At this year’s OpenNews Code Convening, Alex Spangher of the New York Times and I worked on broca, which is a Python library for rapidly experimenting with new NLP approaches.
Conventional NLP methods - bag-of-words vector space representations of documents, for example - generally work well, but sometimes not well enough, or worse yet, not well at all. At that point, you might want to try out a lot of different methods that aren’t available in popular NLP libraries.
Prior to the Code Convening, broca was little more than a hodgepodge of algorithms I’d implemented for various projects. During the Convening, we restructured the library, added some examples and tests, and implemented in the key piece of broca: pipelines.
Pipelines
The core of broca is organized around pipes, which take some input and produce some output, which are then chained into pipelines.
Pipes represent different stages of an NLP process - for instance, your first stage may involve preprocessing or cleaning up the document, the next may be vectorizing it, and so on.
In broca, this would look like:
frombroca.pipelineimportPipelinefrombroca.preprocessimportCleanerfrombroca.vectorizeimportBoWdocs=[# ...# some string documents# ...]pipeline=Pipeline(Cleaner(),BoW())vectors=pipeline(docs)
Since a key part of broca is rapid prototyping, it makes it very easy to simultaneously try different pipelines which may vary in only a few components:
This would produce a multi-pipeline consisting of two pipelines: one which vectorizes using BoW, the other using DCS.
Multi-pipelines often have shared components. In the example above, Cleaner() is in both pipelines. To avoid redundant processing, a key part of broca’s pipelines is that the output for each pipe is “frozen” to disk.
These frozen outputs are identified by a hash derived from the input data and other factors. If frozen output exists for a pipe and its input, that frozen output is “defrosted” and returned, saving unnecessary processing time.
broca’s Cryo
This way, you can tweak different components of the pipeline without worrying about needing to re-compute a lot of data. Only the parts that have changed will be re-computed.
Included pipes
broca includes a few pipes:
broca.tokenize includes various tokenization methods, using lemmas and a few different keyword extractors.
broca.vectorize includes a traditional bag-of-words vectorizer, an implementation of “dismabiguated core semantics”, and Doc2Vec.
broca.preprocess includes common preprocessors - cleaning punctuation, HTML, and a few others.
Other tools
Not everything in broca is a pipe. Also included are:
broca.similarity includes similarity methods for terms and documents.
broca.distance includes string distance methods (this may be renamed later).
broca.knowledge includes some tools for dealing with external knowledge sources (e.g. other corpora or Wikipedia).
Though at some point these may also become pipes.
Give us your pipes!
We made it really easy to implement your own pipes. Just inherit from the Pipe class, specify the class’s input and output types, and implement the __call__ method (that’s what’s called for each pipe).
For example:
frombroca.pipelineimportPipeclassMyPipe(Pipe):input=Pipe.type.docsoutput=Pipe.type.vecsdef__init__(self,some_param):self.some_param=some_paramdef__call__(self,docs):# do something with docs to get vectorsvecs=make_vecs_func(docs,self.some_param)returnvecs
We hope that others will implement their own pipes and submit them as pull requests - it would be great if broca becomes a repository of sundry NLP methods which makes it super easy to quickly try a battery of techniques on a problem.
I’ve long been fascinated with the potential for technology to liberate people from things people would rather not be doing. This relationship between human and machine almost invariably manifests in the context of production processes - making this procedure a bit more efficient here, streamlining this process a bit there.
But what about social processes? A hallmark of the internet today is the utter ugliness that’s possible of people; a seemingly inescapable blemish on the grand visions of the internet’s potential for social transformation. And the internet’s opening of the floodgates has had the expected effect of information everywhere, though perhaps in volumes greater than anyone anticipated.
Here we are, trying to engage little tyrants at considerable emotional expense. Here we are, futilely chipping away at the info-deluge we’re suspended in. Here we are, both these things gradually chipping away at us. Things people would rather not be doing.
Blocker
Prior to my fellowship, these kinds of inquiries had to be relegated to off-hours skunkworks. The fellowship has given me the rare privilege of autonomy, both financial and temporal, and the resources, especially of the human kind, with which I can actually explore these questions as my job.
