some "shakiness" where they are placed with some margin of error. This gives the layout a rushed, haphazard look, enhancing the conspiracy vibe.
2) Annotation
A conspiracy's entities need to be highlighted and the links between them need to be drawn. While Pillow, Python's de facto image processing library, provides ways to draw ellipses and lines, they are too neat and precise. So the program includes several annotation methods to nervously encircle these entities, occasionally scrawl arrows pointing to them, and hastily link them.
These were fun to design. The ellipse drawing method uses an ellipse function where the shape parameters a, b are the width and height of the entity's bounding box. The function is rotated to a random angle (within constraints) and then the ellipse is drawn point by point, with smooth noise added to give it an organic hand-drawn appearance. There are additional parameters for thickness and how many times the ellipse should be looped.
"Hand-drawn" annotations
This part of the program also includes computer text, which are randomly sampled from a set of conspiracy clichés, and also writes entity ids on the images.
Text annotations
Further manipulation
Images are randomly "mangled", i.e. scaled down then back up, unsharpened, contrast-adjusted, then JPEG-crushed, giving them the worn look of an image that has been circulating the internet for ages, degraded by repeat encodings.
Image mangling
Assembling the image
Once all the images are prepared, placed, and annotated, the final image is saved and added to the webpage.
There you have it - an algorithm for conspiracies.
Last weekend Fei, Dan, and I put on our first Party Fortress party.
Fei and I have been working with social simulation for awhile now, starting with our Humans of Simulated New York project from a year ago.
Over the past month or two we've been working on a web system, "highrise" to simulate building social dynamics.
The goal of the tool is to be able to layout buildings and specify the behaviors of its occupants, so as to see how they interact with each other and the environment, and how each of those interactions influences the others.
Beyond its practical functionality (it still has a ways to go), highrise is part of an ongoing interest in simulation and cybernetics. Simulation is an existing practice that does not receive as much visibility as AI but can be just as problematic. It seems inevitable that it will become the next contested space of technological power.
highrise is partly a continuation of our work with using simulation for speculation, but whereas our last project looked at the scale of a city economy, here we're using the scale of a gathering of 10-20 people. The inspiration for the project was hearing Dan's ideas for parties, which are in many ways interesting social games. By arranging a party in a peculiar way, either spatially or socially, what new kinds of interactions or relationships emerge? Better yet, which interactions or relationships that we've forgotten start to return? What relationships that we've mythologized can (re)emerge in earnest?
highrise was the engine for us to start exploring this, which manifested in Party Fortress.
I'll talk a bit about how highrise was designed and implemented and then the living prototype Party Fortress.
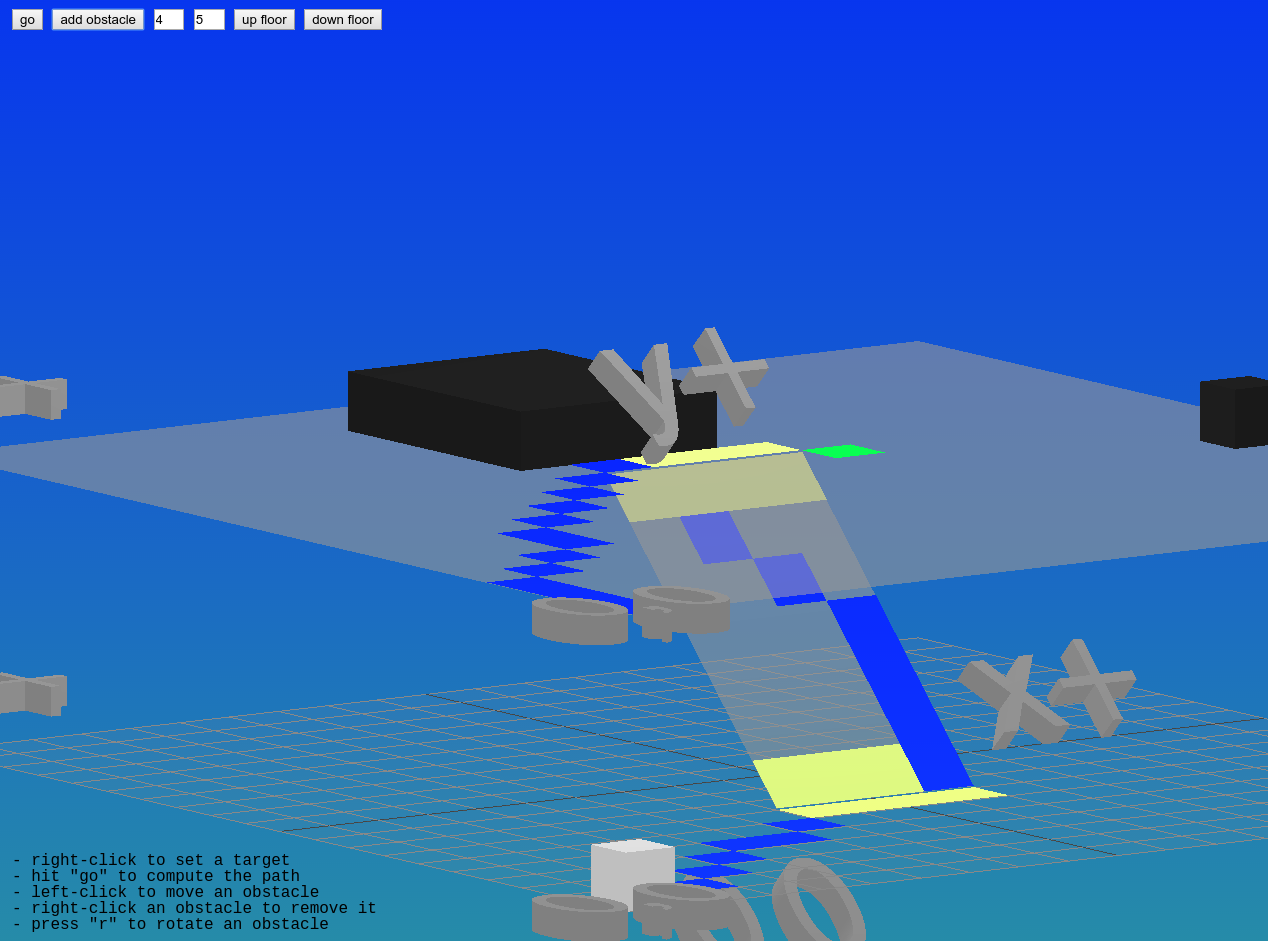
Buildings: Floors and Stairs
First we needed a way to specify a building. We started by reducing a "building" to just floors and stairs, so we needed to develop a way to layout a building by specifying floor plans and linking them up with stairs.
Early sketches of highrise
We wanted floor plans to be easily specified without code, so developing some simple text structure seemed like a good approach. The first version of this was to simply use numbers:
Here 0 is empty space, 1 is walkable, and 2 is an obstacle. In the example above, each 2D array is a floor, so the complete 3D array represents the building. Beyond one floor it gets a tad confusing to see them stacked up like that, but this may be an unavoidable limitation of trying to represent a 3D structure in text.
Note that even though we can specify multiple floors, we don't have any way to specify how they connect. We haven't yet figured out a good way of representing staircases in this text format, so for now they are explicitly added and positioned in code.
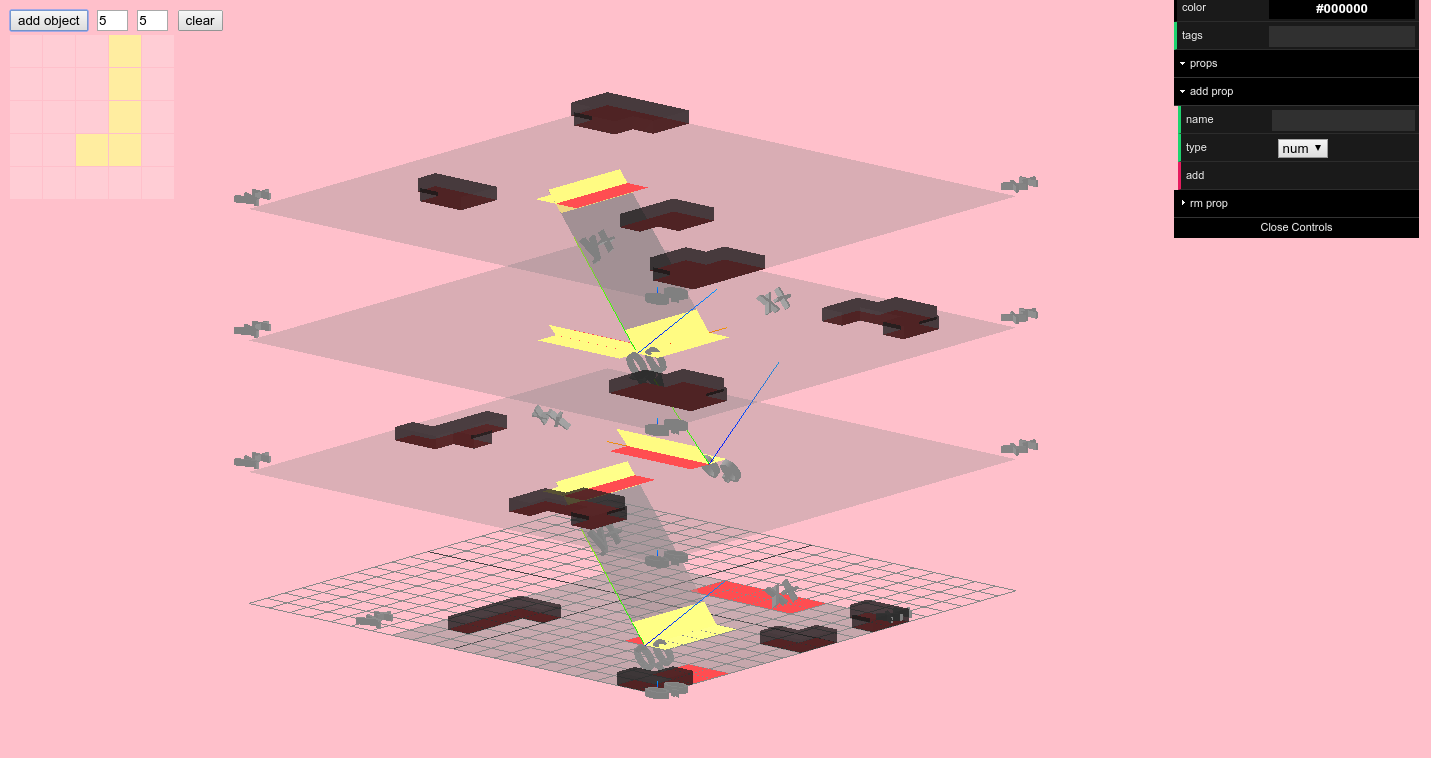
Objects
A floor plan isn't enough to properly represent a building's interior - we also needed a system for specifying and placing arbitrary objects with arbitrary properties. To this end we put together an "object designer", depicted below in the upper-left hand corner.
