Computing similarity metrics for short texts can be very difficult. It’s the main challenge in developing Geiger. The problem is that text similarity metrics typically rely on exact overlap of terms (called “surface matching” because you match surface forms1 of words), and short texts are sparse in their terms. There is more opportunity for overlap in longer documents by virtue of the fact that there are simply more words.
Say you have two news articles about employment. If these are longer documents, they may mention words like “work” or “jobs” or “employment”. Similarity metrics reliant on common terms will work fine here.
Now say you have two comments about employment, both of which are fairly short, say ~400 characters each.
Here are two examples:
C2: This attack on another base of employment by democrats is why what began in the last elections will be finished by 2016. I can’t wait to participate.
C1: Nobody thinks the fossil fuel industry opposition to clean air has anything to do with jobs. Establish new companies in these areas, and retrain miners to do those jobs. Or put them to work fixing our roads and bridges, as in FDR’s day. Americans should be outraged that this is even an issue for the courts. What a waste! It’s the air, stupid.
One comment mentions “employment” explicitly; the other only talks about “jobs” and “work”. They are both talking about the same thing, but there is no exact overlap of these key terms, so common-term similarity metrics will fail to recognize that. This is referred to as a problem of synonyms.
The converse of the synonym problem is that of polysemy - where one term can mean different things, in different contexts. The typical example is “bank”, which an mean a financial institution, or the side of a river, or as a verb. Maybe a comment says “good job” and really isn’t saying thing at all about employment, but common-term similarity metrics won’t recognize that.
There’s quite a bit of literature on this problem (see below for a short list) - the popularity of Twitter as a dataset has spurned a lot of interest here. Most of the approaches turn to some external source of knowledge - variously referred to as “world knowledge”, “background knowledge”, “auxiliary data”, “additional semantics”, “external semantics”, and perhaps by other names as well.
This external knowledge is usually another corpus of longer texts related to the short texts. Often this is Wikipedia or some subset of Wikipedia pages, but it could be something more domain-specific as well. You can use this knowledge to relate terms by co-occurrence, e.g. maybe you see that “job”, “work”, and “employment” occur together often in the Wikipedia page for “Employment”, so you know that the terms have some relation.
Alternatively, with Wikipedia (or other corpora with some explicit structure) you could look at the pagelink or redirect graph for this information. Terms that redirect to one another could be considered synonymous, path length on the pagelink graph could be interpreted as a similarity degree between two terms. Wikipedia’s disambiguation pages can help with the polysemy problem, leaning on term co-occurrence in the disambiguated pages (e.g. this comment contains “bank” and “finance”; only one of the Wikipedia pages for “Bank” also has both those terms).
I am still in the process of trying these methods, but they have some intuitive appeal. When we make sense of short documents – or any text for that matter – we always rely on background knowledge orders of magnitude greater than the current text we are looking at it. It’s sensible to try and emulate that when working with machine text processing as well.
Side note: You can also approximately resolve synonyms using word embeddings (vector representations of single terms), such as those derived from a Word2Vec model. I say “approximately” because what word embeddings represent is how similar terms are not in terms of semantics, but by how “swappable” they are. That is, two word embeddings are similar if one can take the place of the other.
For example, consider the sentences “Climate change will be devastating” and “Global warming will be devastating”. The terms aren’t technically synonymous, but are often used as such, so we’ll say that they practically are. A well-trained Word2Vec model will pick up that they often appear in similar contexts, so they will be considered similar.
But also consider “You did a good job” and “You did a bad job”. Here the term “good” and “bad” appear in similar contexts, and so the Word2Vec model would call them similar. But we would not call them synonymous.
Referenced papers:
Yih, W. and Meek, C. Improving Similarity Measures for Short Segments of Text. 2007.
Hu, X., Sun N., Zhang C., Chua, T. Exploiting Internal and External Semantics for the Clustering of Short Texts Using World Knowledge. 2009.
Petersen, H., Poon, J. Enhancing Short Text Clustering with Small External Repositories. 2011.
Hu, X., Zhang X., Lu C., Park, E. Zhou X. Exploiting Wikipedia as External Knowledge for Document Clustering. 2009.
Jin, O., Liu, N., Zhao, K., Yu, Y., Yang Q. Transferring Topical Knowledge from Auxiliary Long Texts for Short Text Clustering. 2011.
Seifzadeh S., Farahat A., Kamel M. Short-Text Clustering using Statistical Semantics. 2015.
1
A surface form of a word is its form in the text. For example, “run”, “ran”, “running” are all surface forms of “run”.
For some time, I’ve been enamored with an idea that Tim Hwang once told me about creating bots for the purpose of testing a social network, rather than for purely malicious or financial reasons. Say you’re developing a new social networking platform and you’ve thought ahead far enough to implement some automated moderation features. How do you know they’ll work as expected?