With the Coral Project, I’m researching what makes digital communities tick, surveying the problems with which they grapple, and learning about how different groups are approaching them - from video games to journalism to social networks both in the mainstream and the fringes (you can read my notes here). Soon we’ll be building software to address these issues.
A huge part of the fellowship is learning, which is something I love but have had to carve out my own time for. Here, it’s part of the package. I’ve had ample opportunity to really dig into the sprawling landscape of machine learning and AI (my in-progress notes are here), something I’ve long wanted to do but never had the space for.
The applications for the 2016 fellowship are open, and I encourage you to apply. Rub shoulders with fantastic and talented folks from a variety of backgrounds. Pursue the questions that conventional employment prohibits you from. Explore topics and skills you’ve never had time for. It’s really what you make of it. At the very least, it’s a unique opportunity to be deliberate about where your work takes you.
The halfway mark of my OpenNews fellowship has just about passed. I knew from the start the time would pass by quickly, but I hadn’t considered how much could happen in this short a time. There are only about 5 months left - the fellowship does end, but, fortunately, the work it inaugurates doesn’t have to.
A couple months ago I thought it would be interesting to see if a summary could be generated for a comment section. As a comment section grows, the comments become more repetitive as more people pile into make the same point. It also seems that some natural clustering forms as some commenters focus on particular aspects of an article or topic.
When there are hundreds to thousands of comments, there is little to be gained by reading all of them. However, it may be useful to quantify how much support certain opinions have, or what is most salient about a particular topic. What if there we had some automated means of presenting us such insight? For example, for an article about a new coal industry regulation: 27 comments are focused on how this regulation affects jobs, 39 are arguing about the environmental impacts, 6 are mentioning the meaning of this regulation in an international context, etc.
Having such insight can serve a number of purposes:
Provide a quick understanding of the salient points for readers of an article
Direct focus for future articles on the topic
Give a quick view into how people are responding to an article
Provide fodder for follow-up pieces on how people are responding
Surface entry points for other readers into the conversation
Geiger is still very much a work in progress and has led to a lot of experimentation, some of which worked ok, some of which didn’t work at all, but so far nothing has worked as well as I’d like.