The object designer
The object designer is used to specify the footprint of an object, which can then be placed in the building. When an object is clicked on, you can specify any tags and/or key-value pairs as properties for the object (in the upper-right hand corner), which agents can later query to make decisions (e.g. find all objects tagged food or toilet).
Objects can be moved around and their properties can be edited while the simulation runs, so you can experiment with different layouts and object configurations on-the-fly.
Expanding the floor plan syntax
It gets annoying to need to create objects by hand in the UI when it's likely you'd want to specify them along with the floor plan. We expanded the floor plan syntax so that, in addition to specifying empty/walkable/obstacle spaces (in the new syntax, these are '-', ' ', and '#' respectively), you can also specify other arbitrary values, e.g. A, B, ☭, etc, and these values can be associated with object properties.
And when initializing the simulation world, you can specify what A is with an object like this:
{"A":{"tags":["food"],"props":{"tastiness":10}}}
This still isn't as ergonomic as it could be, so it's something we're looking to improve. We'd like it so that these object ids can be re-used throughout the floor plan, e.g:
so that if there are identical objects they don't need to be repeated. Where this becomes tricky is if we have objects of footprints larger than one space, e.g.:
Do we have three adjacent but distinct A objects or one contiguous one?
This ergonomics problem, in addition to the stair problem mentioned earlier, means there's still a bit of work needed on this part.
(Spatial) Agents
The building functionality is pretty straightforward. Where things start to teeter (and get more interesting) is with designing the agent framework, which is used to specify the inhabitants of the building and how they behave.
It's hard to anticipate what behaviors one might want to model, so the design of the framework has flexibility as its first priority.
There was the additional challenge of these agents being spatial; my experience with agent-based models has always hand-waved physical constraints out of the problem. Agents would decide on an action and it would be taken for granted that they'd execute it immediately. But when dealing with what is essentially an architectural simulation, we needed to consider that an agent may decide to do something and need to travel to a target before they can act on their decision.
So we needed to design the base Agent class so that when a user implements it, they can easily implement whatever behavior they want to simulate.
Decision making
The first key component is how agents make decisions.
entropy, which represents the constant state changes that occur every frame, regardless of what action an agent takes. For example, every frame agents get a bit more hungry, a bit more tired, a bit more thirst, etc.
successor, which returns the new state resulting from taking a specific action. This is applied only when the agent reaches its target. For example, if my action is eat, I can't actually eat and decrease my hunger state until I get to the food.
actions, which returns possible actions given a state. E.g. if there's no food at the party, then I can't eat
utility, which computes the utility for a new state given an old state. For example, if I'm really hungry now and I eat, the resulting state has lower hunger, which is a good thing, so some positive utility results.
Agents use this utility function to decide what action to take. They can either deterministically choose the action which maximizes their utility, or sample a distribution of actions with probabilities derived from their utilities (i.e. such that the highest-utility action is most likely, but not a sure bet).
This method also takes an optional expected parameter to distinguish the use of this method for deciding on the action and for actually computing the action's resulting utility. In the former (deciding), the agent's expected utility from an action may not actually reflect the true result of the action. If I'm hungry, I may decide to eat a sandwich thinking it will satisfy my hunger. But upon eating it, I might find that it actually wasn't that filling.
execute, which executes an action, returning the modified state and other side effects, e.g. doing something to the environment.
Movement
Agents also can have an associated Avatar which is their representation in the 3D world. You can hook into this to move the agent and know when it's reached it's destination.
Agent movement
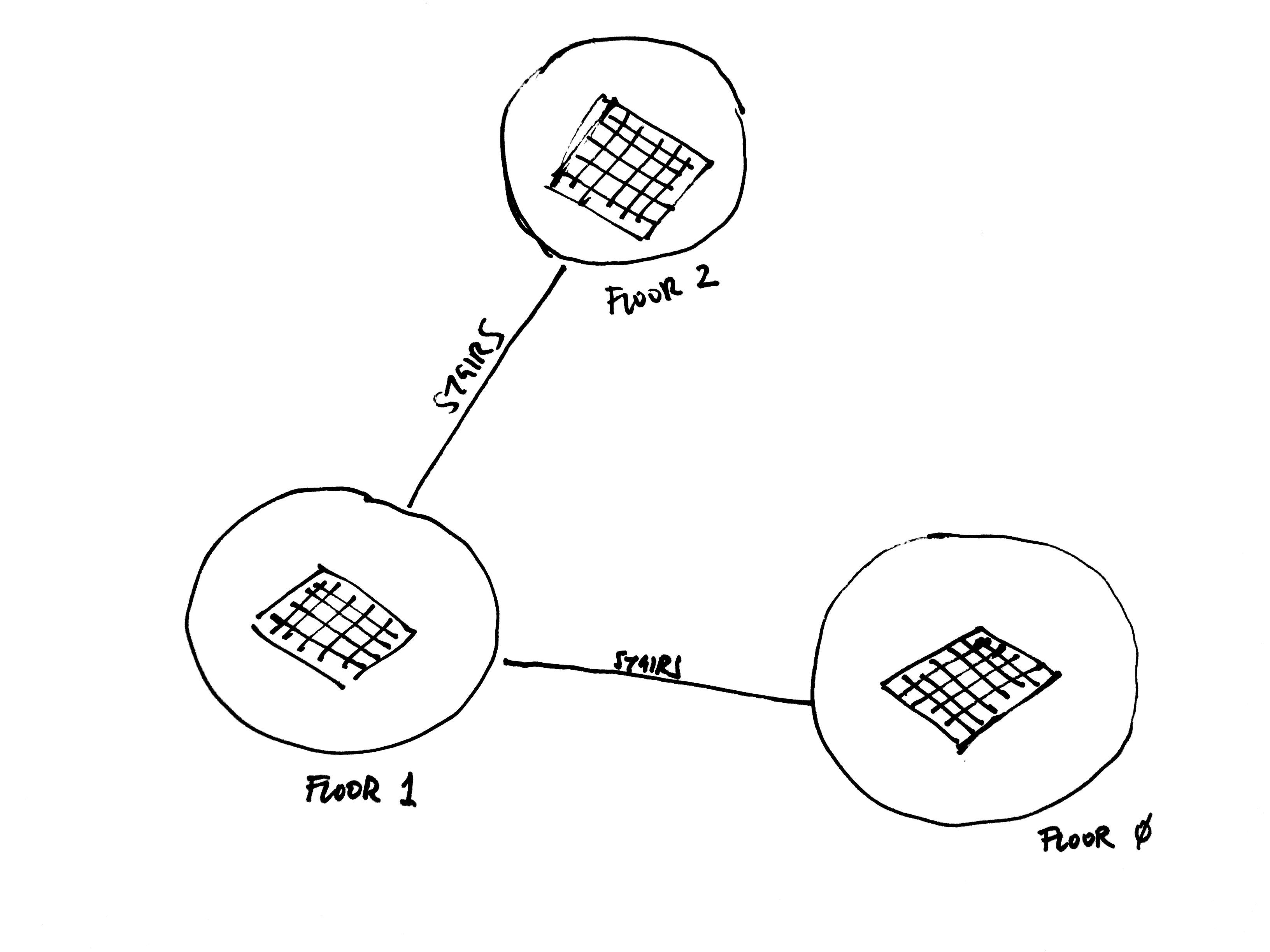
Multi-floor movement was handled by standard A* pathfinding:
Each floor is represented as a grid, and the layout of the building is represented as a network where each node is a floor and edges are staircases. When an agent wants to move to a position that's on another floor, they first generate a route through this building network to figure out which floors they need to go through, trying to minimize overall distance. Then, for each floor, they find the path to the closest stairs and go to the next floor until they reach their target.
Building network example
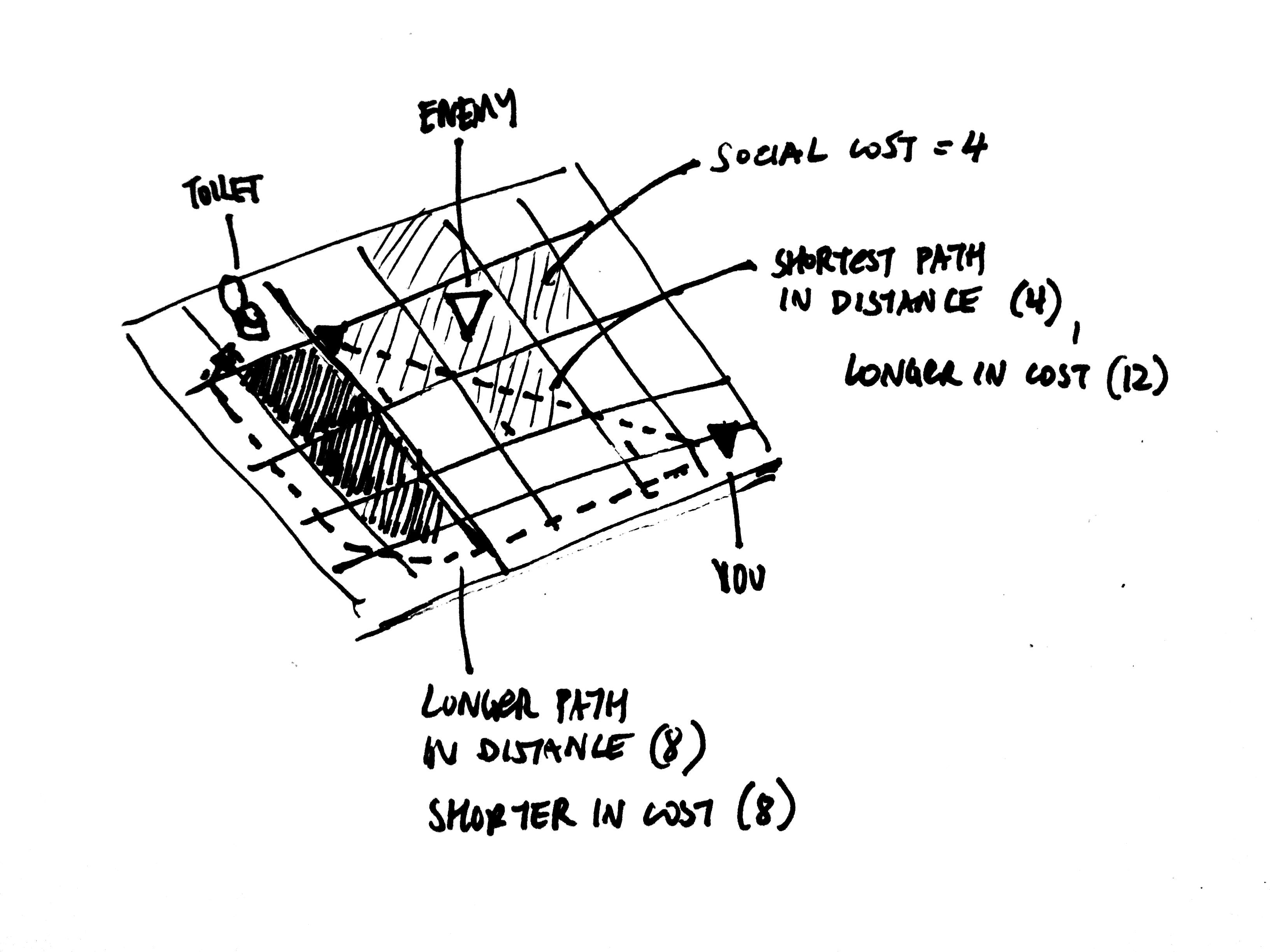
There are some improvements that I'd really like to make to the pathfinding system. Currently each position is weighted the same, but it'd be great if we held different position weights for each individual agent. With this we'd be able to represent, for instance, subjective social costs of spaces. For example, I need to go to the bathroom. Normally I'd take the quickest path there but now there's someone I don't want to talk there. Thus the movement cost of those positions around that person are higher to me than they are to others (assuming everyone else doesn't mind them), so I'd take a path which is longer in terms of physical distance, but less imposing in terms of overall cost when considering this social aspect.