Imagine you could simulate how users are expected to behave - spawn hundreds to thousands to millions of bots with different personality profiles, modeled from observed behaviours on actual social networks, and let them loose on the network. Off the top of my head, you’d need to model things at the platform/network and agent (user) level.
At the platform level, you’d want to model:
When a new user joins
How users are related on the social graph, in terms of influence. With this, you can model how ideas or behaviours spread through the network.
At the agent (user) level:
When a user leaves the network
When a user sends a message
What that message contains (no need for detail here, perhaps you can represent it as a number in [-1, 1], where -1=toxic and 1=positive)
Who that message is sent to
What affects user engagement
In terms of user profiles, some parameters (which can change over time) might be:
Level of toxicity/aggressiveness
Base verbosity/engagement (how often they send messages)
Base influence (how influential they are in general)
Interest vectors - say there are some ¦n¦ topics in the world and users can have some discrete position on them (e.g. some users feel “1” towards a topic, others feel “2”, still others feel “3”). You could use these interest vectors to model group dynamics.
Finally, you need to develop some metrics to quantify how well your platform does. Perhaps users have some “enjoyment” value which goes down they are harassed, and you can look at the mean enjoyment of the network. Or you could how often users start leaving the network. Another interesting thing to look at would be the structure of the social graph. Are there high levels of interaction between groups with distant interest vectors (that is, are people from different backgrounds and interests co-mingling)? Or are all the groups relatively isolated from one another?
You’d also have to incorporate the idiosyncrasies of each particular network. For instance, is there banning or moderation? You could add these as attributes on individual nodes (i.e. is_moderator=True|False). This can get quite complex if modeling features like subreddits, where moderator abilities exist only in certain contexts. Direct messaging poses a problem as well, since by its nature that data is unavailable to use for modeling behaviour. Reddit also has up and down voting which affect the visibility of contributions, whereas Twitter does not work this way.
Despite these complications, it may be enough to create some prototypical users and provide a simple base model of their interaction. Developers of other networks can tailor these to whatever features are particular to their platform.
With the recently released Reddit dataset, consisting of almost 1.7 billion comments, building prototypical user models may be within reach. You could obtain data from other sites (such as New York Times comments) to build additional prototypical users.
This would likely be a crude approximation at best, but what model isn’t? As it is said, models can be useful nonetheless.
These are just some initial thoughts, but I’d like to give this idea more consideration and see how feasible it is to construct.
The responses were enlightening - we learned a great deal about how people’s concerns varied and which concerns were common. In addition to concerns about trolling and safety, many of the responses were focused on what content was seen and which community members were able to contribute that content. Here are some of our findings:
Moderation came up in almost every group, and many groups had both “no moderation” or too much or unpredictable moderation in their worst communities. Moderation without rationale – e.g. getting banned without being told why – also came up.
Expertise was a concern – the idea that users could inflate their own expertise on an issue and that it’s easy for false information to propagate.
Several groups mentioned dominant personalities, i.e. communities in which the loudest voices have the most traction and quiet, meaningful voices are overpowered.
Contribution quality ranking came up several times, in terms of arbitrary ranking systems (e.g. comments with the most words go to the top) or lack of any quality heuristics at all.
Lack of threading came up several times; it was the most common UI concern across the groups. One group mentioned lack of accessibility as a problem.
Ambiguity came up as a problem in many different ways: lack of explicit and visible community values/guidelines, an unclear sense of purpose or focus, and even concerns about intellectual property – who owns the contributions?
Some groups brought up the collection of arbitrary and excessive personal information as problematic. Similarly, unnecessarily restrictive or permissive terms of services/licenses were also a concern (“perpetual license to do anything [with your data]”), as was the unnecessary display of personal information to others.
Complete anonymity (e.g. no user accounts or history) was mentioned a few times as something to be avoided. Only one group mentioned forced IRL identities (using your SSN as a username).
No control over your own contributions came up a couple times - not being able to edit, delete, or export your own submissions.
The worst communities would be powered by slow software, the groups said — all the better to ratchet up feelings of frustration.
A few communities are notorious as examples of a “bad community” - Reddit, YouTube, and LinkedIn cropped up a few times.
from , by Bill Watterson
After the dust settled, attendees then designed their ideal online community. As you might expect, some of the points here were just the opposite of what came up in the worst community exercise. But interestingly, several new concerns arose. Here are some of the results:
Clarity of purpose and of values – some explicitly mentioned a “code of conduct”.
Accessibility across devices, internet connections, and abilities.
There was focus on ease of onboarding. One group pointed to this GitHub guide as an example, which provides a non-technical and accessible introduction to a technical product.
A couple of groups mentioned providing good tools that users could utilize for self-moderation and conflict resolution.
Transparency, in terms of public votes and moderation logs.
Increasing responsibility/functionality as a user demonstrates quality contributions.
Still a sense of small-community intimacy at scale.
A space where respectful disagreement and discussion is possible.
Options to block/mute people, and share these block lists.