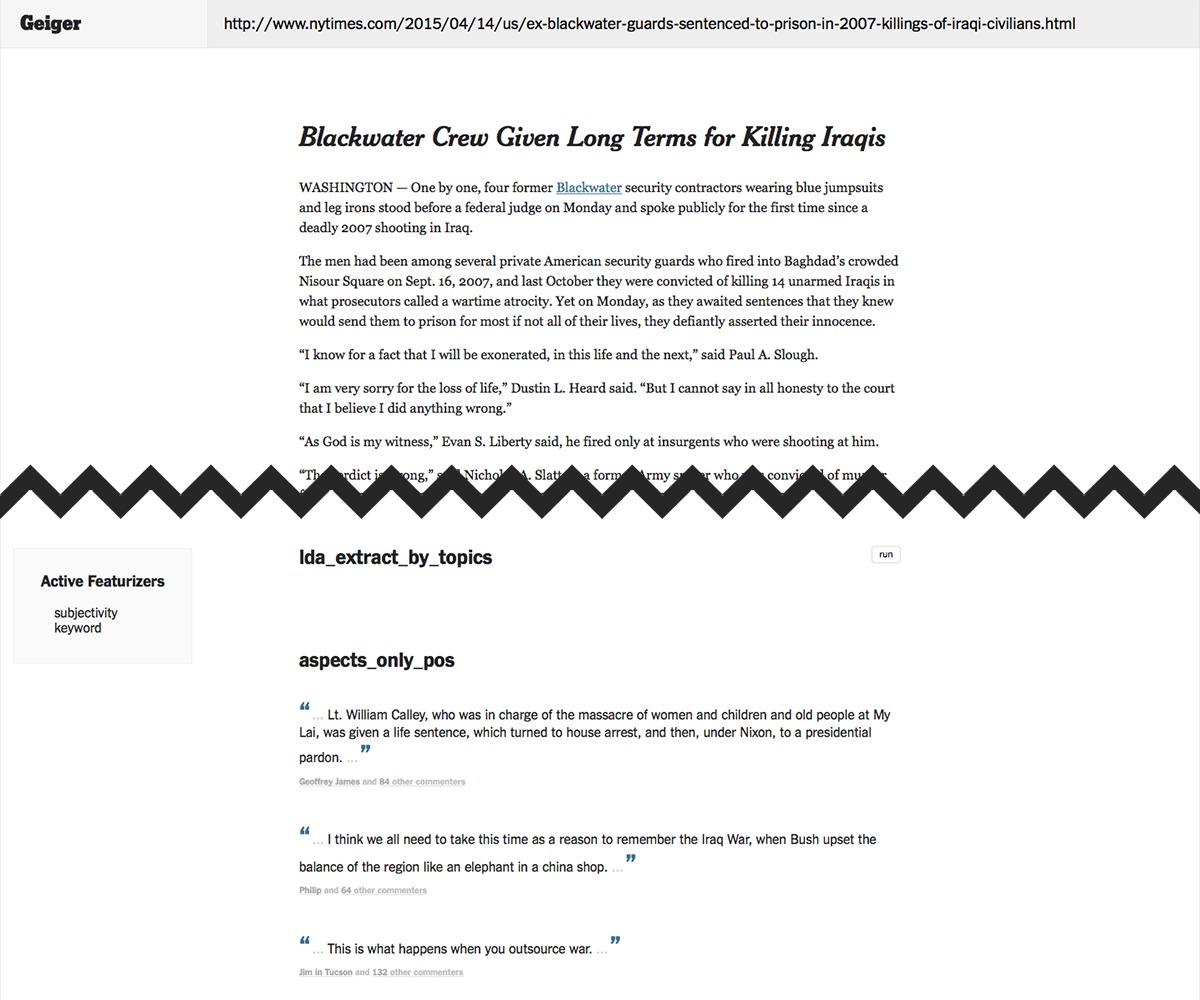
Below is a screenshot from an early prototype of Geiger which allowed me to try a battery of common techniques (TF-IDF bag of words with DBSCAN, K-Means, HAC, and LDA) and compare their results on any New York Times article with comments.
An early Geiger prototype
None of those led to particularly promising results, but a few alternatives were available.
Aspect summarization
This problem of clustering-to-summarize comments is similar to aspect summarization, which is more closely associated with ratings and reviews. For instance, you may have seen how Yelp’s business pages have a few sentences selected at the top, with some term (the “aspect”) highlighted, and then the number of reviewers that mentioned this term. That’s aspect summarization - the aggregate reviews are being summarized by highlighting aspects which are mentioned the most.
Yelp’s aspect summarization
Sometimes aspect summarization includes an additional layer of sentiment analysis, so that instead of just quantifying the number of people talking about an aspect, whether they are talking positively or negatively can also be surfaced (Yelp isn’t doing this, however).
The process of aspect summarization can be broken down into three steps:
Identify aspects
Group documents by aspect
Rank aspect groups
To identify aspects I used a few keyword extraction approaches (PoS tagging for noun phrases, named entity recognition, and other methods like Rapid Automatic Keyword Extraction) and then learned phrases by looking at keyword co-occurrences. If two keywords are adjacent (or separated by only a conjunction or hyphen) in at least 80% in the documents where they are present, we consider it a key phrase.
This simple co-occurrence approach is surprisingly effective. Here are some phrases learned on a set of comments for the coal industry regulation article:
Some additional processing steps were performed, such as removing keywords that were totally subsumed by key phrases; that is, keywords which only ever appear as part of a key phrase. Keywords were also stemmed and merged, e.g. “polluter”, “pollute”, “pollutant”, “pollution” are grouped as a single aspect.
Grouping documents by aspects is straightforward (just look at overlaps). For this task I treated individual sentences as the documents, much like Yelp does.
Ranking them is a bit trickier. I used a combination of token length (assuming that phrases are more interesting than single keywords), support (number of sentences which mention the aspect), and IDF weighting of the aspect. The latter is useful because, for instance, we expect many comments will mention the “coal industry” if the article is about the coal industry, rendering it uninformative.