Subjective path weight example
Those are the important bits of the agent part. When we used highrise for Party Fortress (more on that below), this was enough to support all the behaviors we needed.
Party Fortress
Since the original inspiration for highrise was parties we wanted to throw a party to prototype the tool. This culminated in a small gathering, "Party Fortress" (named after Dwarf Fortress), where we ran a simulated party in parallel to the actual party, projected onto a wall.
Behaviors
We wanted to start by simulating a "minimum viable party" (MVP), so the set of actions in Party Fortress are limited, but essential for partying. This includes: going to the bathroom, talking, drinking alcohol, drinking water, and eating.
The key to generating plausible agent behavior is the design of utility functions. Generally you want your utility functions to capture the details of whatever phenomena you're describing (this polynomial designer tool was developed to help us with this).
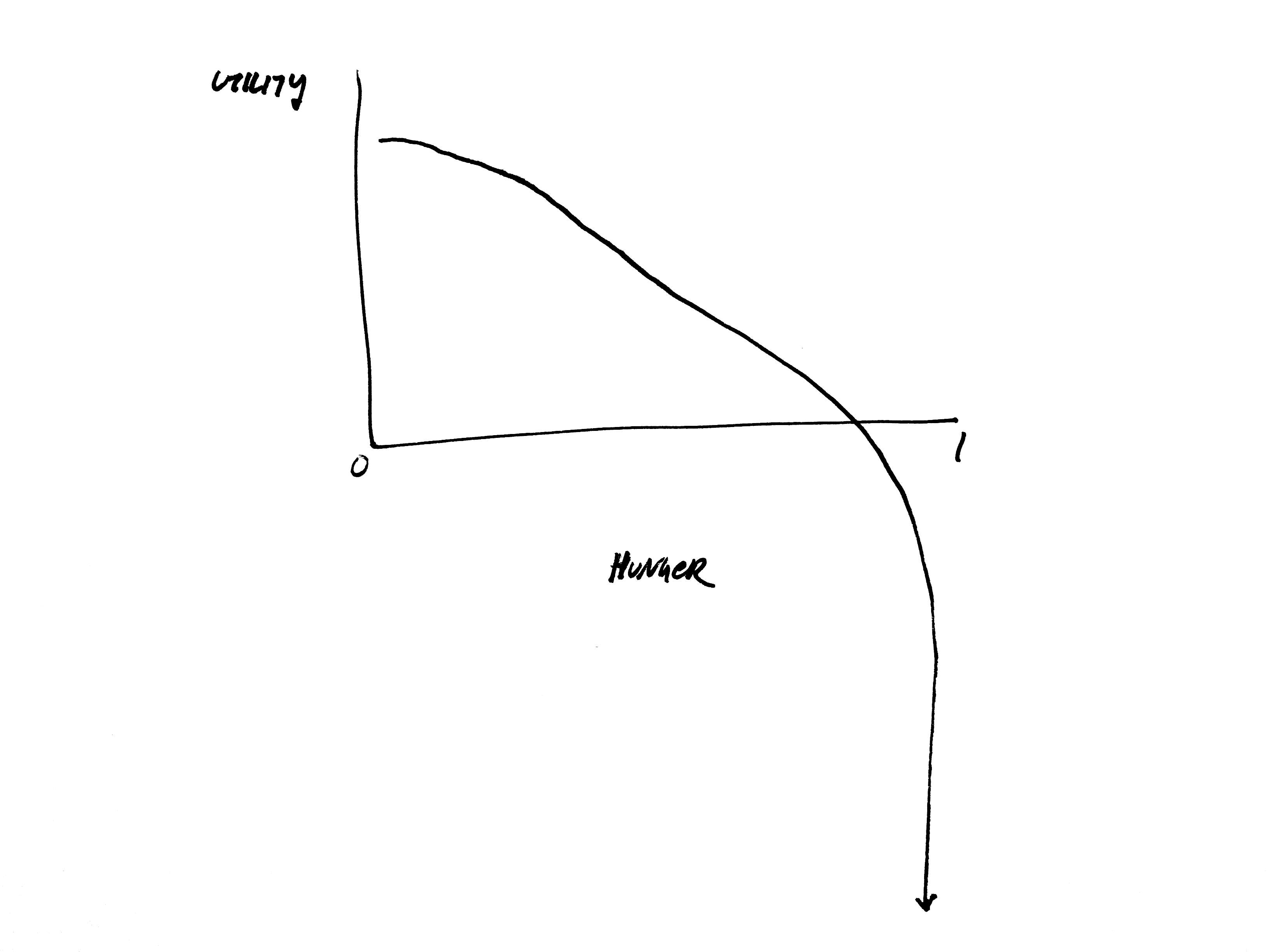
For example, consider hunger: when hunger is 0, utility should be pretty high. As you get hungry, utility starts to decrease. If you get too hungry, you die. So, assuming that our agents don't want to die (every simulation involves assumptions), we'd want our hunger utility function to asymptote to negative infinity as hunger increases. Since agents use this utility to decide what to do, if they are really, really hungry they will prioritize eating above all else since that will have the largest positive impact on their utility.
Hunger utility function
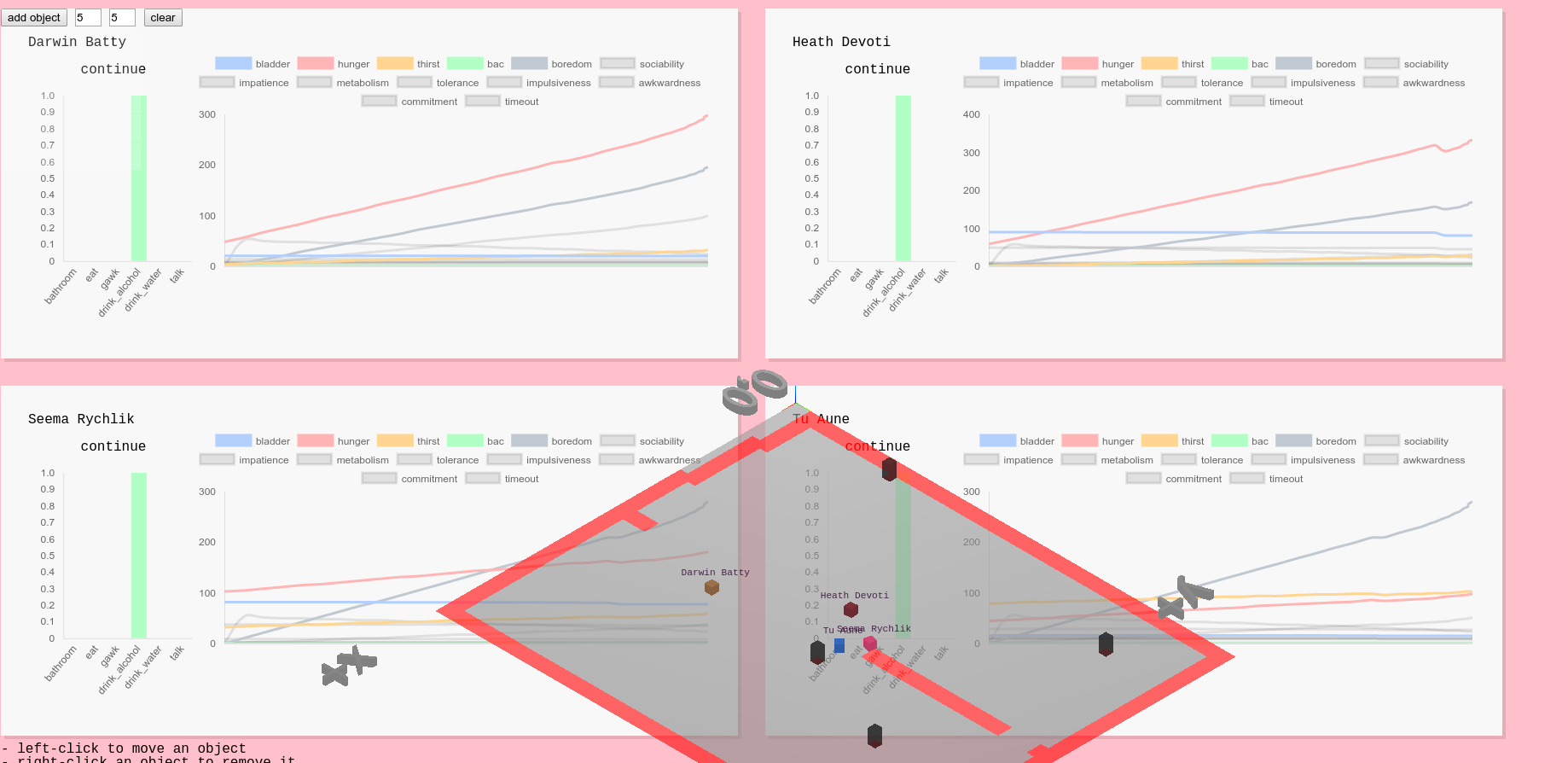
So we spent a lot of time calibrating these functions. The more actions and state variables you add, the more complex this potentially gets, and makes calibration much harder. We're still trying to figure out a way to make this a more streamlined process involving less trial-and-error, but one helpful feature was visualizing agents' states over time:
Agent state charts
Commitment
One challenge with spatial agents is that as they are moving to their destination, they may suddenly decide to do something else. Then, on the way to that new target, they again may decide to something else. So agents can get stuck in this fickleness and never actually accomplish anything.