Graduated penalties – time blocks, then bans, and so on.
Some kind of thematic unity.
Some findings from our other research were echoed here, which is validating for how we might focus our efforts.
It was interesting to see that there was a lot of consensus around what constituted a bad online community, but a wider range of opinions around what a good community could look like. We definitely have no shortage of starting places and many possible directions. We’re looking forward to building some of these ideas out in the next few months!
I’ve had a lot of trouble finding a blogging platform which I enjoyed using - they were either too heavy or required using a web editor or were tricky to customize and theme. So last week I put together a super lightweight blogging platform called port.
port is the centralized complement to nomadic, which is a lightweight note management system. Like nomadic, port uses directory structure to define its routing structure and works primarily off markdown documents.
Here’s what port offers:
Posts are GitHub-flavored markdown files, with MathJax support
A blog is represented as a directory, with subdirectories of markdown posts
Post categories are defined by the folders they are in
RSS feeds for individual categories and for all posts
Very easy theming (Jinja2 templates)
Managed via a CLI (the port command)
No database necessary!
No admin UI necessary!
There are a couple additional convenience features as well:
port sync makes it easy to sync your local site files to a remote machine (e.g. your server)
port host generates the config files necessary to host your blog with uwsgi, supervisor, and nginx
port serve serves the site locally, which is useful for previewing your work
Tutorial
Here’s how to get going with port. For this example I’ll specify my site’s directory as ~/spaceandtimes.
Install
pip install port
Create a site (I’ll use my site as an example) and go through the config
port create spaceandtimes
Setup a category (just renaming the default category port creates)
Create the site on the server (again, say we put the site at ~/spaceandtimes):
port create spaceandtimes
Then run the host command to automatically generate the necessary configs and restart the nginx and supervisor processes (the last argument is the user that the site was generated under):
port host spaceandtimes blog.spaceandtimes.com ftseng
From your local machine, sync your site (but first, build your site locally):
port sync spaceandtimes user@my_server.com:~/spaceandtimes
Workflow
My workflow with port is to write posts locally, build locally, and then sync to my server. It’s super fast and easy :)
So basically:
vi ~/spaceandtimes/etc/my_new_post.md
port build spaceandtimes
port sync spaceandtimes ftseng@myserver.com:~/spaceandtimes
And that’s it!
See the GitHub repo for more info on theming and other details.
This week I returned to tackling the news clustering problem I had been exploring last year.
The general goal is to take in groups of news articles, and cluster them so that news articles talking about the same event are grouped together.
Before, I used a clustering technique that was an incremental form of hierarchical agglomerative clustering (IHAC, implementation available here) which seemed better suited for the task compared to more popular approaches like k-means and DBSCAN. However, that technique had its own problems.
The problem
The clustering quality still was not where I needed it to be - in particular, many of the resulting article clusters (which I call “events”) included articles which were unrelated to the others.
This is a problem of cluster homogeneity, which asks: how many members are in clusters with members from other true clusters? The complement of this is completeness, which asks: how many members that belong together (in the true clustering) were clustered together? Lower completeness is tolerable - people are less likely to notice the absence of an article that belongs than the presence of an article that doesn’t (which is what homogeneity measures).
As a simple illustration, imagine the true clusters:
[A_1, A_2, A_3], [B_1, B_2, B_3]
The following clustering has a homogeneity score of 1 (the best score) and a completeness score of ¦\approx 0.685¦.
[A_1, A_2], [A_3], [B_1, B_2, B_3]
The following clustering has a completeness score of 1 (the best score) and a homogeneity score of ¦\approx 0¦.
[A_1, A_2, A_3, B_1, B_2, B_3]
For my task, the former is preferable to the latter.
Note that the following clustering has a homogeneity score of 1, but a completeness score of ¦\approx 0.387¦.
[A_1], [A_2], [A_3], [B_1], [B_2], [B_3]
We don’t want to achieve good homogeneity at the total expense of completeness, as is the case here!
Parameter selection
The severity of this problem was mostly affected by where I decided to snip the cluster hierarchy that IHAC produced. The problem is that this value is difficult to determine in advance as it may vary for different sets of articles.
This dilemma - known as parameter selection - is one that crops up a lot in clustering. For k-means, it’s the question of the value for ¦k¦; for DBSCAN, it’s the value of ¦\epsilon¦ under concern.
For IHAC my selection heuristic was based on the average density of branch nodes, but that was not working well.
In the case of k-means and DBSCAN, this problem of parameter selection is an area of active research, so there are a few promising techniques to start with.
DBSCAN parameter selection
For DBSCAN, one technique (outlined here) involves looking at the nearest neighbor for each point and identifying some majority value for ¦\epsilon¦ based on that.
The technique I’m using is similar - it involves taking the ¦n¦ nearest neighbors for each point, looking at the distances between them, and identifying the largest “jump” in distance. The average of the distances that precede those jumps in difference is used as ¦\epsilon¦.