Although you get a bit of insight into what commenters are discussing, the results of this approach aren’t very interesting. We don’t really get any summary of what people are saying about an aspect. This is problematic when commenters are talking about an aspect in different ways. For instance, many commenters are talking about “climate change”, but some ask whether or not the proposed regulation would be effective in mitigating it, whereas others debate whether or not climate change is a legitimate concern.
Finally, one problem here, which is consistent across all methods, is that this method is ignorant of synonymy - it cannot recognize when two words which look different mean essentially the same thing. For instance, colloquially people use “climate change” and “global warming” interchangeably, but here they are treated as two different aspects. This is a consequence of text similarity approaches which rely on matching the surface form of words - that is, which only look at exact term overlap.
This is especially challenging when dealing with short text documents, which I explain in greater length here.
Word2Vec word embeddings
There has been a lot of excitement around neural networks, and rightly so - their ability to learn representations is very useful. Word2Vec is capable of learning vector representations of words (“word embeddings”) which allow us to capture some degree of semantic quality in vector space. For example, we could say that two words are semantically similar if their word embeddings are close to each other in vector space.
I loaded up Google’s pre-trained Word2Vec model (trained on 100 billion words from a Google News dataset) and tested it out a bit. It seemed promising:
I made some attempts at approaches which leaned on this Word2Vec similarity of terms rather than their exact overlap - when comparing two documents A and B, each term from A is matched to is maximally-similar term in B and vice versa. Then the documents’ similarity score is computed from these pairs’ similarity values, weighted by their average IDF.
A problem with using Word2Vec word embeddings is that they are not really meant to quantify synonymy. Words that have embeddings close together do not necessarily mean similar things, all that it means is that they are exchangeable in some way. For example:
The terms “good” and “bad” are definitely not synonyms, but they serve the same function (indicating quality or moral judgement) and so we expect to find them in similar contexts.
Because of this, Word2Vec ends up introducing more noise on occasion.
Measuring salience
Another angle I spent some time on was coming up with some better way of computing term “salience” - how interesting a term is. IDF is a good place to start, since a reasonable definition of a salient term is one that doesn’t appear in every document, nor does it only appear in one or two documents. We want something more in the middle, since that indicates a term that commenters are congregating around.
Thus middle IDF values should be weighted higher than those closer to 0 or 1 (assuming these values are normalized to ¦[0,1]¦). To capture this, I put terms’ IDF values through a Gaussian function with its peak at ¦x=0.5¦ and called the resulting value the term’s “salience”. Then, using the Word2Vec approach above, maximal pairs’ similarity scores are weighted by their average salience instead of their average IDF.
The results of this technique look less noisy than before, but there is still ample room for improvement.
Challenges
Working through a variety of approaches has helped clarify what the main difficulties of the problem are:
Short texts lack a lot of helpful context
Recognizing synonymy is tricky
Noise - some terms aren’t very interesting given the article or what other people are saying
What’s next
More recently I have been trying a new clustering approach (hscluster) and exploring ways of better measuring short text similarity. I’m also going to take a deeper look into topic modeling methods, which I don’t have a good grasp on yet but seem promising.
My favorite album of all time is The Avalanches’ Since I Left You. It’s a masterpiece of “plunderphonics”, which essentially means “sound collage”; that is, constructing songs purely out of broadly sourced samples. Since the album came out 15 years ago (!!), there has been promise of a second release. This release has yet to materialize.
In this endless interim I wrote Pablo (named after Pablo’s Cruise, which is a song on Since I Left You and was the album’s original title), a program for automatically generating plunderphonic music. It’s output is certainly nothing of Avalanches’ caliber, but it’s meant more for rapidly sketching ideas than for generating fully-fleshed tracks.
The GitHub repo for Pablo has instructions for installation. Here I’ll talk a bit more about how it works.
Selecting and preprocessing the songs
Song selection
The approach is pretty simple - you direct Pablo to a directory of music (mp3s or wavs) and it will start analyzing the tracks, approximating their BPMs and keys for later reference. Almost all of Pablo’s audio analysis capabilites rely directly on the Essentia library.