To work around this we incorporated a commitment variable for each agent. It feels a bit hacky, but basically when an agent decides to do something, they have some resolve to stick with it unless some other action becomes overwhelmingly more important. Technically this works out to mean that whatever action an agent does has its utility artificially inflated (so it's more appealing to continue doing it) until they finally execute it or the commitment wears off. This could also be called stubbornness.
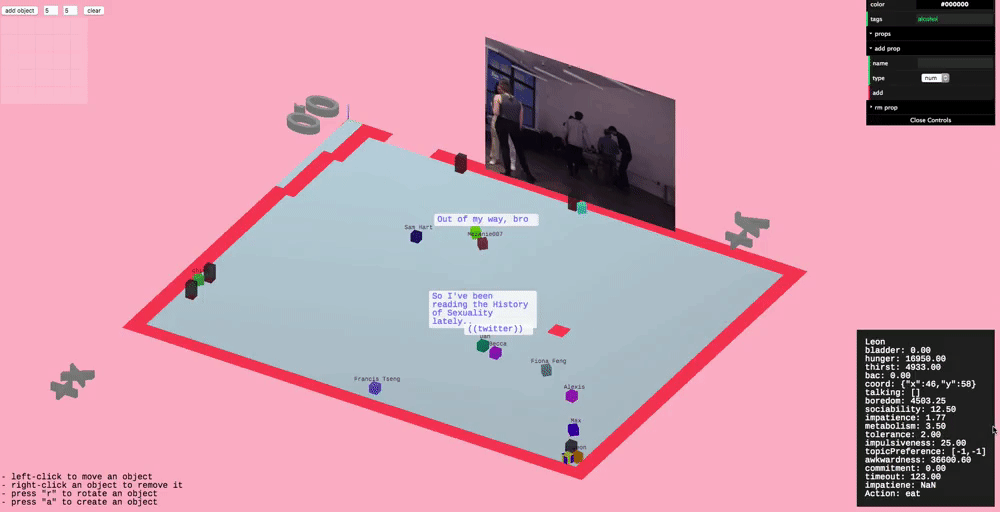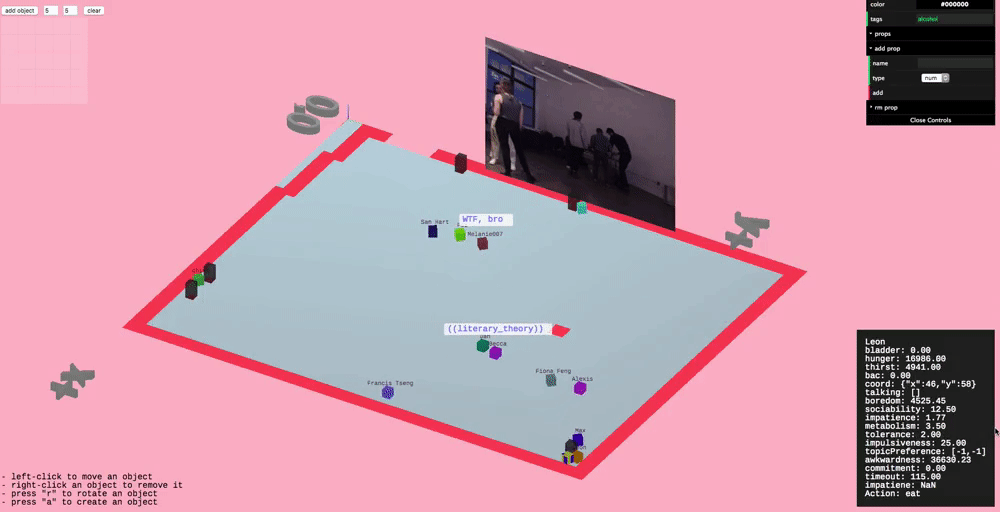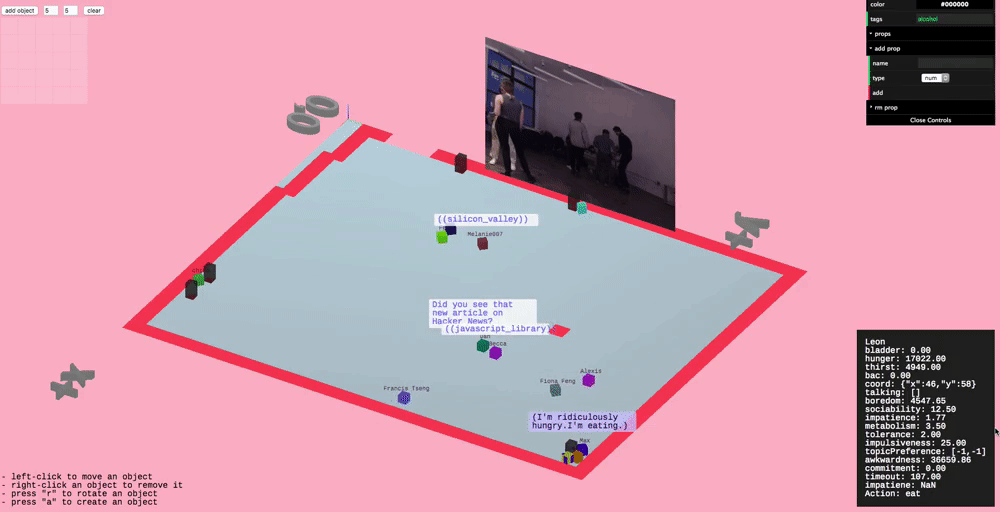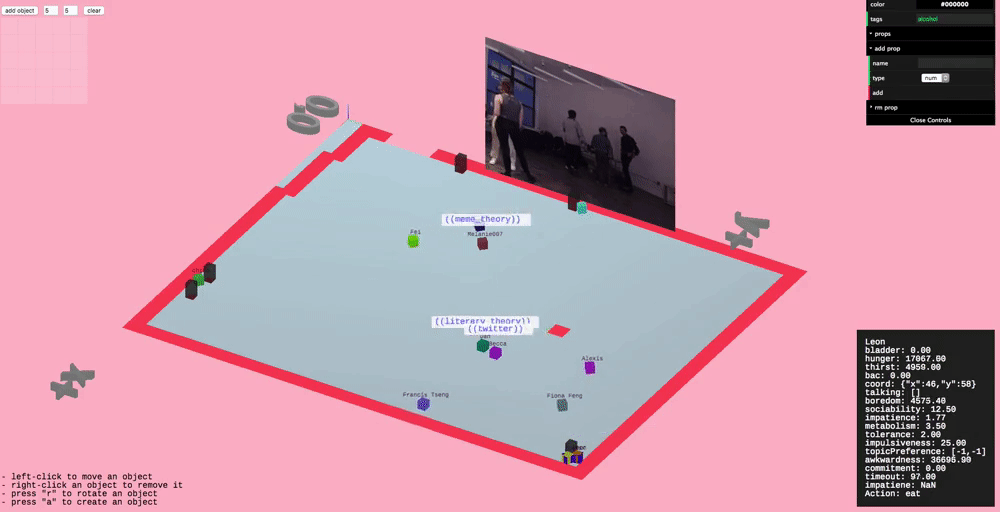
Conversation
Since conversation is such an important part of parties we wanted to model it in higher fidelity than the other actions. This took the form of having varying topics of conversation and bestowing agents with preferences for particular topics.
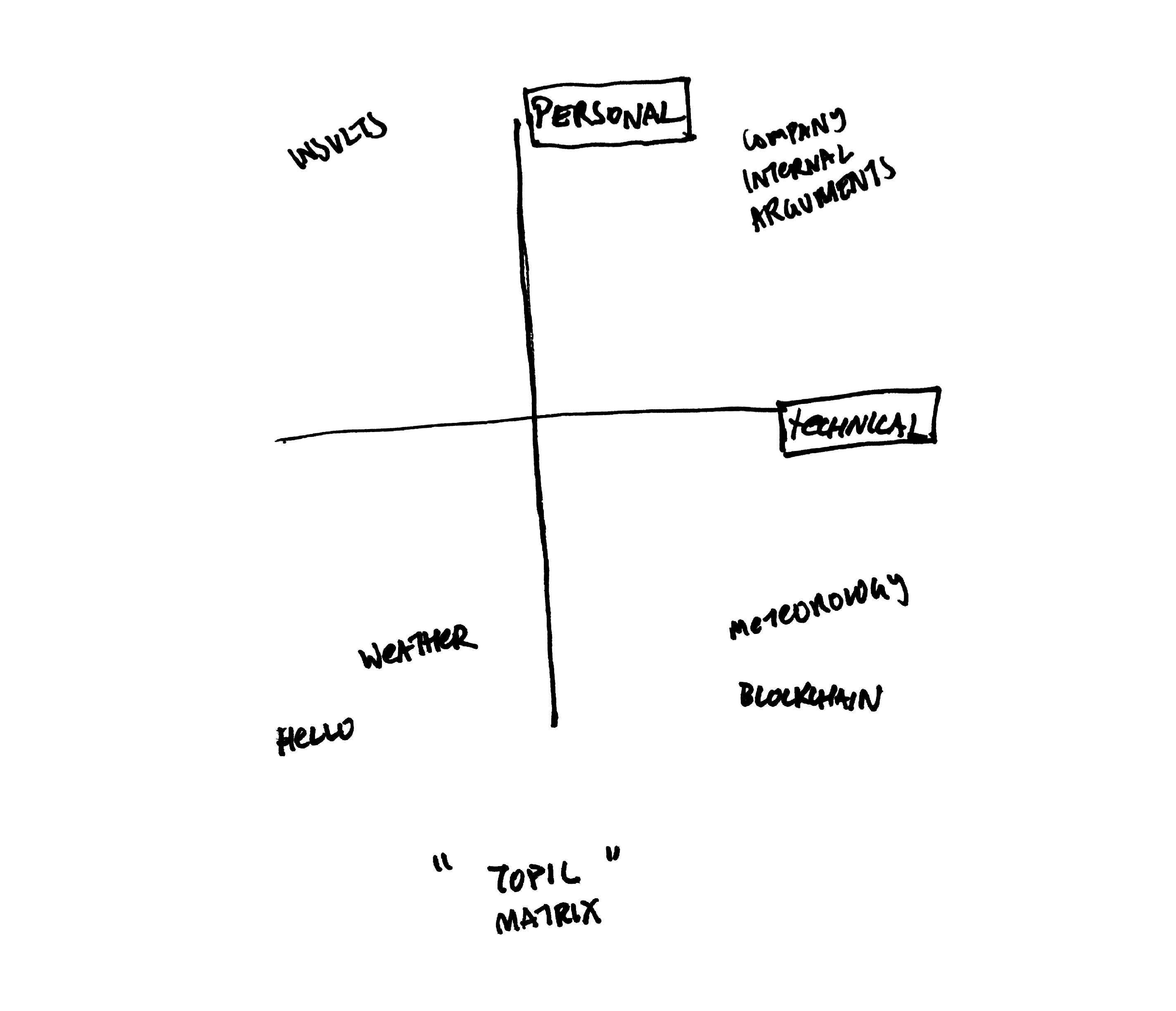
We defined a 2D "topic space" or "topic matrix", where one axis is how "technical" the topic is and the other is how "personal" the topic is. For instance, a low technical, low personal topic might be the weather. A high technical but low personal topic might be the blockchain.