(Though I also wonder if ¦\epsilon¦ is a parameter that could be learned; that is, if news events tend to have a similar article density.)
k-means parameter selection
For k-means, one effective approach is outlined here, called “¦f(K)¦”, which runs k-means iteratively with different values of ¦k¦ and computes scores for them (see the article for details).
You do need to specify an upper limit for ¦k¦, which in theory could just be ¦n¦ (the number of documents), but practically speaking, this can be very slow and it’s unlikely that every document will belong to its own cluster. I’ve been using ¦n//3 + 1¦ under the assumption that the events have at least 3 news articles each.
For k-means, getting ¦k¦ right is especially important. DBSCAN has a concept of outliers so points which don’t seem to belong to clusters will be treated as noise. But for k-means, every point must be assigned to a cluster, which can be problematic.
Evaluating these approaches
To evaluate these approaches, I needed some ground truth events. Fortunately, there is a resource for this: Wikinews.
On Wikinews, contributors write entries about news events and supply a list of sources for each. XML dumps of these pages are available - so I put together a program called focusgroup which parses these dumps, applies a few heuristics to weed out noise events - those in other languages, with too few sources, with sources which are no longer available, with unreliable sources, etc. - and then downloads and extracts the source pages’ main content into a database.
Evaluation datasets of 10, 20, and 30 randomly selected clusters/events were built from this data.
What follows are the scores for k-means with automated parameter selection, DBSCAN with automated parameter selection, and my hs_cluster approach (which I’ll explain below) on the 10, 20, and 30 event datasets (which I’ll call 10E, 20E, and 30E, respectively).
For k-means and DBSCAN, documents are represented using TF-IDF weighted vectors (see the vectorizer source for details).
(Note that k-means is not included for the 30 event dataset because automated parameter selection seemed to run indefinitely.)
Approach
# Clusters
Completeness
Homogeneity
Time
10E
kmeans_cluster
7
0.9335443486
0.7530130785
6.65s
dbscan_cluster
6
1.0
0.7485938828
0.34s
hs_cluster
12
0.9287775491
0.9527683893
2.79s
20E
kmeans_cluster
16
0.9684967878
0.8743004102
12.08s
dbscan_cluster
16
0.9580321015
0.8637897487
0.52s
hs_cluster
35
0.8677638864
0.9888333740
4.42s
30E
kmeans_cluster
n/a
n/a
n/a
n/a
dbscan_cluster
7
0.9306925670
0.2568053596
7.13s
hs_cluster
60
0.8510288789
0.9539905161
11.27s
None of the approaches reliably get close to the number of true clusters. But what’s important is that the hs_cluster approach scores much better on homogeneity (at the expense of completeness, but again, that’s ok).
The hs_cluster approach
These automatic approaches are okay at finding decent values for these parameters, since these scores are not terrible - but they are clearly still weak on the homogeneity front.
An approach that doesn’t require specification of a parameter like ¦k¦ or ¦\epsilon¦ would be ideal.
I’ve developed an approach which I call hs_cluster (the reason for the name is left as an exercise for the reader) which has been effective so far. Like all approaches it needs some concept of document similarity (or distance, as is the case with k-means and DBSCAN)
Document similarity
First, the pairwise similarity between all documents is computed.
Here I’m trying to take advantage of some features of the news - in particular, the assumption that articles that belong to the same event will typically talk about the same named entities.
The simplest similarity computation for a pair of documents is just the size of entity intersection (I’ll go into some improvements on this further on).
Detecting outliers
Given these pairwise similarities, how do we know when two documents are significantly similar? This could be framed as a new parameter - i.e. some threshold entity intersection, above which we can say two documents are sufficiently alike.
However, this just introduces a new parameter selection problem, when the whole point of this new approach is to avoid doing exactly that!
Instead, statistical outliers seem promising. For a each document, we identify which of its similarities with other documents is an upper outlier, and consider those significant.
There are a few techniques for detecting outliers.
Perhaps the simplest involves using quartiles of the data: look at values above ¦Q_3 + 2(Q_3 - Q_1)¦. The main problem with this technique is that it’s sensitive to the sample size, e.g. if you are looking at a handful of documents, you’re unlikely to get reliable results.
Another technique is similar to the ¦\epsilon¦ selection for DBSCAN, where abnormally large jumps between values are identified, and outliers are considered values above that jump.
A third technique is based on median-absolute-deviation (MAD), outlined here. This technique has the benefit of not being sensitive to sample size.
In practice, the simple quartile approach has worked best. I haven’t looked at document sets of less than 10 in size, so perhaps below that it falls apart.
Creating the graph
These documents and their outlier similarities were then used to construct a graph where these outlier similarities define edges and their weights between documents.
Identifying and disambiguating cliques
Once the graph is formed, it’s just a matter of running a clique finding algorithm (the networkx library includes one) on it.