Pablo then randomly picks a “focal” song - the song the rest of the mix is based off of. Pablo goes through the other songs available in the directory and randomly chooses a few that are within a reasonable distance from the focal song in both key and BPM (to avoid ridiculous warping, although maybe you want that to happen).
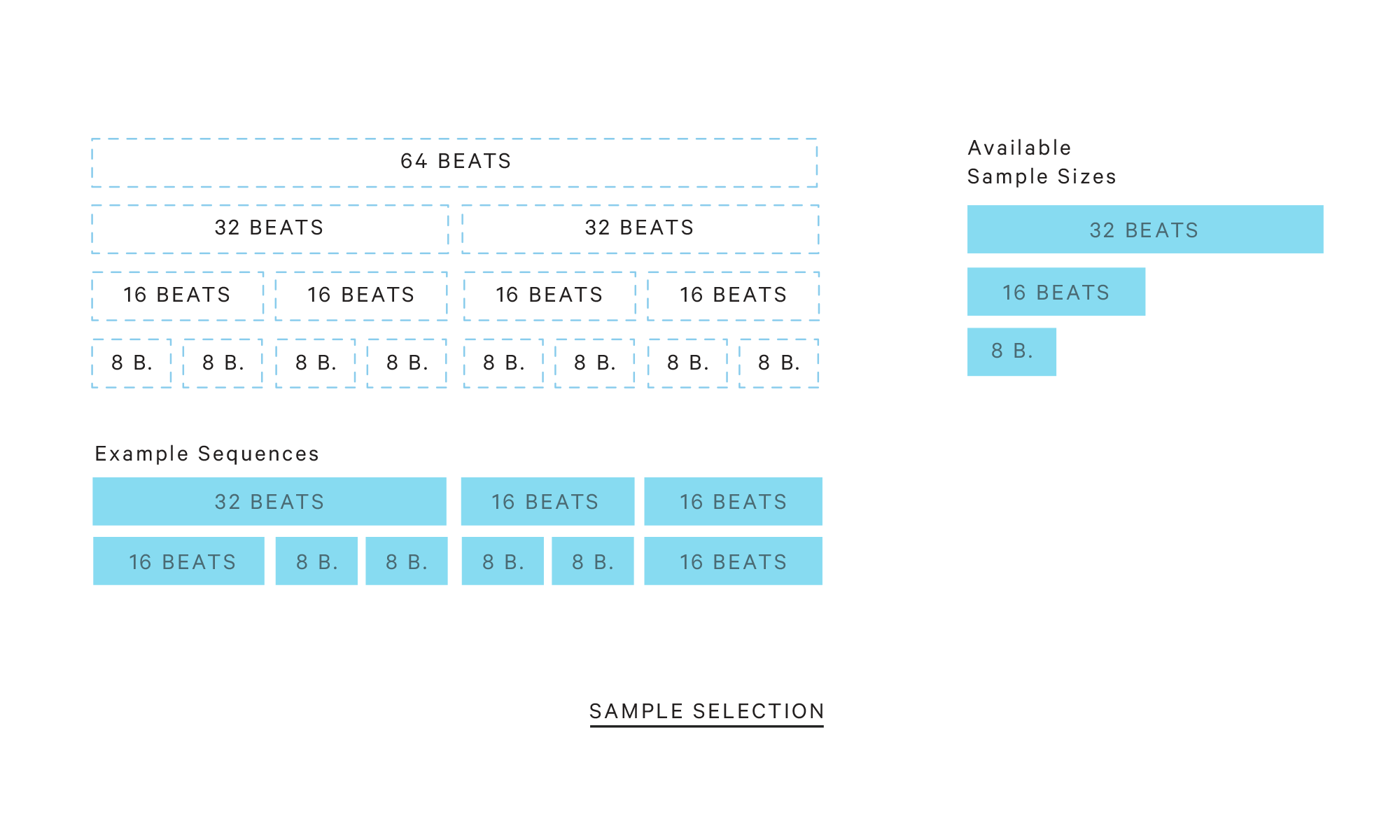
These other songs are pitch-shifted and time-stretched to conform to the focal song. Then, in each track, beat onset detection happens to identify downbeats. These downbeats are used to slice the tracks into samples of different sizes (the sizes must be a power of 2, e.g. 4, 8, 16, 32, etc). By default these samples are 16 beats and 32-beats.