Conversation topic space
Agents don't know what topic to talk about with an agent they don't know, but they a really basic conversation model which allows them to learn (kind of, this needs work). They'll try different things and try to gauge how the other person responds, and try to remember this.
Social Network
As so far specified, our implementation of agents don't capture, explicitly at least, the relationships between individual agents. In the context of a social simulation this is obviously pretty important.
For Party Fortress we implemented a really simple social network so we could represent pre-existing friendships and capture forming ones as well. The social network is modified through conversation and the valence and strength of modification is based on what topics people like. For example, if we talk about a topic we both like, our affinity increases in the social graph.
Narrative
It's not very interesting to watch the simulation with no other indicators of what's happening. These are people we're supposed to be simulating and so we have some curiosity and expectations about their internal states.
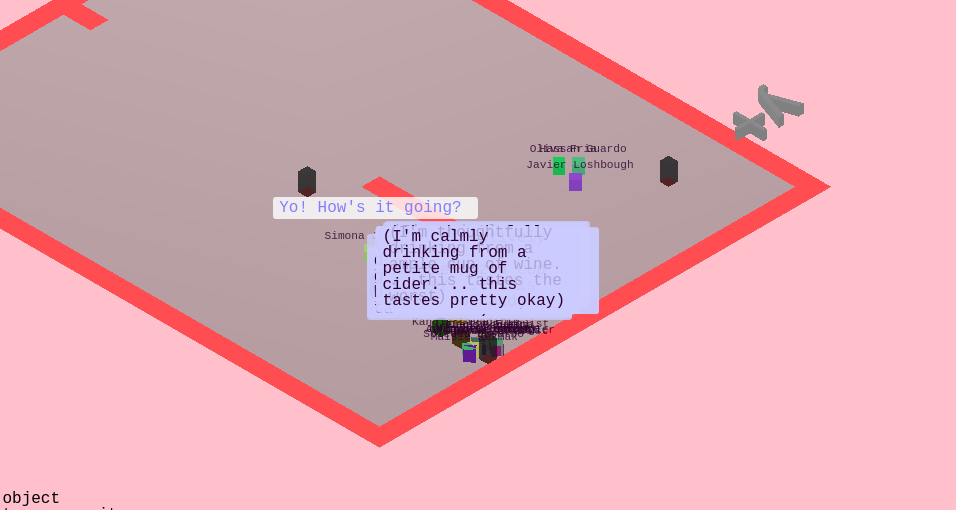
We implemented a narrative system where agents will report what exactly their doing in colorful ways.
Agents talking and thinking
Closing the loop
Our plan for the party was to project the simulation on the wall as the party went on. But that introduces an anomaly where our viewing of the simulation may influence our behavior. We needed the simulation itself to capture this possibility - so we integrated a webcam stream into the simulation and introduced a new action for agents: "gawk". Now they are free to come and watch us, the "real" world, just as we can watch them.
Agents talking and thinking
We have a few other ideas for "closing the loop" that we weren't able to implement in time for Party Fortress I, such as more direct communication with simulants (e.g. via SMS).
We hosted Party Fortress at Prime Produce, a space that Dan has been working on for some time.
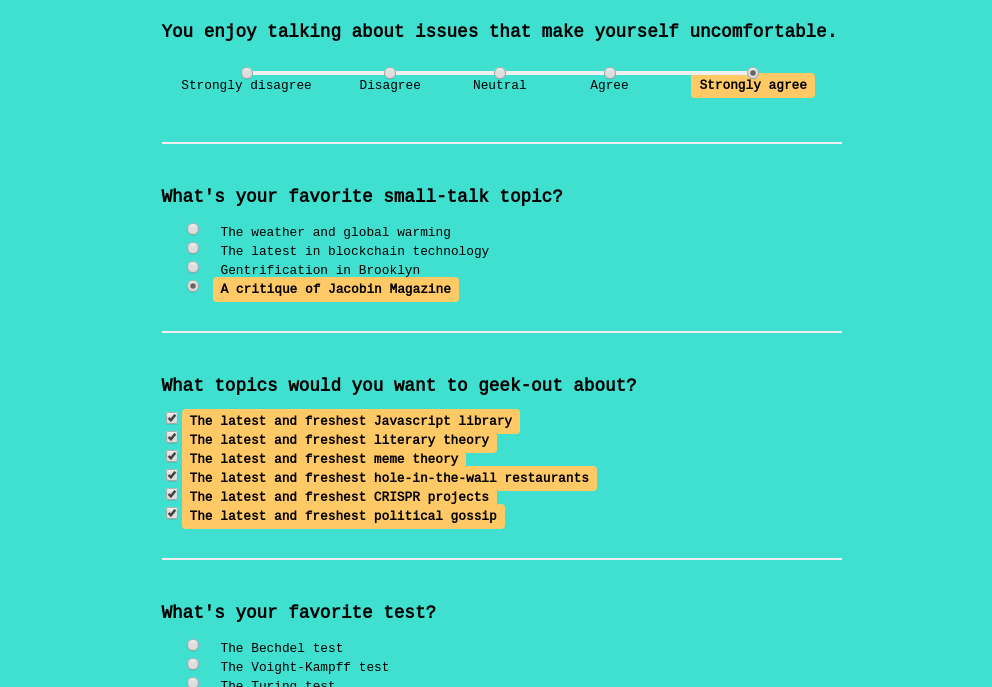
We had guests fill out a questionnaire as they arrived, designed to extract some important personality features. When they submitted questionnaire a version of themselves would appear in the simulation and carry on partying.
Questionnaire
There were surprisingly several moments of synchronization between the "real" party and the simulated one. For instance, people talking or eating when the simulation "predicted" it. Some of the topics that were part of the simulation came up independently in conversation (most notably "blockchain", but that was sort of a given with the crowd at the party). And of course seeing certain topics come up in the simulation spurned those topics coming up outside of it too.
The Party
Afterwards our attendees had a lot of good feedback on the experience. Maybe the most important bit of feedback was that the two parties felt too independent; we need to incorporate more ways for party-goers to feel like they can influence the simulated party and vice versa.
It was a good first step - we're looking to host more of these parties in the future and expand highrise so that it can encompass weirder and more bizarre parties.
The idea of syd is that it will be geared towards social simulation - that is, modeling systems that are driven by humans (or other social beings) interacting. To support social simulations syd will include some off-the-shelf models that can be composed to define agents with human-ish behaviors.
One category of such models are around the propagation and mutation of ideas and behaviors ("social contagion"). Given a population of agents with varying cultural values, how do these values spread or change over time? How do groups of individuals coalesce into coherent cultures?
What follows are some notes on a small selection of these models.
Sorting & peer effects
Two primary mechanisms are sorting, or "homophily", the tendency to associate with similar people, and peer effects, the tendency to become more like people we are around often.
Schelling's model of segregation may be the most well-known example of a sorting model, where residents move if too many of their neighbors aren't like them.
A very simple peer effect model is Granovetter's model. Say there is a population of ¦N¦ individuals and ¦n¦ of them are involved in a riot. Each individual in the population has some threshold ¦T_i¦; if over ¦T_i¦ people are in the riot, they'll join the riot too. Basically this is a bandwagon model in which people will do whatever others are doing when it becomes popular enough.
Granovetter's model does not incorporate the innate appeal of the behavior (or product, idea, etc), just how many people are participating in it. One could imagine though that the riot looks really exciting and people join not because of how many others are already there, but because they are drawn to something else about it.
A simple extension of Granovetter's model, the Standing Ovation model, captures this. The behavior in question has some appeal or quality ¦Q¦. We add some additional noise to ¦Q¦ to get the observed "signal" ¦S = Q + \epsilon¦. This error allows us to capture a bit of the variance in perceived appeal (some people may find it appealing, some people may not, the politics around the riot may be very complex, etc). If ¦S > T_i¦, then person ¦i¦ participates. After assessing the appeal, those who are still not participating then have the Granovetter's model applied (they join if enough others are participating).
There are further extensions to the Standing Ovation model. You could say that an agent's relationships affects their likelihood to join, e.g. if I see 100 strangers rioting I may not care to join, but if 10 of my friends are then I will.