There is one last issue - an article may belong to multiple cliques, so we need to disambiguate them. The method is simple: stay in the clique for which membership is the strongest (as quantified by the sum of edge weights) and leave all the others.
Initial results
The initial results of this approach were promising:
Completeness
Homogeneity
10E
0.9287775491
0.9527683893
20E
0.8347274166
0.9724715221
30E
0.8491559191
0.9624775352
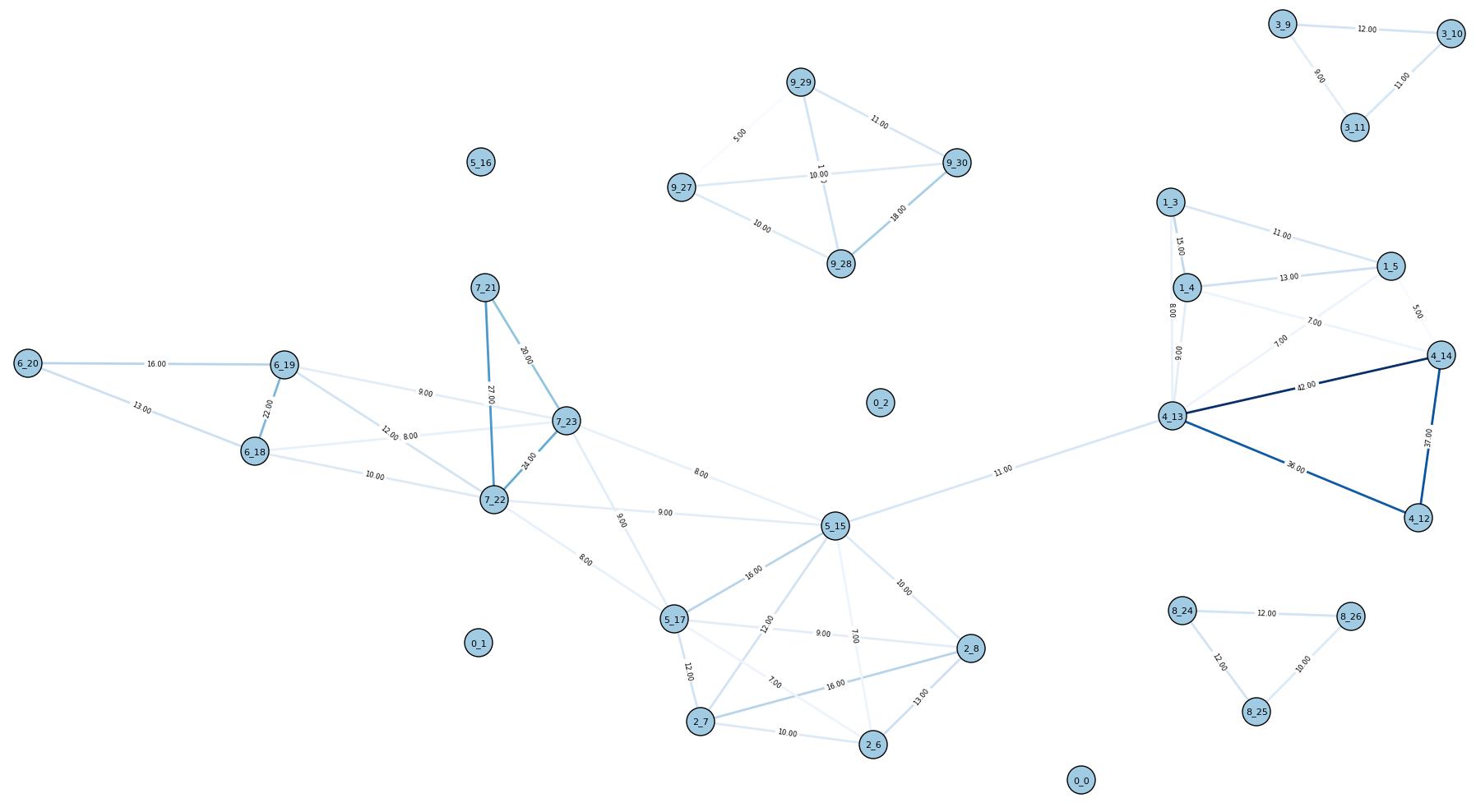
And here is the graph for the 10E dataset (all graphs are shown before clique disambiguation):
10E
(Node labels are in the format of {cluster id}_{article id}.)
It looks pretty good - some of the true clusters are isolated cliques. But there are still many connections between unrelated articles, so it seems that there’s room for improvement.
Weighting intersections
“Global” IDF
Up until now we were only looking at intersection of entities, so all entities are treated equally. However, there are some fairly uninformative entities, like “US” or “Congress” which we expect to see naturally occur in many articles. We want to down-weight these entities since their appearance across two documents is unremarkable. Conversely, we want to up-weight entities which rarely occur, since their presence in an intersection is unlikely and therefore more meaningful.