A challenge here was beatmatching. For the most part, Pablo does pretty well at identifying proper beat onsets. But some samples become irregular - if there is an instrumental bridge, for instance, or a long intro, then Pablo may not cut that part into properly-sized samples. So there is an additional step where Pablo finds the mode sample duration (in milliseconds) and discards all samples not of this length. That way we have greater assurance that when the samples are finally assembled into tracks, they will align properly (since all samples of the same beat length will have the exact same time duration).
Assembling the mix
With all the samples preprocessed, Pablo can begin putting the tracks together. To do so, Pablo just places samples one after the another using the stochastic process outlined below.
A song length is specified in beats, which also must be a power of 2. For instance, we may want a song that is 64-beats long. Pablo then recursively goes down by powers of 2 and tries to “fill in” these beats.
For example, say we want a 64-beat long song and we have a samples of size 32, 16, and 8. Pablo first checks to see if a 64-beat sample is available. One isn’t, so then it knows it needs two 32-beat samples (i.e. we have two 32-beat slots to fill). A 32-beat sample is available, so for each 32-beat slot Pablo randomly decides whether or not to use a complete 32-beat sample or to further split that slot into two 16-beat slots. If Pablo chooses the latter, the same process is again applied until the smallest sample size is reached. So in this example, Pablo would stop at two 8-beat slots since it does not have any samples smaller than 8 beats.
Selecting samples
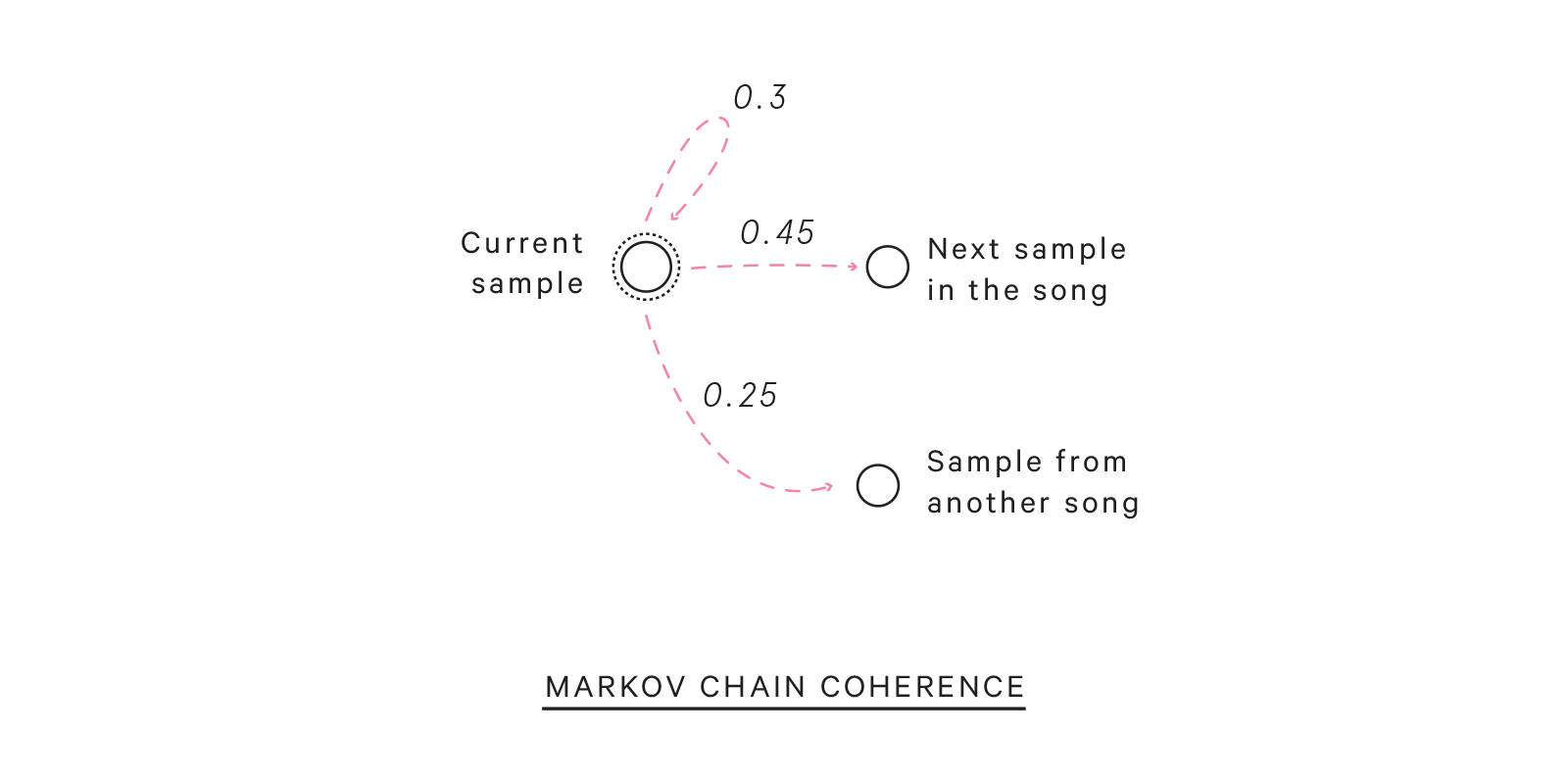
Pablo also has some heuristics to ensure a degree of coherence in the tracks it creates. Without this, Pablo’s tracks would be too spastic, with sudden cutoffs and changes in samples every bar. So to decide what sample should follow the current sample, Pablo uses a simple Markov chain model which favors staying in the same song and favors repeating the same sample.
Markov Chain Coherence
Each track is constructed in this way. Pablo creates (by default) two tracks which are then overlaid to form the final mix. However, sometimes samples from the same song are overlaid each other, which isn’t quite what I wanted, so one final heuristic is implemented. When constructing tracks after the first, Pablo will try its best to avoid placing samples from the same song over each other. Sometimes this is unavoidable, such as when there are more tracks being made than there are songs. But for the most part it works out.