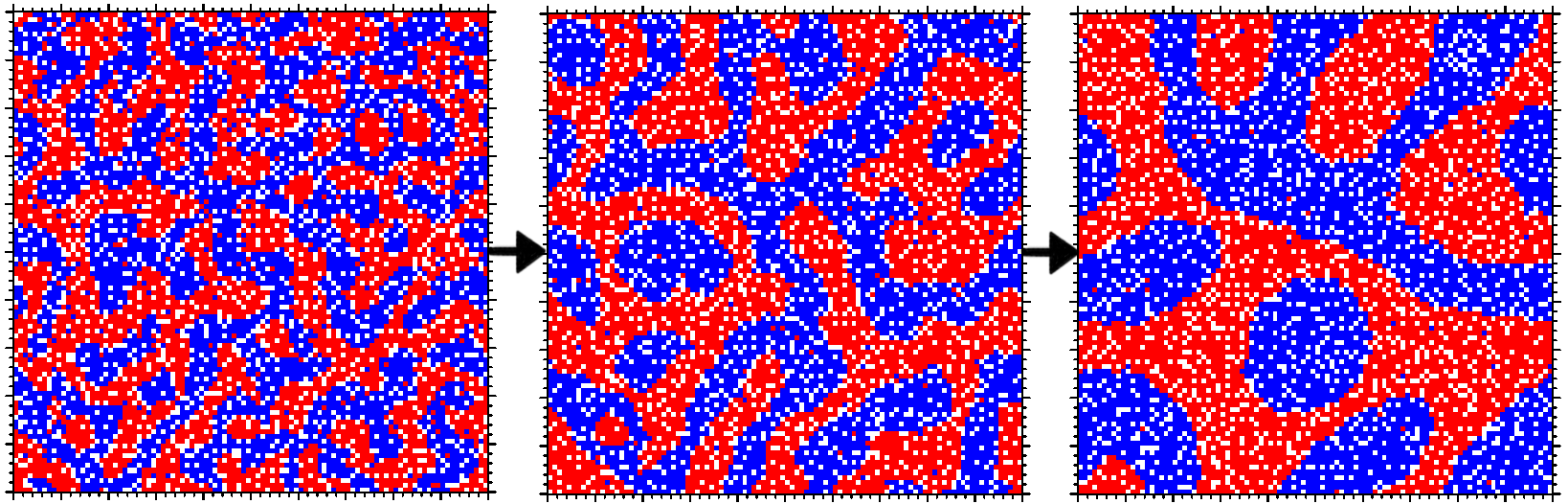
Axelrod's culture model
Axelrod's culture model is a simple model of how a "culture" (a population sharing many traits, beliefs, behaviors, etc) might develop.
each individual is described by a vector of traits
the population is placed in some space (e.g. a grid or a social network)
an individual interacts with a neighbor with some probability based on their trait similarity
if they interact, pick one trait and match with the neighbor's
A social network version of Axelrod's cultural disseminiation model source
This model can be extended with a consistency rule: sometimes the value of one trait is copied over to another trait (in the same individual), this models the two traits becoming consistent. For example, perhaps the changing of one belief causes dependent beliefs to change as well, or requires beliefs it's dependent on to change.
Traits can also randomly change as well due to "error" (imperfect imitation or communication) or "innovation".
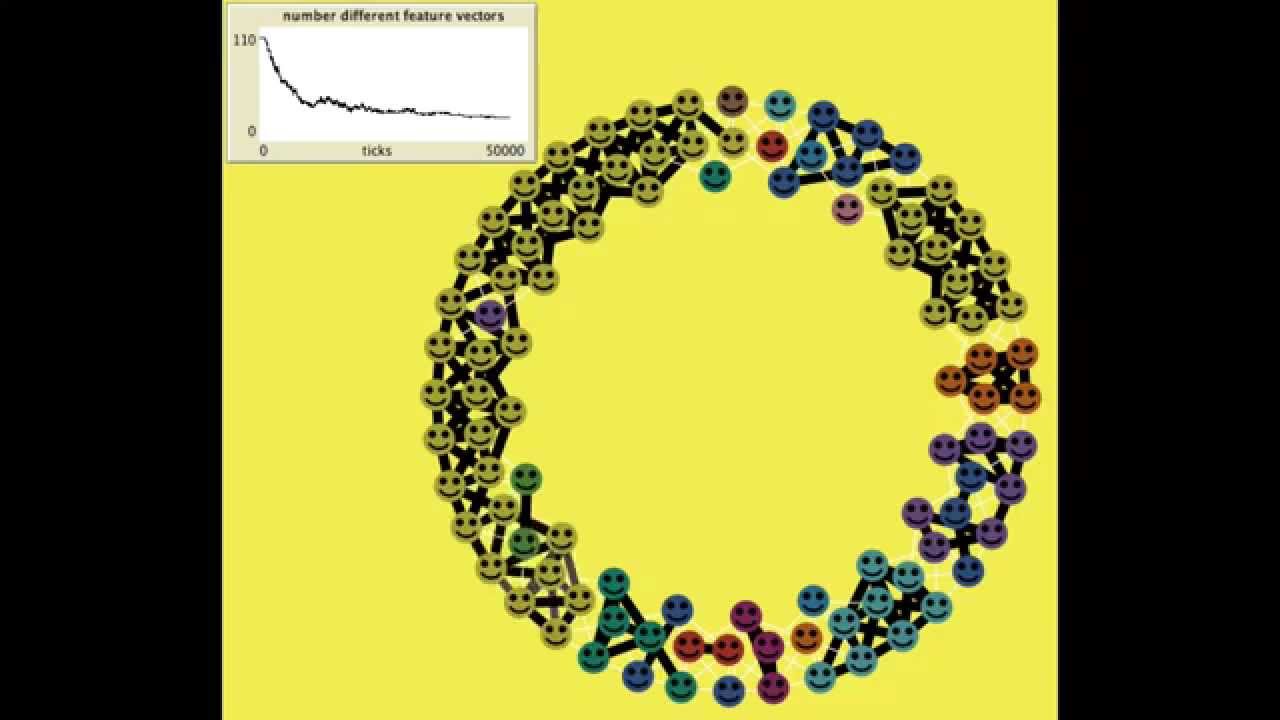
Here agents form a directed graph (e.g. a social network), where edges have two values: frequency of communication and respect one agent holds for the other. For each possible belief, agents have an alignment score which can have an arbitrary scale, e.g. -3 for strong disbelief to 3 for strong belief.
The agent feels a "force" that causes them to change their own alignment. This force is the sum of force from alignment, force from cohesion, and force from separation.
force from alignment is computed by the average alignment across all agents - this is the perceived majority opinion.
force from cohesion: each agent computes the average alignment felt by their neighbors they respect (i.e. respect is positive), weighted by their respect for those neighbors.
force from separation: like the force from cohesion, but computed across their neighbors they disrespect (i.e. respect is negative), weighted by their respect for those neighbors.
This force is normalized and is used to compute a probability that the individual changes their alignment one way or the other. We specify some proportionality constant ¦\alpha¦ which determines how affected an agent is by the force. For force ¦F¦ the probability of change of alignment is just ¦\alpha F¦. It's up to the implementer how much an agent's alignment changes.
Memetics
A meme is an idea/belief/etc that behaves according to the rules of memetics, which models the spread of ideas by applying evolutionary concepts:
phenotypes & alleles
the "offspring" of a meme vary in their "appearance"
a meme contains characteristics ("alleles"), some of which are transmitted to their child
variability in allele combinations is responsible for variability at the phenotypic level
mutation
idea mutation may be random
or it may happen for a reason; ideas can change — to solve problems, for instance (these mutations are essentially innovations advocated by a change agent)
selection
some ideas are more likely to survive than others
an idea's survival is based on how "fit" it is
an idea's measure of fitness is the likelihood of its offspring surviving long enough to produce their own offspring, compared to other memes
Lamarckian properties
unlike biological evolution, members can be modified, activated or deactivated within a generation (people can adapt their ideas to deal with new information, for example)
drift
if multiple finite-sized populations exist, beginning w/ the same set of initial conditions & operate according to the same mechanisms/constraints, completely different sets of ideas can emerge b/w the populations
this drift is due to sampling error when a parent meme produces offspring (random allele heritage)
Memetic transmission may be horizontal (intra-generational) and/or vertical (intergenerational).
The primary mechanism for memetic transmission is imitation, but other mechanisms include social learning and instruction.
Note that the transmission of an idea is heavily dependent on its own characteristics.
For example, there are some ideas that have "mutation-resistant" qualities, e.g. "don't question the Bible" (though that does not preclude them from mutation entirely).
Some ideas also have the attribute of "proselytism"; that is part of the idea is the spreading of the idea.
The Cavalli-Sforza Feldman model is a memetics model describing how a population of beliefs evolve over time.
There is a transmission function:
$$
p = 1 - |1 - g|^{n \mu_t}
$$
where:
¦p¦ is the probability that an individual's belief state will be transformed (i.e. imitate another's) after ¦n¦ contacts
¦g¦ is the probability of transformation after each contact
¦\mu_t¦ is the proportion of people the individual can come into contact with who already have the target belief state
There's also a selection function:
$$
\mu_t' = \frac{\mu_t (1+s)}{1 + s \mu_t}
$$
where:
¦\mu_t'¦ is the proportion of beliefs that survive selection for a single generation
¦\mu_t¦ is the proportion of beliefs before selection
¦s¦ is the degree of fitness
"The popular enforcement of unpopular norms"
The models presented so far make no distinction between public and private beliefs, but it's very clear that people often publicly conform to ideas that they may not really feel strongly about. This phenomenon is called pluralistic ignorance: "situations where a majority of group member privately reject a norm but assume (incorrectly) that most others accept it".
It's one thing to publicly conform to ideas you don't agree with, but people often go a step further and try to enforce others to comply to these ideas. Why is that?
The "illusion of transparency" refers to the tendency where people believe that others can read more about their internal state than they actually can. Maybe something embarrassing happened and you feel as if everyone knows, even if no one possibly could. In the context of pluralistic ignorance, this tendency causes people to feel as though others can see through their insincere alignment with the norm, so they take additional steps to "prove" their conviction.
each agent ¦i¦ has a binary private belief ¦B_i¦ which can be 1 (true believer) or -1 (disbeliever).
true enforcement is when a true believer/disbeliever enforces others to comply/oppose
false enforcement is when a false believer enforces others to comply
An agent ¦i¦ choice to comply with the norm is ¦C_i¦. If ¦C_i=1¦ the agent chooses to complex, otherwise ¦C_i=-1¦. This choice depends on the strength of the agent's convictions ¦0 < S \leq 1¦.
A neighbor ¦j¦'s enforcement of the norm is represented as ¦E_j=1¦; if they enforce deviance instead then ¦E_j=-1¦. Thus we can compute ¦C_i¦ as:
where ¦0 < K < 1¦ is an additional cost of enforcement for those who also comply (it is ¦K¦ more difficult to get someone who does not privately/truly align with the belief to enforce it).
¦W_i¦ is the need for enforcement, which is the proportion of agent ¦i¦'s neighbors whose behavior does not confirm with ¦i¦'s beliefs ¦B_i¦:
Agents can only enforce compliance or deviance if they have complied or deviated, respectively.
The model can be extended by making it so that true disbelievers can be "converted" to true believers (i.e. their private belief changes to conform to the public norm).
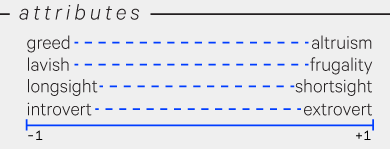
The agents in syd will need to be parameterized in some way that meaningfully affects their behavior. Another way to put this is that the agents need some values that guide their actions. In Humans of Simulated New York Fei and I defined individuals along the axes of greed vs altruism, lavishness vs frugality, long-sightedness vs short-sightedness, and introversion vs extroversion. The exact configuration of these values are what made an agent an individual: a lavish agent would spend more of their money, an extroverted agent would have a larger network of friends (which consequently made finding a job easier), greedy agents would pay their employees less, and so on.
HOSNY value dimensions
The dimensions we used aren't totally comprehensive. There are many aspects of human behavior that they don't encapsulate. Fortunately there is quite a bit of past work to build on - there have been many past attempts to inventory a value spectrums that defines and distinguishs cultures. The paper A Proposal for Clustering the Dimensions of National Culture (Maleki, A., de Jong, M, 2014) neatly catalogues these previous efforts and proposes their own measurements as well.
The authors propose the following cultural dimensions:
individualism vs collectivism
power distance: "the extent to which hierarchical relations and position-related roles are accepted"
uncertainty avoidance: "to what extent people feel uncomfortable with certain, unknown, or unstructured situations"
mastery vs harmony: "competitiveness, achievement, and self-assertion versus consensus, equity, and harmony"
traditionalism vs secularism: "religiosity, self-stability, feelings of pride and, consistency between emotion felt and their expression vs secular orientation and flexibility"
indulgence vs restraint: "the extent to which gratification of desires and feelings is free or restrained"
assertiveness vs tenderness: "being assertive and aggressive versus kind and tender in social relationships"
gender egalitarianism
collaborativeness: "the spirit of 'team-work'"
We can (imprecisely) map the dimensions we used in HOSNY to these:
greed vs altruism -> individualism vs collectivism and collaborativeness
lavishness vs frugality -> indulgence vs restraint
long-sightedness vs short-sightedness -> indulgence vs restraint
introversion vs extroversion -> assertiveness vs tenderness (?)
It doesn't feel very exact though.
All of the previously defined dimensions are worth a look too:
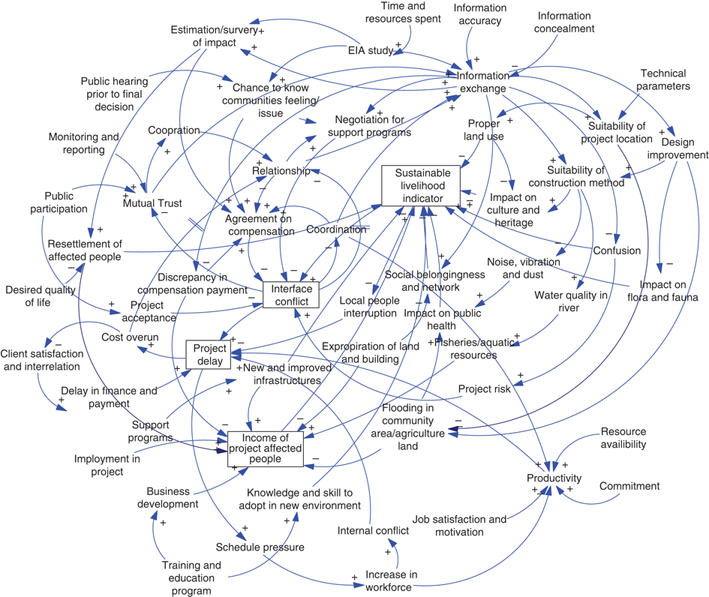
The other day I wrote a bit about the backend architecture of syd; here I'll talk a bit about the tentative design plans. While the backend part of syd is supposed to make writing agent-based simulations easier, you still need to know implement these simulations with code. A typical process for developing such simulations involves design phases, e.g. pen-and-paper sketches or diagramming with flowcharting software where the high-level structure of the system is laid out. Causal loop diagrams are often used in this way.
A causal loop diagram
Ideally the process of designing and sketching this high-level system architecture is the same as implementing the system simulation. This isn't a new idea; it's the approach software like Vensim uses. The point of syd, however, is to appeal to people with little to no systems thinking background; existing systems modeling software is intended for professionals in academia and industry in addition to being closed source and expensive.
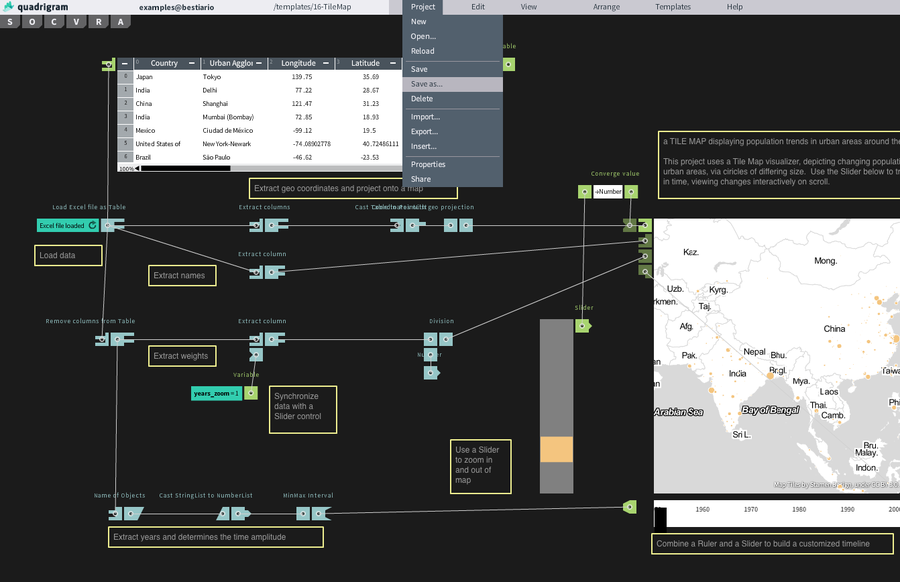
Node-based interface
The general idea is to use a node-based interface. With node-based interfaces you compose causal graphs which are a natural and intuitive representation of systems. As an added bonus, if you design it so that nodes can be composed of other nodes, the interface lends itself to modularity as well.
A node-based interface (quadrigram)
System and agent views
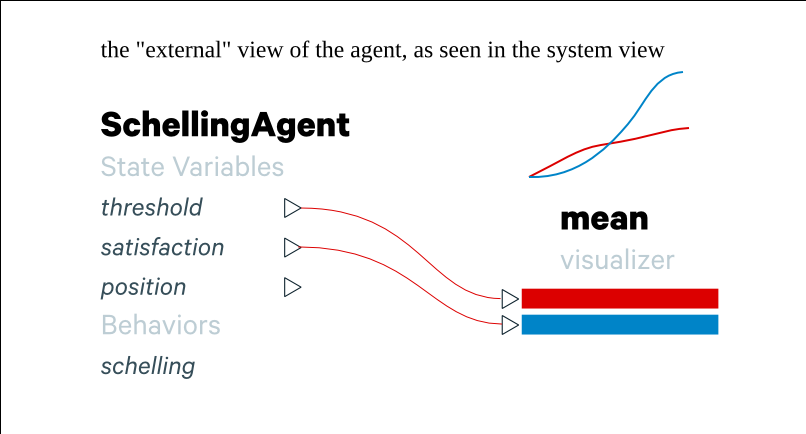
In the syd interface there are two view levels:
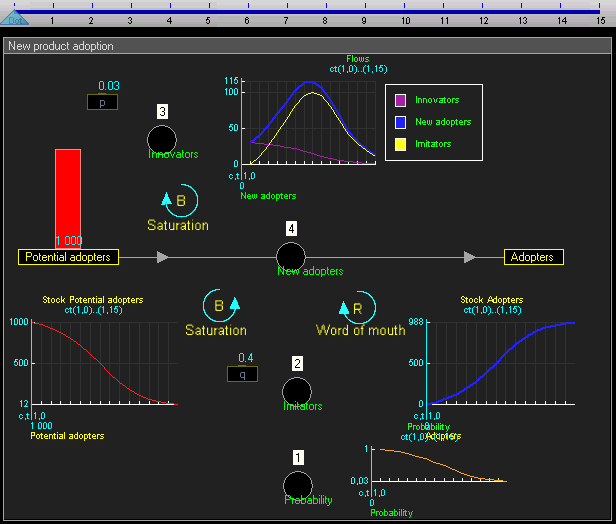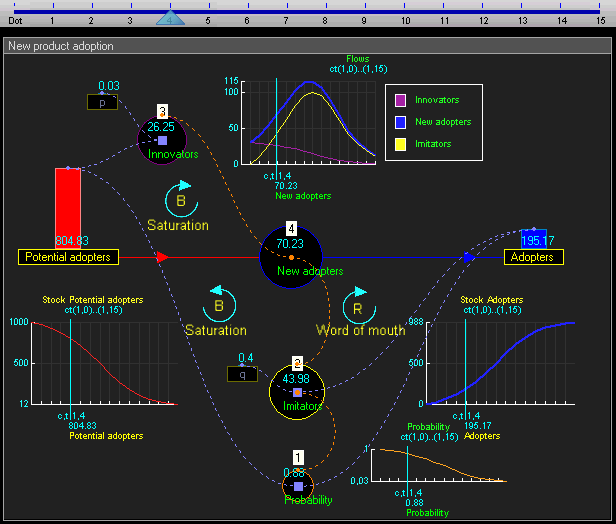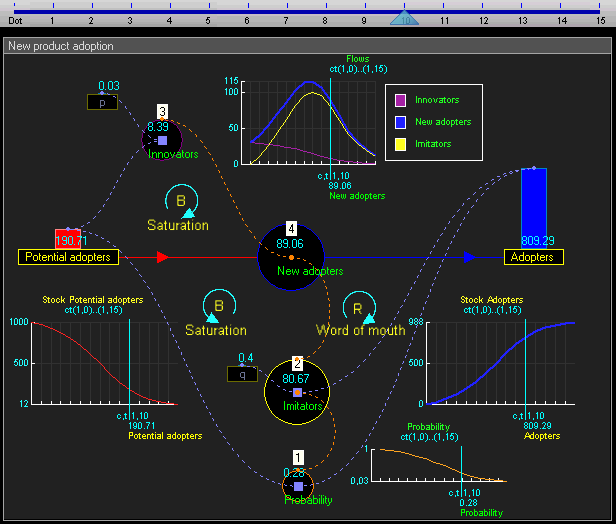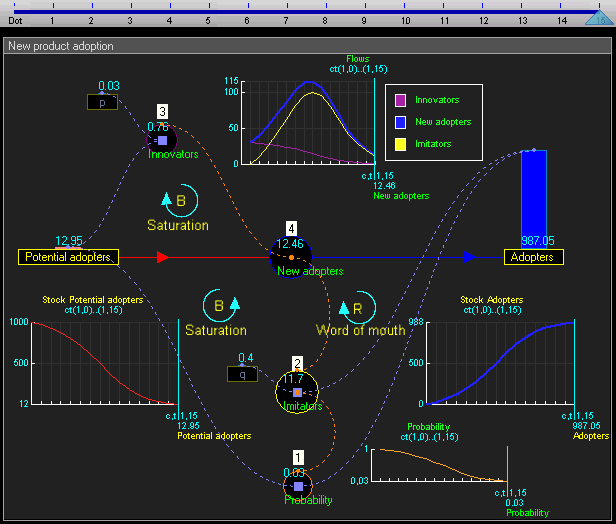
the system level (i.e. the "environment" or the "world"). This works like conventional system dynamics software such as Vensim; i.e. you can define stocks and flows and connect them together.
the agent level. In this view you design the internals of a type of agent (e.g. a person, a firm, etc).
Since the system level view is quite similar to conventional system dynamics software (and also because I haven't fully thought it through yet) I won't go into much detail there. Basically the system level supports the creation of stocks (quantities), flows (changes in quantities that can link between stocks), and outputs (e.g. graphs and other visualizations). This gif of TRUE gives a good sense of it:
TRUE
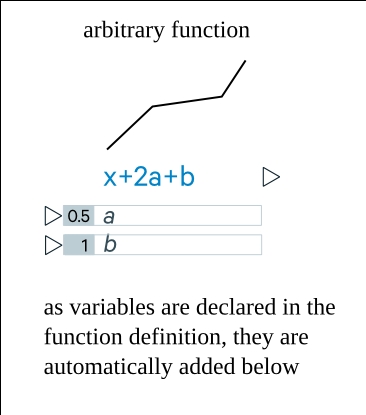
For example, a flow may be some arbitrary function that other outputs and inputs can link to.
Arbitrary function node
You can also take a bunch of flows and stocks and group them into a module node, which "black boxes" the internals so you avoid spaghetti:
Node-based spaghetti
You can also visualize aggregate statistics for agent types as well.
Agent aggregations
The system view is also where you spawn populations of agents.
Designing agents
Agents are defined as types (e.g. a person, or a firm, or a car driver, etc) and are composed of state variables and behaviors.
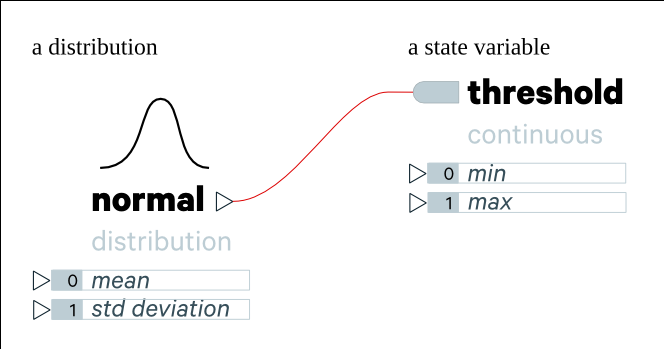
State variables have a name and may be of a particular type (e.g. discrete/categorical or continuous, perhaps collections or references as well). Depending on its type it may have additional parameters that can be set (e.g. if it is a continuous state variable, it may have minimum and maximum values).
State variables may be instantiated with a hardcoded value, which is identical across all agents of that type, or they may be instantiated with some function (e.g. a random distribution or a distribution learned from data), which may cause its value to vary for each individual agent. Note that a limitation here is that at instantiation state variables are treated as independent; i.e. we can't (yet) instantiate them using conditional distributions (conditioned on other state variables, for instance).
State variable instantiations
State variables are changed over the course of the simulation through behaviors. Behaviors are isolated components that are attached to an agent.
A behavior
So far behaviors are black-boxes that read from some state variables and write to other state variables. A warning is raised if a required state variable is not present; perhaps there should be an option to map the expected state variable name to an existing state variable (e.g. if a behavior expects the state variable foo but my agent has bar, I can tell the behavior to use bar instead).
A warning will also be raised if there are multiple behaviors that need to write to the same state variable. So far I haven't thought of a way for the user to easily specify how such write conflicts should be resolved.
Behavior warning
A special kind of behavior is a metabehavior, which, instead of modulating state variable values, adds or removes other behaviors based on conditions. I haven't yet figured out the best way to represent this in the interface.
Final notes
There are a few additional features that would be great to include:
export models as JSON (or some other nice interchange format)
hierarchical simulations; i.e. take another model and include it as a node in another simulation. For instance, maybe you have a simulation about the internal workings of a company (modeling employees and so on) and you want to use that as a sub-simulation in a model of a national economy.
level-of-depth (LOD) and multiscale simulations
These extra features and some other aspects of the interface as described here (especially agent behaviors) require re-architecting of some of the backend, so I don't know when we'll be able to prototype the interface. I'm not totally confident that this approach will be general/flexible enough for more complex simulations, but we'll see when we start to prototype and use it.






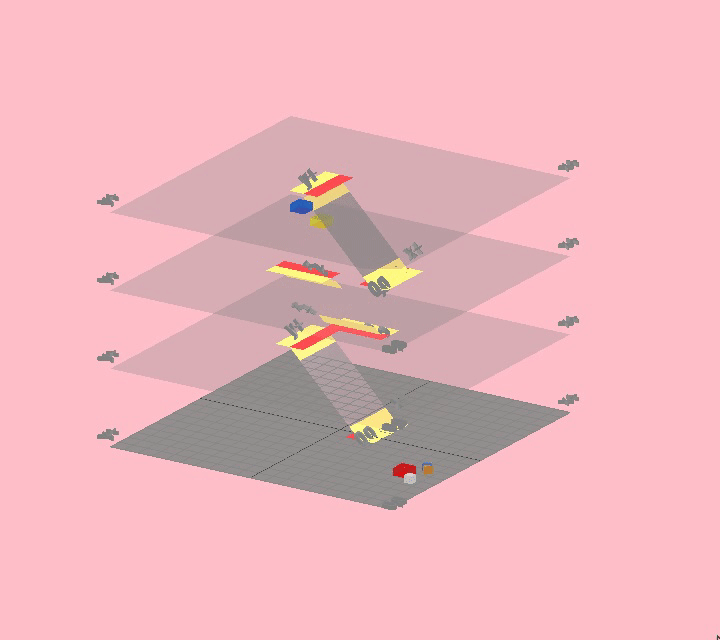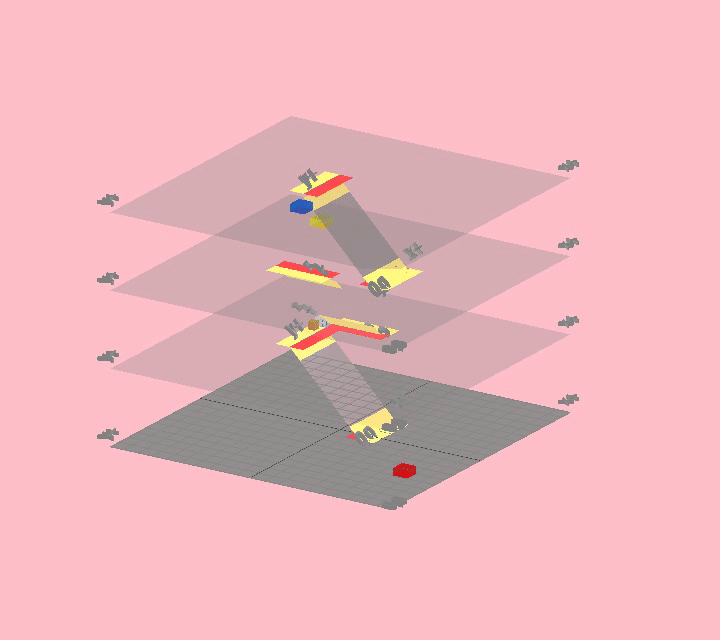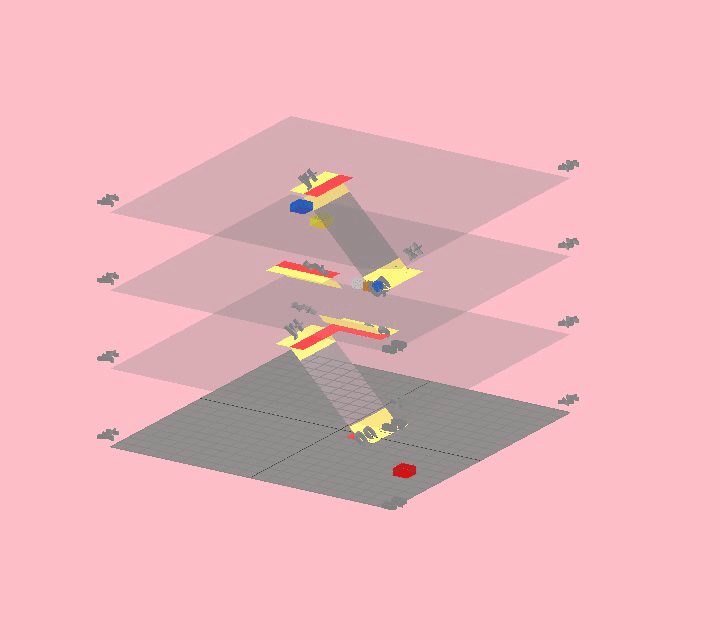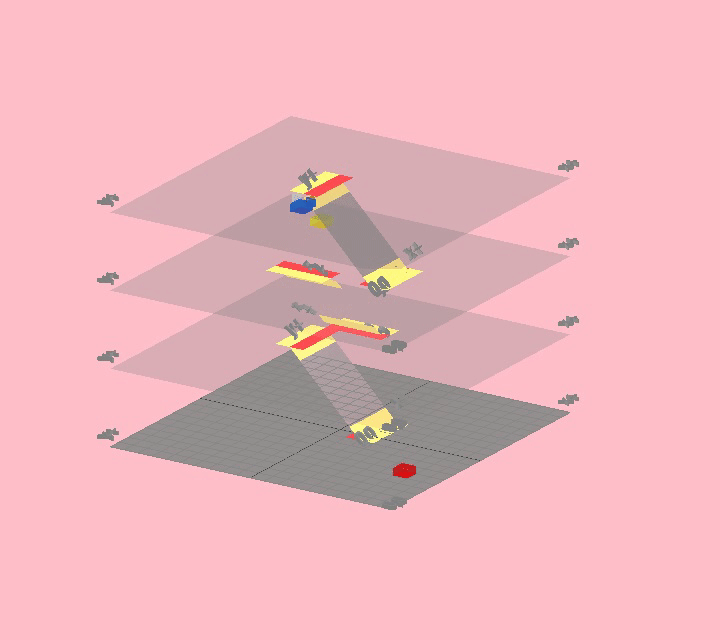












{kind=link}