Normally the approach here would be to incorporate IDF (inverse document frequency) weighting; typically this IDF is calculated from the input documents. However, the corpora I’m working with now (and expect to use in the future) are fairly small, perhaps 30-100 documents at a time, which limits the possibility of any meaningful IDF being generated. Instead I’ve opted for an IDF model built on an external source of knowledge - about 113,200 New York Times articles. That way we have some “global” understanding of a term’s importance in the context of news articles.
So now instead of merely looking at the size of the intersection, it uses the sum of the IDF weights of the intersection’s members.
Inverse length weighting
The possible intersection between two documents is affected by the length of the documents, so the IDF-weighted overlaps are then further weighted by the inverse of the average length of the two documents being compared.
Results of weighting
Incorporating these weights seem to help for the most part:
Completeness
Homogeneity
10E
0.9557853457
1.0
20E
0.8375545102
0.9793536415
30E
0.8548535867
0.9689355683
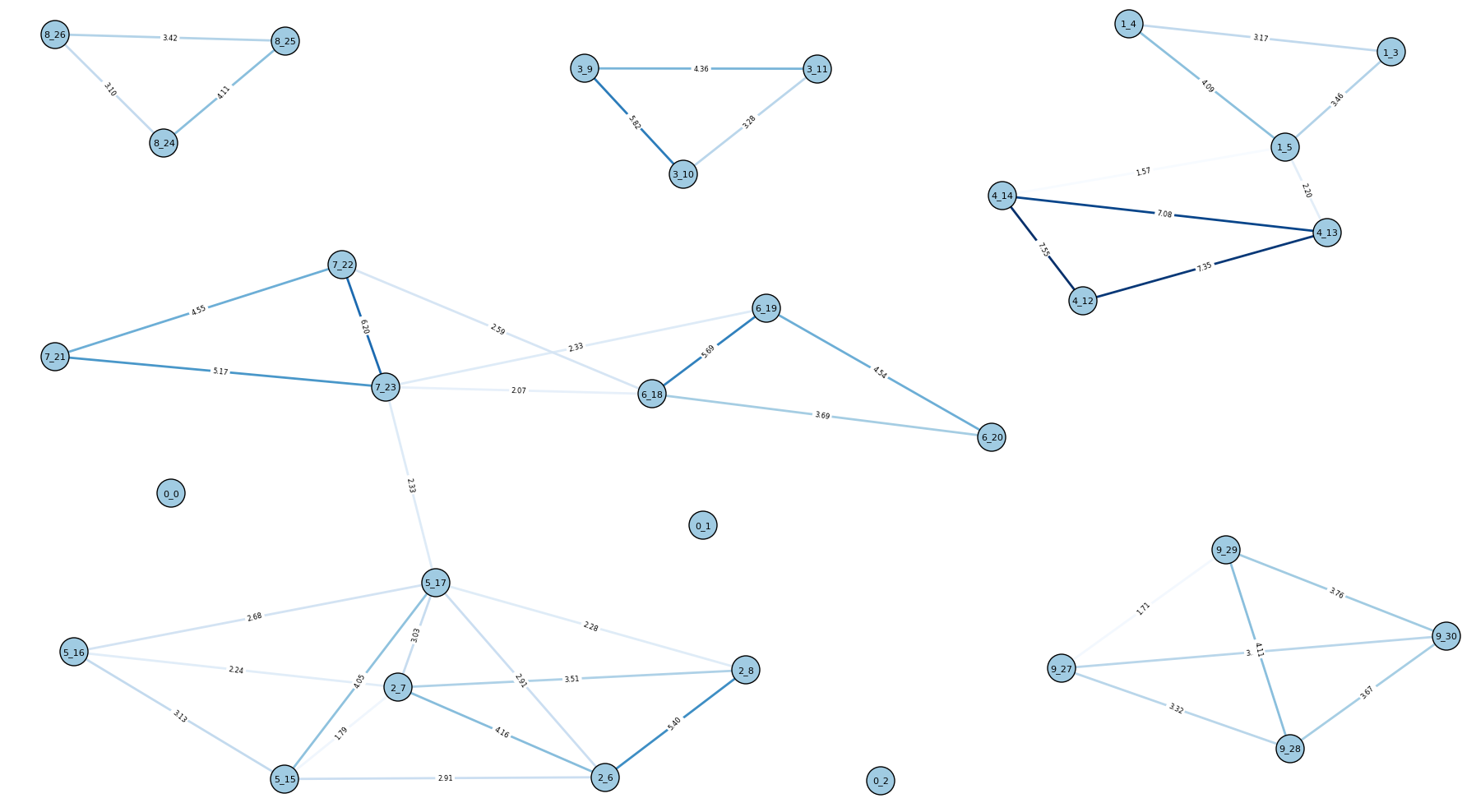
Here is the resulting graph for 10E:
10E
It looks a lot cleaner than before!
Incorporating keywords
A grim observation from the data is that entities may not be enough to fully discern different news events, such as these two events in the 10E dataset:
[2] US soldier arrested for rape and four murders in Iraq
[5] Two Iraqi MPs killed in bombing at parliament
And these two events in the 20E dataset:
[3] Al Jazeera airs new Osama Bin Laden tape
[5] Bin Laden's former driver convicted of supporting terrorism
(Event names are taken from their Wikinews page title)
It seemed that looking at keywords might provide the missing information to disambiguate these events. So for each article I applied a few keyword extraction algorithms followed by the same approach that was used for entities: use the length-weighted sum of the IDF-weighted keyword intersections.
The final similarity score is then just the sum of this keyword score and the entity score from before.
The results for 10E are actually hurt a bit by this, but improved slightly for 20E and 30E:
Completeness
Homogeneity
10E
0.9051290086
0.9527683893
20E
0.8574072716
0.9888333740
30E
0.8414058524
0.9704378548
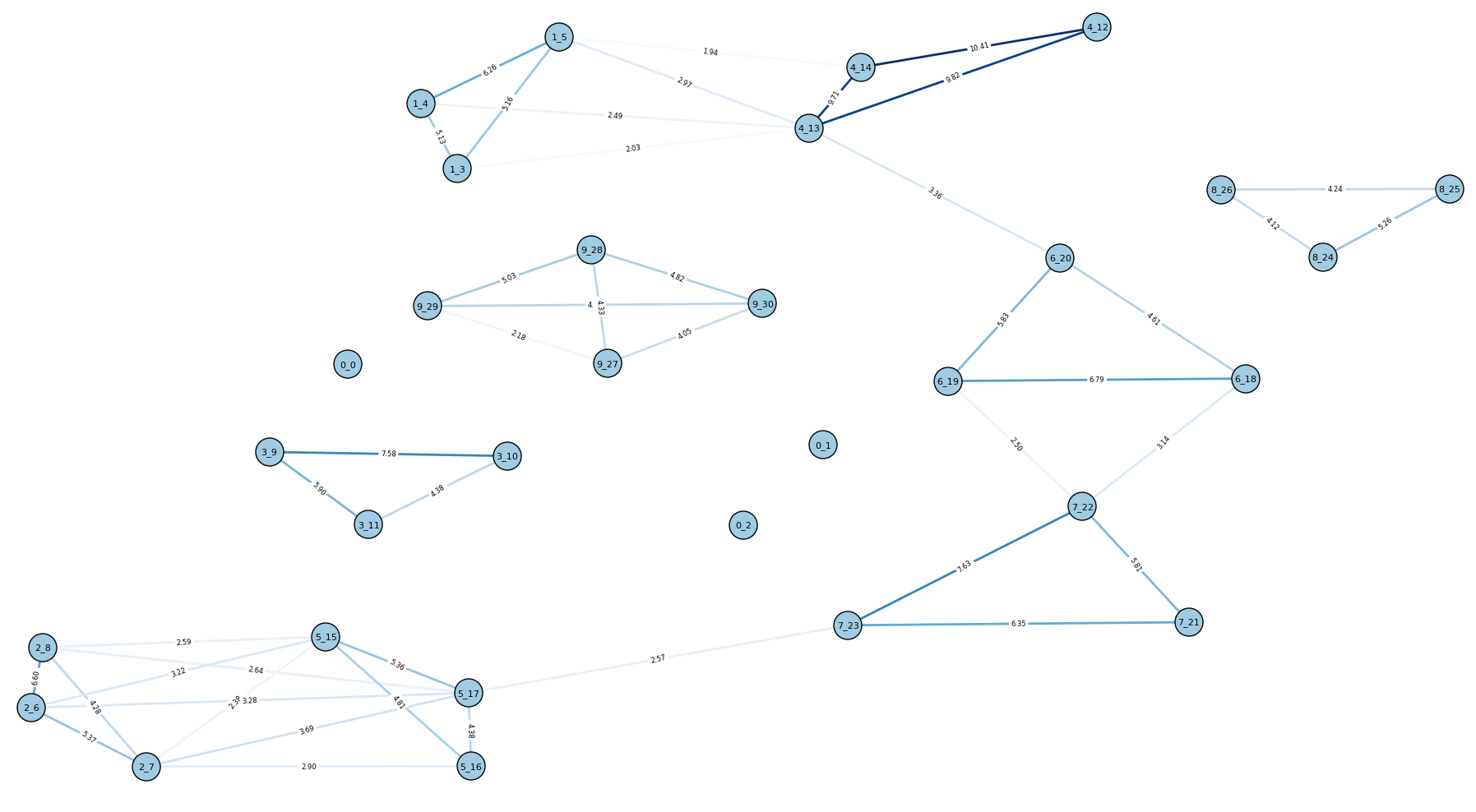
If we look at the graph for 10E, it’s clear why the results were worse:
10E
More noise (i.e. unwanted edges) have been introduced, as you might expect.
For now, I’ve left the keyword intersection in, but it may require some additional processing to eliminate noisy terms.
Next steps
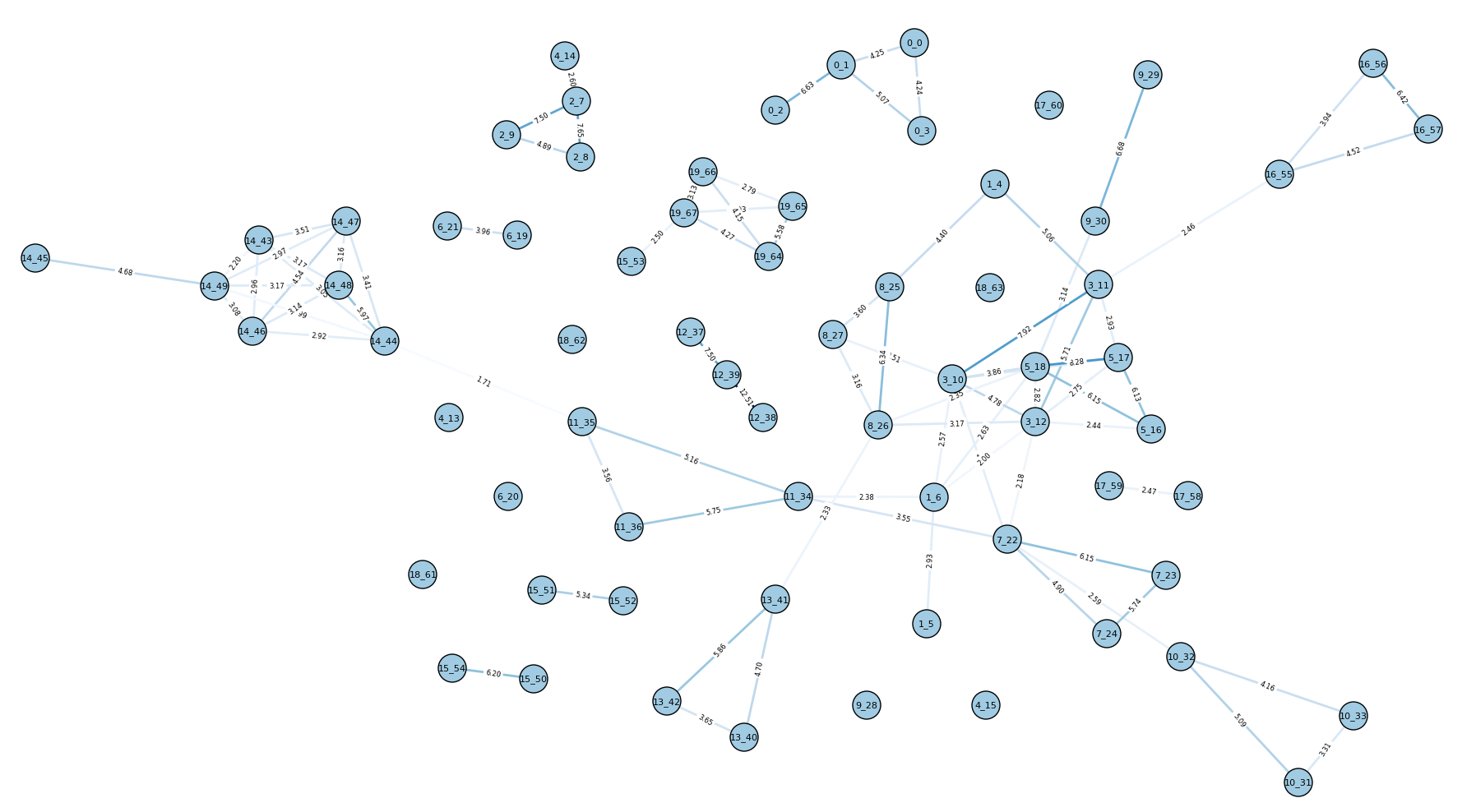
hs_cluster can overshoot the true number of events by quite a bit, but this is because it is still very conservative in how it connects articles together for now. Finding so many extra clusters (i.e. lower completeness) indicates missing edges (this is clear in the graph for the 20E dataset, below), so edge formation needs more investigation: is it a problem of outlier detection? Is it a problem of computing document similarity?
20E
It’s also unclear how hs_cluster will perform on larger document sets. The 30E dataset includes 103 documents and takes 11-12 seconds. This grows exponentially with the graph size. I have not looked deeply into clique-finding algorithms, but a quick look shows that the Bron-Kerbosch algorithm is an efficient way of identifying cliques.
Overall, the results are encouraging. There’s still room for improvement, but it seems like a promising direction.
Source
Source code for the project is available at https://github.com/frnsys/hscluster. The IDF models are not included there; if you are interested, please get in touch - I’m on Twitter as @frnsys.