That’s really about it in terms of generating the songs. I’ve also been playing a bit with vocal detection, since hearing multiple people singing can be disorienting, and I would like to add in some genre-identification features as well.
The Infinite Playlist
One final feature is the “crate digging” feature, in which Pablo takes a seed YouTube url and crawls its related videos, quickly amassing some songs to sample. Eventually I’d like it so that Pablo can become the infinite playlist, crawling YouTube (and perhaps SoundCloud and other sources) and endlessly mixing songs into each other.
An example song
Here’s a song that Pablo produced:
It’s a bit hectic, but for the most part beats match well and there are some interesting moments in there. Pablo outputs sample listings with times, along with the original samples, so it’s easy to recreate the parts that you like.
Source
You can check out how all this is implemented in the GitHub repo, along with installation instructions to run Pablo yourself!
Bots coast on the credentials of the real users of the computers they hijack. Bots were observed to click more often (but not improbably more often) than real people. Sophisticated bots moved the mouse, making sure to move the cursor over ads. Bots put items in shopping carts and visited many sites to generate histories and cookies to appear more demographically appealing to advertisers and publishers. - The Bot Baseline: Fraud in Digital Advertising. December 2014. White Ops, Inc. and the Association of National Advertisers.
The study cited above looked at 5.5 billion ad impressions over 60 days across 36 organizations. 23 percent of all observed video impressions were bots (p16).
Like too many things in our world, most useful internet services must justify themselves financially. The business model of much of the internet is based on advertising, and that whole schema is based on the assumption that advertising increases consumption. The further assumption there is that the subjects viewing the advertisements both can be influenced by ads and have the capacity to make purchases - that is, that they’re human.
These behaviors are easily simulated, up to the point of purchase - although perhaps it makes economic sense for a bot to occasionally make a purchase in order to maintain the broader illusion of human engagement. There’s something here about the dissolving of the internet human subject but I can’t quite put my finger on it.
These bots are deployed by fraudsters to increase revenue, but since the purpose of automation is for outsourcing things we’d rather not do ourselves, maybe we regular folks can have bots simulating our own advertising engagement.
It’s worth flipping through the report, if only for this title: